Алгоритмы борьбы с перегрузкой
Когда количество пакетов, передаваемых одновременно по подсети (или ее части), превышает некий пороговый уровень, производительность сети начинает снижаться.
Такая ситуация называется перегрузкой. График на рис. 5.23 изображает симптомы этого явления. Когда число пакетов, посылаемых хостами в сеть, не превышает ее пропускной способности, все они доставляются адресатам (кроме небольшого процента поврежденных ошибками передачи). При этом количество доставленных пакетов пропорционально количеству посланных. Однако по мере роста трафика маршрутизаторы перестают успевать обрабатывать все пакеты и начинают их терять. При дальнейшем увеличении числа отправляемых пакетов ситуация продолжает ухудшаться. Когда число пакетов достигает максимального уровня, производительность сети начинает снижаться. При очень высоком уровне трафика производительность сети падает до совсем низкого уровня и практически никакие пакеты не доставляются.
Перегрузка может быть вызвана несколькими факторами.
Если вдруг потоки пакетов начинают прибывать на маршрутизатор сразу по трем или четырем входным линиям и всем им нужна одна и та же выходная линия, то образуется очередь. Когда у маршрутизатора закончится свободная память для буферизации всех прибывающих пакетов, их негде будет сохранять и они начнут теряться. Увеличение объема памяти маршрутизаторов может в какой-то степени помочь, но Нэгл (Nagle) в 1987 году показал, что даже если у маршрутизаторов будет бесконечное количество памяти, ситуация с перегрузкой не улучшится, а, наоборот, ухудшится, так как к тому времени, когда пакеты доберутся до начала очереди, они уже запоздают настолько, что источником будут высланы их дубликаты.
Все эти пакеты будут посланы следующему маршрутизатору, еще более увеличивая нагрузку на всем протяжении маршрута к получателю.
Медленные процессоры также могут служить причиной заторов. Если центральные процессоры маршрутизаторов слишком медленно выполняют свои задачи, связанные с учетом, управлением очередями, обновлением таблиц и т. д., то очереди будут появляться даже при достаточно высокой пропускной способности линий. Аналогично, линии с низкой пропускной способностью также могут вызывать заторы в сети. Если заменить линии более совершенными, но оставить старые процессоры, или наоборот, такие действия обычно немного помогают, но часто просто приводят к сдвигу узкого места, вызванного несоответствием производительности разных частей системы. Проблема узкого места сохраняется до тех пор, пока компоненты системы не будут должным образом сбалансированы.
Необходимо пояснить, в чем состоит разница между борьбой с перегрузкой и управлением потоком. Предотвращение перегрузки гарантирует, что подсеть справится с предлагаемым ей трафиком. Это глобальный вопрос, включающий поведение всех хостов и маршрутизаторов, процессов хранения и пересылки на маршрутизаторах, а также множество других факторов, снижающих пропускную способность подсети.
Управление потоком, напротив, относится к трафику между двумя конкретными станциями — отправителем и получателем. Задача управления потоком срстоит в согласовании скорости передачи отправителя со скоростью, с которой получатель способен принимать поток пакетов. Управление потоком обычно реализуется при помощи обратной связи между получателем и отправителем.
Чтобы разница между этими двумя проблемами стала яснее, представьте себе оптоволоконную сеть с пропускной способностью 1000 Гбит/с, по которой суперкомпьютер пытается передать персональному компьютеру файл со скоростью 1 Гбит/с. Хотя перегрузки сети в данной ситуации не наблюдается, алгоритм управления потоком довольно часто заставляет суперкомпьютер приостанавливать передачу, чтобы персональный компьютер мог успевать принимать файл.
А вот другой пример. Рассмотрим сеть с промежуточным хранением, состоящую из 1000 больших компьютеров, соединенных линиями с пропускной способностью 1 Мбит/с. Одна половина компьютеров пытается передавать файлы Другой половине со скоростью 100 Кбит/с. Здесь проблема заключается уже не в том, что медленные получатели не успевают принимать данные, посылаемые им быстрыми отправителями, а просто в неспособности сети пропустить весь предлагаемый трафик.
Причина, по которой управление потоком и борьбу с перегрузкой часто путают, заключается в том, что алгоритмы борьбы с перегрузкой также используют обратную связь в виде специальных сообщений, посылаемых различным отправителям, с просьбой передавать данные помедленнее, когда в сети появляются заторы. Таким образом, хост может получить просьбу замедлить передачу в двух случаях: когда с передаваемым потоком не справляется получатель или когда с ним не справляется вся сеть. В дальнейшем мы еще будем рассматривать этот вопрос.
Мы начнем изучение алгоритмов борьбы с перегрузкой с рассмотрения общей модели. Затем мы познакомимся с общим подходом к предотвращению перегрузки, а также с различными динамическими алгоритмами борьбы с перегрузкой, которую не удалось предотвратить.
16.2.Борьба с перегрузками
В классическом полудуплексном режиме у коммутатора имеется возможность воздействовать на конечный узел с помощью алгоритма доступа к среде, который соседний узел обязан отрабатывать. Применяются два основных способа управления потоком кадров — обратное давление на конечный узел и агрессивный захват среды.
Метод обратного давления (backpressure) состоит в создании искусственных коллизий в сегменте, который чересчур интенсивно посылает кадры в коммутатор. Для этого коммутатор обычно использует jam-последовательность, отправляемую на выход порта, к которому подключен сегмент (или узел), чтобы приостановить его активность.
Другой метод «торможения» обычно применяется в том случае, когда соседом является конечный узел. Метод основан на так называемом агрессивном захвате среды либо после окончания передачи очередного кадра, либо после коллизии. Эти два случая иллюстрирует рис. 16.2.
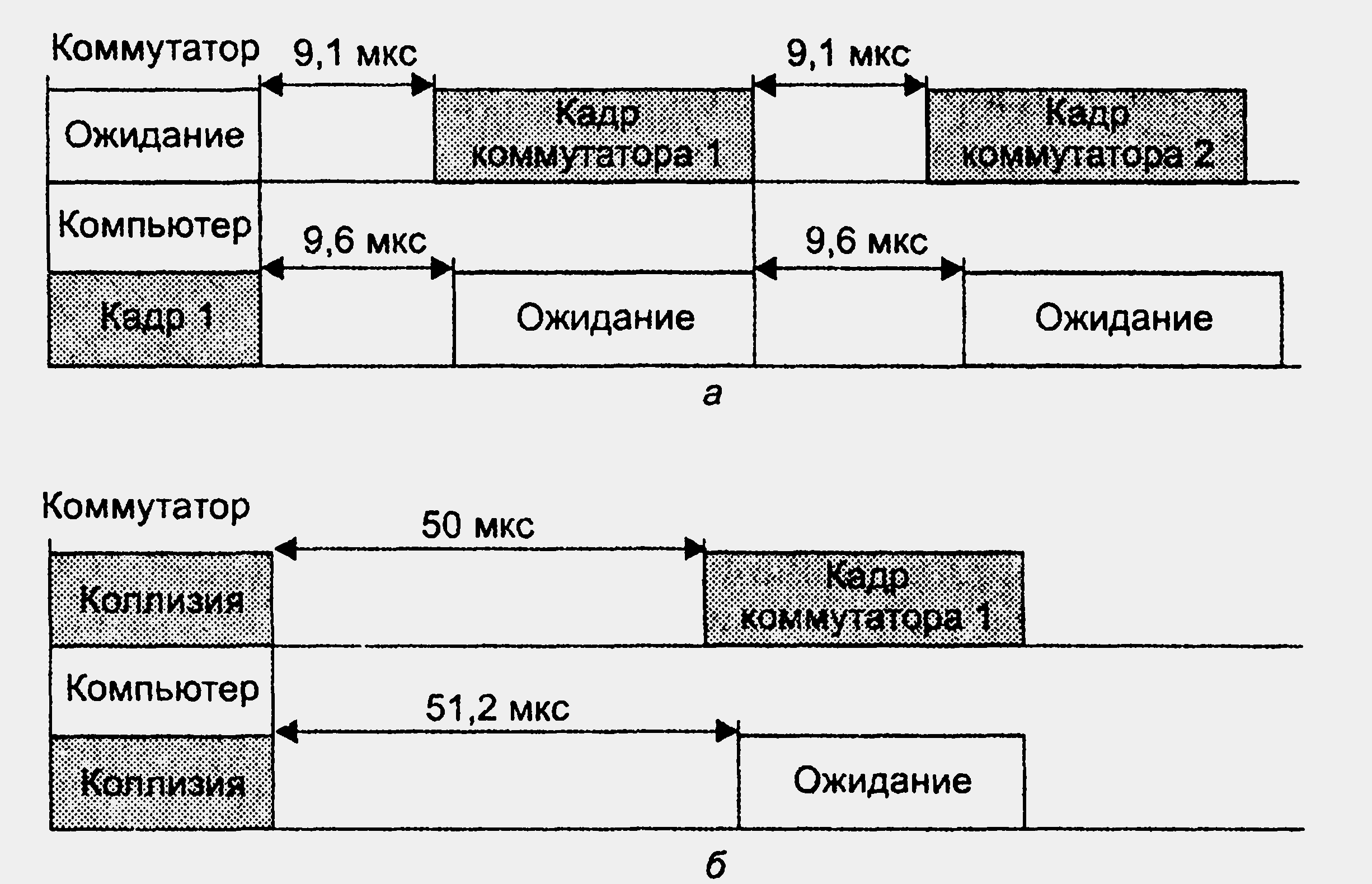
Рисунок 16.2. Агрессивное поведение порта коммутатора при перегрузках
В первом случае (рис. 16.2, а) коммутатор окончил передачу очередного кадра и вместо технологической паузы в 9,6 мкс сделал паузу в 9,1 мкс после чего начал передачу нового кадра. Компьютер не смог захватить среду, так как он выдержал стандартную паузу в 9,6 мкс и обнаружил после этого, что среда уже занята.
Во втором случае (рис. 16.2, б) кадры коммутатора и компьютера столкнулись, то есть была зафиксирована коллизия. Так как компьютер сделал паузу после коллизии в 51,2 мкс, как это положено по стандарту (интервал отсрочки равен 512 битовых интервалов), а коммутатор — 50 мкс, то и в этом случае компьютеру не удалось передать свой кадр.
Коммутатор может пользоваться этим механизмом адаптивно, увеличивая степень своей агрессивности по мере необходимости.
Многие производители путем сочетания этих двух методов реализуют достаточно тонкие механизмы управления потоком кадров при перегрузках.
Простой отказ от поддержки алгоритма доступа к разделяемой среде без какой-либо модификации протокола ведет к повышению вероятности потерь кадров коммутаторами, так как при этом теряется контроль за потоками кадров, направляемых конечными узлами в сеть. При переходе на полнодуплексный режим узлу разрешается отправлять кадры в коммутатор всегда, когда это ему нужно, поэтому коммутаторы сети могут в этом режиме сталкиваться с перегрузками, не имея при этом никаких средств «притормаживания» потока кадров.
Причина перегрузок обычно кроется в ограниченной пропускной способности отдельного выходного порта, которая определяется параметрами протокола.
Поэтому, если входной трафик неравномерно распределяется между выходными портами, легко представить ситуацию, когда в какой-либо выходной порт коммутатора будет направляться трафик с суммарной средней интенсивностью большей, чем протокольный максимум. На рис. 16.3 показана как раз такая ситуация, когда в порт 3 коммутатора Ethernet направляется от портов 1, 2, 4 и 6 поток кадров размером в 64 байт с суммарной интенсивностью в 22 100 кадров в секунду. Вспомним, что максимальная скорость в кадрах в секунду для сегмента Ethernet составляет 14 880. Естественно, что когда кадры поступают в буфер порта со скоростью 22 100 кадров в секунду, а уходят со скоростью 14 880 кадров в секунду, то внутренний буфер выходного порта начинает неуклонно заполняться необработанными кадрами.
Нетрудно подсчитать, что при размере буфера в 100 Кбайт в приведенном примере полное заполнение буфера произойдет через 0,22 с после начала работы в таком интенсивном режиме. Увеличение буфера до 1 Мбайт даст увеличение времени заполнения буфера до 2,2 с, что также неприемлемо. Проблему можно решить с помощью средств контроля перегрузки.
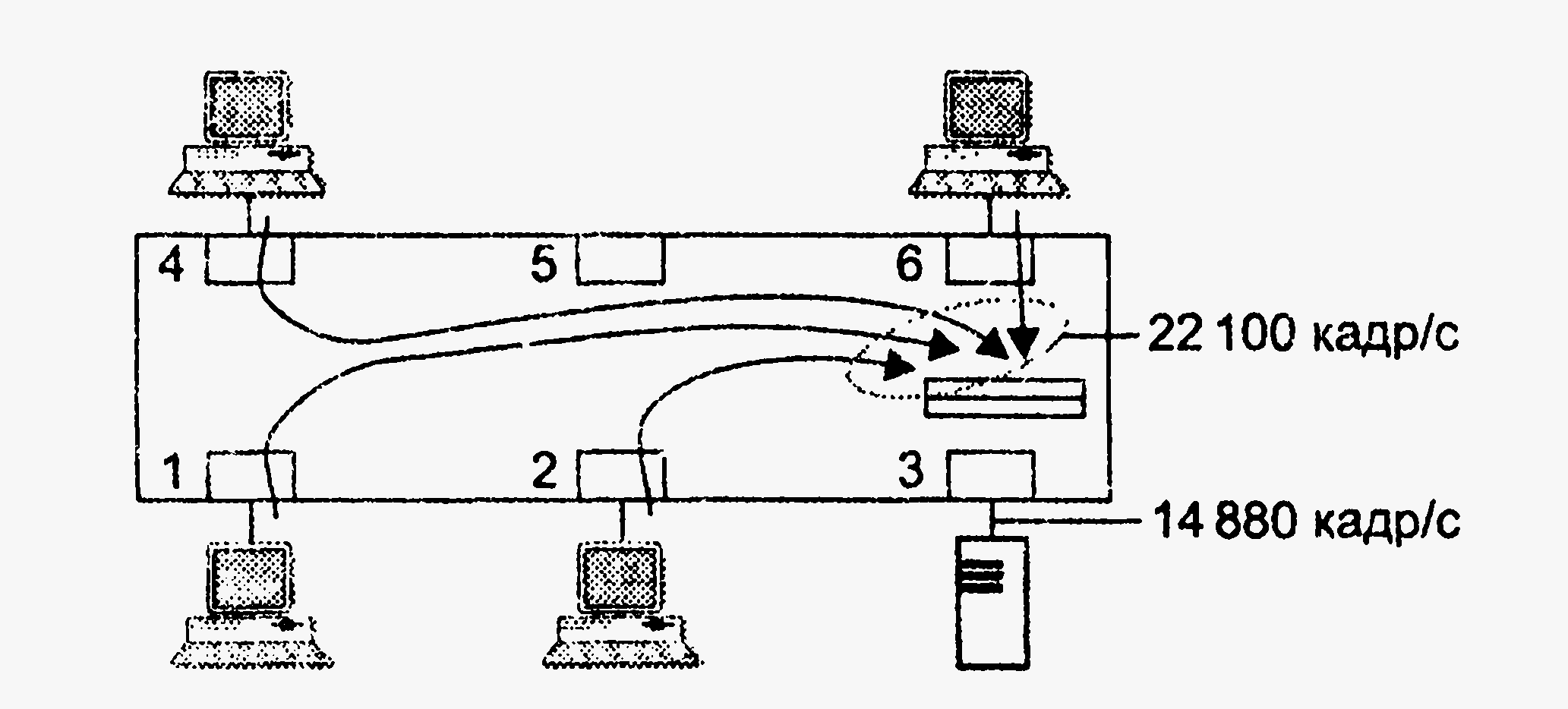
Рисунок 16.3. Переполнение буфера при несбалансированности трафика
Как мы знаем, существуют различные типы средств контроля перегрузки: управление очередями в коммутаторах, обратная связь, резервирование пропускной способности. На основе этих средств можно создать эффективную систему поддержки показателей QoS для трафика разных классов.
Механизм обратной связи был стандартизован для сетей Ethernet в марте 1997 года как спецификация IEEE 802.3x. Механизм обратной связи 802.3х используется только в дуплексном режиме работы портов коммутатора. Этот механизм очень важен для коммутаторов локальных сетей, так как он позволяет уменьшить потери кадров из-за переполнения буферов независимо от того, обеспечивает сеть дифференцированную поддержку показателей QoS для разных типов трафика или же предоставляет базовый сервис по доставке с максимальными усилиями («по возможности»).
Спецификация 802.3х вводит новый подуровень в стеке протоколов Ethernet — подуровень управления уровня MAC. Он располагается над уровнем MAC и является необязательным (рис. 16.4).
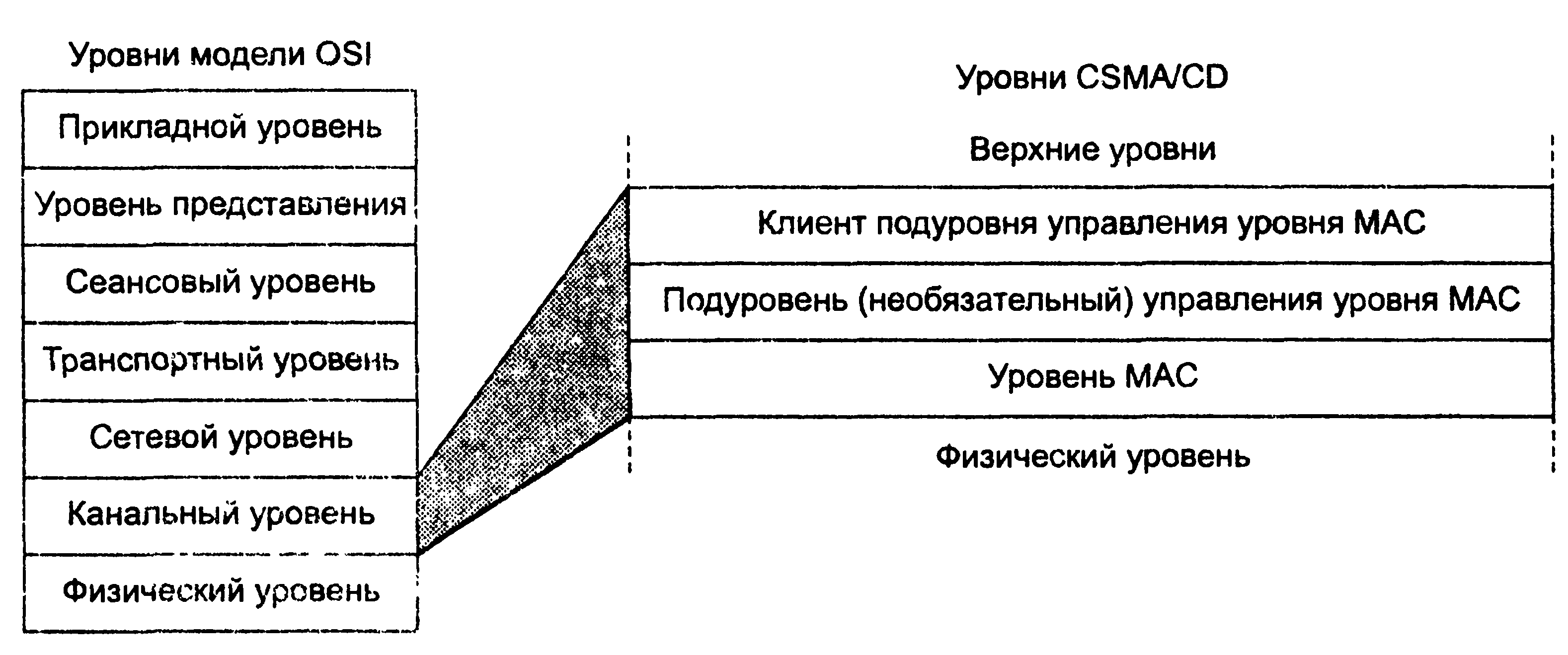
Рисунок 16.4. Подуровень управления уровня MAC
Кадры этого подуровня могут использоваться в различных целях, но пока в стандартах Ethernet для них определена только одна задача — приостановка передачи кадров другими узлами на определенное время.
Кадр подуровня управления отличается от кадров пользовательских данных тем, что в поле длины/типа всегда содержится шестнадцатеричное значение 88-08. Формат кадра подуровня управления рассчитан на универсальное применение, поэтому он достаточно сложен (рис. 16.5).
В качестве адреса назначения можно использовать зарезервированное для этой цели значение группового адреса 01-80-С2-00-00-01. Это удобно в том случае, когда соседний узел также является коммутатором (так как порты коммутатора не имеют уникальных МАС-адресов). Если сосед — конечный узел, можно также использовать уникальный МАС-адрес.
В поле кода операции подуровня управления указывается шестнадцатеричный код 00-01, поскольку, как уже было отмечено, пока определена только одна операция подуровня управления, она называется PAUSE (пауза) и имеет шестнадцатеричный код 00-01.

Рисунок 16.5. Формат кадра подуровни управления
В поле параметров подуровня управления указывается время, на которое узел, получивший такой код, должен прекратить передачу кадров узлу, отправившему кадр с операцией PAUSE. Время измеряется в 512 битовых интервалах конкретной реализации Ethernet, диапазон возможных вариантов приостановки равен 0-65535.
Как видно из описания, этот механизм обратной связи относится к типу 2. Специфика его состоит в том, что в нем предусмотрена только одна операция — приостановка на определенное время. Обычно же в механизмах этого типа используются две операции — приостановка и возобновление передачи кадров. Именно так этот механизм реализован в одном из наиболее старых протоколов сетей с коммутацией пакетов — протоколе сети Х.25 под названием LAP-B.