- Оценка производительности 1С + Postgres Pro при изменении различных параметров конфигурационного файла postgresql.conf
- Состав тестового стенда
- Общая методика тестирования
- Подготовка тестового стенда
- Настройка Postgres
- Результаты тестирования
- 1С и Linux
- понедельник, 25 марта 2019 г.
- Тест 1С и PostgreSQL Windows vs PostgreSQL Linux
Оценка производительности 1С + Postgres Pro при изменении различных параметров конфигурационного файла postgresql.conf
Прошлый 2022 год заставил много компаний пересмотреть свои предпочтения в выборе программного обеспечения. Все чаще встречаются кейсы, когда для работы 1С используется СУБД PostgreSQL, а вместо Windows Server используется Linux ОС.
Целью данной статьи является изучение в 2023 году производительности системы 1С в среде Hyper-V (ОС Windows Server 2019) во взаимодействии с сервером СУБД PostgreSQL Standart 13.9 (ОС Debian 11.5) от команды PostgresPro. В материале мы описываем исследование зависимости параметров конфигурационного файла, результаты замеров производительности при изменении данных параметров.
Состав тестового стенда
Аппаратная часть
- Supermicro X11DPL‑i*
- 2 x Intel Xeon X 5690 3,4 GHz, each 6 Core **
- ОЗУ 128 ГБ DDR3
- Хранилище RAID 1, Intel DC S3710 SSDSC2BA400G401 400 ГБ
*Исследование проводим на проверенной временем аппаратной платформе Supermicro от 2011 года.
**При использовании платформы Intel Gold в связке с скоростными дисками, большинство исследуемых параметров осталось в рамках погрешности. Не удалось сгенерировать нагрузку, чтобы заметить тенденцию к существенному изменению показателей.
Программная часть
- Платформа 1С:Предприятие 8.3.22.1750.
- Конфигурации: 1С:ERP Управление предприятием 2. Демо база. Тест «Полный» на 33 пользователя. Редакция 2.5.8.179. Объем базы 4.2 ГБ.
- Сервер приложений 1С: ОС Windows Server 2019 Standard.
- Сервер базы данных: ОС Debian 11.5, Postgres pro Standart 13.9.
Примечание: В рамках тестирования мы используем стандартный шаблон от фирмы 1С – полный, 33 пользователя. Безусловно, используемое железо сможет вытянуть и больше испытуемых. Наша цель отследить тенденцию, а не нагрузить железо.
Общая методика тестирования
В рамках данной статьи мы применяем методику анализа используя абсолютные значения погрешности:
![]()
- Описание методики определения абсолютной погрешности:
- Определяем идеальные условия испытаний. В нашем случае это два виртуальных сервера с ролью Application сервера 1С на Windows, и сервера баз данных с подготовленной конфигурацией.
- Выполняем по 3 теста APDEX с числом пользователей 33 на PostgreSQL.
- Производим расчет абсолютной погрешности по формуле:
- Основной этап тестирования:
- Проводим замер целевых значений. Проводится 3 замера теста “Полный” в конфигурации ERP.
- Проводим серию основных испытаний (повторяем со всеми исследуемыми значениями). Проводится уменьшение первого исследуемого значения на 100%.
Проводим увеличение первого исследуемого значения на 100%. - Значения в положении on\off активируем или деактивируем соответственно (например, компоненты параллелизма).
Тест 1С:КИП (Апдекс)
В основе методики АПДЕКС лежит набор инструментов 1С:КИП. В данном случае, использовался весь функционал методологии. Использовалась стандартная демонстрационная база 1С:ERP с сайта 1С.
Стандартная методология АПДЕКС использует прогрессивную шкалу от 0 до 1, где 1 – это замечательный результат, а 0 – неудовлетворительный. Требуется указать целевое значение параметра производительности той или иной операции, создать сценарии и запустить тест.
Подготовка тестового стенда
Проводим установку и базовую настройку носителя виртуальных машин и операционных систем.
Носитель виртуальных машин
Перед работой с носителем были произведены твики биоса. В данном случае необходимо было вручную выставить режим “Maximum Perfomance” в расширенных настройках CPU. Данные настройки применены для всех участников тестирования
- Power Technology. Ставим Custom.
- Power Performance Tuning. Здесь нужно выбрать: или управлять питанием будет BIOS или ОС. Наш опыт с Hyper-v говорит о выборе в сторону OS control.
- Energy_perf_bias_cfg mode. Ставим Maximum Performance.
- Настройки электропитания ОС. Ставим производительность.
Результатом наших манипуляций является фиксированная в режиме turbo-boost частота процессора (в нашем случае это 3,46 ГГц ).
Операционные системы и приложения
- Установлена ОС Windows Server 2019 Standard.
- Установлен 1С сервер.
- Режим электропитания — максимальная производительность.
Носитель виртуальных машин:
- Установлена ОС Windows Server 2019 Standard.
- Режим электропитания — максимальная производительность.
Выделяем ресурсы под виртуальные машины:
- Application сервер 1С – 12 ядер ЦП и 40 ГБ ОЗУ.
- SQL сервер – 10 ядер ЦП и 30 ГБ ОЗУ (параметры конфигурации рассчитываем исходя из 20 ГБ ОЗУ для того, чтобы был запас по росту).
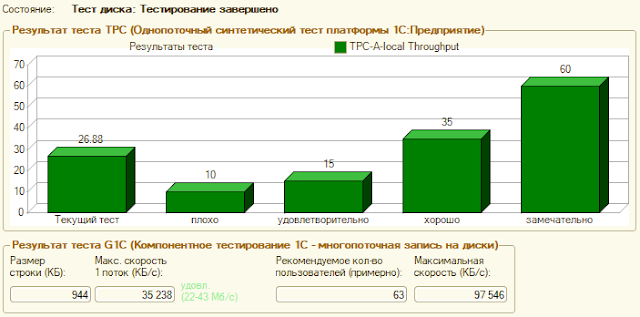
Производим проверку дисковой подсистемы Crystal Disk Mark. Настройки стандартные. Тест файлом 32ГБ:
Настройка Postgres
Подготовка исходного конфига
После оформления заявки на сайте https://1c.postgres.ru/ на нашу почту приходит письмо с командами:
wget https://repo.postgrespro.ru/1c-13/keys/pgpro-repo-add.sh sh pgpro-repo-add.shЕсли продукт единственный Postgres на вашей машине и вы хотите сразу получить готовую к употреблению базу:
apt-get install postgrespro-1c-13Проводим анализ файла postgresql.conf, находящегося по адресу: /var/lib/pgpro/1c-13/data
Большинство строк в нем закомментированы. Часть настроек изменяется при установке и зависит от числа ядер и ОЗУ выделенных на ВМ, это одно из преимуществ продукта.
shared_buffers = 5000MB # 25% of RAM temp_buffers = 128MB work_mem = 256MB maintenance_work_mem = 256MB max_files_per_process = 10000 max_parallel_workers_per_gather = 0 max_parallel_maintenance_workers = 3 # Количество CPU/4, минимум 2, максимум 6 commit_delay = 1000 max_wal_size = 4GB min_wal_size = 2GB checkpoint_timeout = 15min effective_cache_size = 15000MB # 75% of RAM from_collapse_limit = 8 join_collapse_limit = 8 autovacuum_max_workers = 6 # Количество CPU/2, минимум 2 vacuum_cost_limit = 600 # 100* autovacuum_max_workers autovacuum_naptime = 20s autovacuum_vacuum_scale_factor = 0.01 autovacuum_analyze_scale_factor = 0.005 max_locks_per_transaction = 256 escape_string_warning = off standard_conforming_strings = off shared_preload_libraries = 'online_analyze, plantuner' online_analyze.threshold = 50 online_analyze.scale_factor = 0.1 online_analyze.enable = on online_analyze.verbose = off online_analyze.min_interval = 10000 online_analyze.table_type = 'temporary' plantuner.fix_empty_table = on random_page_cost = 1.0 effective_io_concurrency = 1Это и будет наш основной эталонный конфиг для старта тестов.
Исследуемые элементы и этапы тестирования:
- Тест 1,2,3 – определение погрешности стоковых значений
- Тест 4 – random_page_cost = 4.0
- Тест 5 – effective_io_concurrency = 400
- Тест 6 – shared_buffers = 2500MB
- Тест 7 – shared_buffers = 10000MB
- Тест 8 (комплексные значения):
- max_parallel_workers_per_gather = 4
- max_parallel_maintenance_workers = 3 # Количество CPU/4, минимум 2, максимум 6
- max_worker_processes = 10
- max_parallel_workers = 10
Пройдемся кратко по основным значениям:
- shared_buffers = 5GB # 25% of RAM Задаёт объём памяти, который будет использовать сервер баз данных для буферов в разделяемой памяти. Согласно рекомендации команды Postgres pro, рекомендуемое значение: 25% от ОЗУ сервера SQL.
- temp_buffers = 128MB Задает максимальный объем памяти, выделяемой для временных буферов в каждом сеансе. Эти, существующие только в рамках сеанса буферы, используются исключительно для работы с временными таблицами.
- work_mem = 256MB Задает базовый максимальный объём памяти, который будет использоваться во внутренних операциях при обработке запросов (например, для сортировки или хеш-таблиц), прежде чем будут задействованы временные файлы на диске.
- maintenance_work_mem = 256MB Задает максимальный объем памяти для операций обслуживания БД, в частности VACUUM, CREATE INDEX и ALTER TABLE ADD FOREIGN KEY.
- max_parallel_workers_per_gather = 0 Количество воркеров, которые запускаются на узел. Это основополагающая настройка, если вы ее выставите в ноль, параллелизм не будет отрабатывать, будет работать один процесс, один оператор. Когда оптимизатор запросов принимает решение, что для запроса нужно применять параллелизм, он смотрит на этот параметр и определяет, сколько ему нужно воркеров, чтобы выполнить этот оператор запроса.
- max_parallel_maintenance_workers = 3 # Количество CPU/4, минимум 2, максимум 6 Задаёт максимальное число рабочих процессов, которые могут запускаться одной служебной командой.
- max_wal_size = 16GB и min_wal_size = 4GB Минимальный и максимальный размер файлов журнала предзаписи.
- effective_cache_size = 15000MB # 75% of RAM Этот параметр влияет на планировщик запросов, а не ограничивает дисковый кэш. Чем выше, тем больше вероятность, что будет применяться сканирование по индексу. Чем ниже, тем более вероятно, что будет выбрано последовательное сканирование.
- random_page_cost = 1.0 Задает приблизительную стоимость чтения одной произвольной страницы с диска. Значение по умолчанию равно 4.0. С хранилищем, у которого стоимость произвольного чтения ненамного выше последовательного, как, например, у твердотельных накопителей, лучше выбрать меньшее значение random_page_cost. Параметр наиболее эффективен, при условии что база полностью помещается в ОЗУ. Сервер SQL не знает какая у нас дисковая подсистема и какое время Seek Time, потому данный параметр необходимо задать вручную в среде Linux. В Windows параметр проставляется автоматически:
- 4.0 – для HDD;
- 1.5-2.0 – для RAID из HDD;
- 1.1 – 1.5 – для SSD;
- 0.1 – 1.0 – для NVMe.
Результаты тестирования
Таблица определения погрешностей:
Название параметров
Значение Апдекс
Среднее значение Апдекс
Относительная погрешность Апдекс
Абсолютная погрешность Апдекс
Тест определения погрешности 1
Тест определения погрешности 2
Тест определения погрешности 3
Таблица результатов тестирования:
Название параметров
Стандартное значение параметров
Измененное значение параметров
Абсолютная разница со средним значением
1С и Linux
Пишу для себя, чтобы не забыть как делал. 95 % рабочее. На комментарии отвечаю, когда увижу.
понедельник, 25 марта 2019 г.
Тест 1С и PostgreSQL Windows vs PostgreSQL Linux
Есть средство виртуализации debian с VirtualBox (kvm)
Поднимем, 2 виртуальные машины:
1. Ubuntu 16.04 32 Gb 4 ядра
Виртуальная машина ubuntu 16.04.5 PostgreSQL версия 10.5-24.1C 1С 8.3.13.1690Тест pgbench
$ sudo su postgres
$ psql -c «CREATE DATABASE example;»
$ pgbench -i -s 500 example
$ pgbench -c 10 -j 10 -t 10000 example
starting vacuum. end.
transaction type:
scaling factor: 500
query mode: simple
number of clients: 10
number of threads: 10
number of transactions per client: 10000
number of transactions actually processed: 100000/100000
latency average = 1.647 ms
tps = 6073.027124 (including connections establishing)
tps = 6078.146705 (excluding connections establishing)Тест расчета зарплаты на 3000 сотрудников (с оптимизацией postgresql.conf):
Заполнить154 с
Провести 127 с
$ cat /proc/cpuinfo | grep MHz
cpu MHz : 3599.998
cpu MHz : 3599.998
cpu MHz : 3599.998
cpu MHz : 3599.998/dev/sda:
Timing cached reads: 34870 MB in 1.98 seconds = 17598.73 MB/sec
Timing buffered disk reads: 1096 MB in 3.00 seconds = 365.07 MB/sec$ free -ht
total used free shared buff/cache available
Память: 31G 2,5G 1,3G 2,5G 27G 25G
Подкачка: 1,0G 7,0M 1,0G
Всего: 32G 2,5G 2,3G> «c:\Program Files\PostgreSQL\10.5-24.1C\bin\psql» -U postgres -c «CREATE DATABASE example»
Password for user postgres:
CREATE DATABASE«c:\Program Files\PostgreSQL\10.5-24.1C\bin\pgbench» -U postgres -i -s 500 example
«c:\Program Files\PostgreSQL\10.5-24.1C\bin\pgbench» -U postgres -c 10 -j 10 -t 10000 example
C:\Users\user>»c:\Program Files\PostgreSQL\10.5-24.1C\bin\pgbench» -U postgres -c 10 -j 10 -t 10000 example
Password:
starting vacuum. end.
transaction type:
scaling factor: 500
query mode: simple
number of clients: 10
number of threads: 10
number of transactions per client: 10000
number of transactions actually processed: 100000/100000
latency average = 2.006 ms
tps = 4984.870590 (including connections establishing)
tps = 5021.018416 (excluding connections establishing)Тест расчета зарплаты на 3000 сотрудников (с оптимизацией postgresql.conf):
Заполнить160 с
Провести 148 сSequential Read (Q= 32,T= 1) : 541.779 MB/s
Sequential Write (Q= 32,T= 1) : 524.051 MB/s
Random Read 4KiB (Q= 8,T= 8) : 277.270 MB/s [ 67692.9 IOPS]
Random Write 4KiB (Q= 8,T= 8) : 252.523 MB/s [ 61651.1 IOPS]
Random Read 4KiB (Q= 32,T= 1) : 188.719 MB/s [ 46074.0 IOPS]
Random Write 4KiB (Q= 32,T= 1) : 153.639 MB/s [ 37509.5 IOPS]
Random Read 4KiB (Q= 1,T= 1) : 22.986 MB/s [ 5611.8 IOPS]
Random Write 4KiB (Q= 1,T= 1) : 59.959 MB/s [ 14638.4 IOPS]Test : 1024 MiB [C: 5.4% (53.8/999.5 GiB)] (x5) [Interval=5 sec]
Date : 2019/03/25 18:36:32
OS : Windows 10 Professional [10.0 Build 16299] (x64)