- Общие положения
- Развертывание Ceph с помощью средства ceph-deploy
- Использование кластера Ceph
- Оглавление
- Установка
- Создание файла конфигурации
- Настройка кластерной файловой системы OCFS2.
- Файловые
- Требования
- Создание хранилищ
- Создание файловых систем
- Проверка
- Файловые
- Требования
- Создание хранилищ
- Создание файловых систем
- Проверка
Общие положения
Распределенные файловые системы используются в высокоскоростных вычислениях и фокусируются на высокой доступности, производительности и масштабируемости. ОС Astra Linux поддерживает распределенную файловую систему Ceph.
Ceph — распределенная объектная сеть хранения, обеспечивающая файловый и блочный интерфейсы доступа.
Может использоваться на системах, состоящих как из нескольких серверов, так и из тысяч узлов. Встроенные механизмы продублированной репликации данных обеспечивают высокую отказоустойчивость системы. При добавлении или удалении новых узлов массив данных автоматически балансируется с учетом внесенных изменений. В Ceph обработка данных и метаданных разделена на различные группы узлов в кластере.
Развертывание Ceph с помощью средства ceph-deploy
Далее описан возможный вариант настройки распределенного хранилища на базе Ceph на примере кластера из 3 узлов:
и административной рабочей станции astra-ceph-admin .
При настройке на узлах кластера будут развернуты:
- сервис монитора (MON);
- сервис хранилища данных (OSD).
Использованная конфигурация предназначена только для ознакомления и тестирования Ceph. При развертывании рабочей системы на объекте не рекомендуется размещать монитор и OSD на одном узле.
В составе каждого из узлов кластера имеются два жестких диска:
Кроме того, на узле astra-ceph1 будет запущен сервис ceph-mgr (Ceph Manager Daemon).
Предполагается, что перед началом развертывания Ceph на узлах astra-ceph1 , astra-ceph2 и astra-ceph3 выполнены следующие действия:
- установлен фиксированный IP-адрес, в качестве сервера DNS указан IP-адрес административной рабочей станции astra-ceph-admin ;
- настроена служба синхронизации времени. В качестве сервера единого сетевого времени выступает административная рабочая станция astra-ceph-admin .
Предполагается, что далее во время развертывания Ceph на всех узлах кластера доступен репозиторий ОС Астра.
При развертывании с помощью средства ceph-deploy администрирование кластера осуществляется с административной рабочей станции astra-ceph-admin . Для удобства развёртывания, в файле /etc/hosts указаны короткие имена рабочей станции и узлов кластера:
10.0.0.100 astra-ceph-admin 10.0.0.171 astra-ceph1 10.0.0.172 astra-ceph2 10.0.0.173 astra-ceph3
Средство ceph-deploy обеспечивает быстрый способ развертывания Ceph без тонкой настройки, используя инструменты ssh, sudo и Python.
- Перед началом развертывания на всех узлах кластера и на административной рабочей станции необходимо выполнить следующие предварительные действия:
- файловая система cephfs;
- блочное устройство rbd;
- объектное хранилище с доступом через s3-совместимое api.
- – количество узлов, которые могут одновременно смонтировать том, количество можно будет изменить с помощью enbkbns tunefs.ocfs2;
- – метка (условное наименование heartbeat-устройства);
- – дисковое устройство.
- Установить пакеты python и ssh, если он не были ранее установлены:
Дальнейшие предварительные действия на узлах кластера при необходимости можно выполнить с рабочей станции, подключаясь через SSH от имени администратора системы;
В результате появится диалог, в котором необходимо задать пароль пользователя и ввести дополнительную информацию. По окончании диалога необходимо ответить «y» («Да»);
echo «ceph-adm ALL = (root) NOPASSWD:ALL» | sudo tee /etc/sudoers.d/ceph-adm
sudo chmod 0440 /etc/sudoers.d/ceph-adm
Развертывание Ceph с помощью средства ceph-deploy выполняется на административной рабочей станции astra-ceph-admin от имени пользователя ceph-adm .
Недопустимо использование средства ceph-deploy от имени суперпользователя (с sudo или же от имени пользователя root).
Далее для развертывания Ceph необходимо выполнить на административной рабочей станции astra-ceph-admin следующую последовательность действий:
- настроить беспарольный ssh-доступ на все узлы кластера, выполнив последовательность команд:
В ходе выполнения команд для каждого узла кластера необходимо ответить <> (>) и указать пароль пользователя ceph-adm ;
После выполнения команды будут созданы конфигурационный файл ceph.conf и keyring-файл мониторов;
ceph-deploy —username ceph-adm osd create —data /dev/sdb astra-ceph1
ceph-deploy —username ceph-adm osd create —data /dev/sdb astra-ceph2
ceph-deploy —username ceph-adm osd create —data /dev/sdb astra-ceph3
cluster: id: 03ff5b8a-a453-4da3-8296-2d473649bcc4 health: HEALTH_OK services: mon: 3 daemons, quorum astra-ceph1,astra-ceph2,astra-ceph3 (age 3h) mgr: astra-ceph1(active, since 3h) osd: 3 osds: 3 up (since 3h), 3 in (since 25h) data: pools: 0 pools, 0 pgs objects: 0 objects, 0 bytes usage: 3.0 GiB used, 45 GiB / 48 GiB avail pgs:
Использование кластера Ceph
Ceph представляет для клиента различные варианты доступа к данным:
Ниже представлен пример настройки работы с хранилищем в варианте файловой системы cephfs. Основное преимущество файловой системы cephfs в том, что при её использовании возможно монтировать один и тот же каталог с данными на чтение и запись множеству клиентов. Для того, чтобы клиенты могли подключать Ceph как файловую систему, необходимо в кластере инициализировать хотя бы один сервер метаданных (MDS).
Для организации доступа к файловой системе cephfs выполнить следующую последовательность действий на административной рабочей станции astra-ceph-admin :
- установить и активировать сервис Metadata Server Daemon — сервер метаданных на узле astra-ceph1:
ceph-deploy —username ceph-adm install —mds astra-ceph1
ceph-deploy —username ceph-adm mds create astra-ceph1
sudo ceph osd pool create cephfs_data 64
sudo ceph osd pool create cephfs_metadata 64
sudo ceph osd pool application enable cephfs_metadata cephfs
Значением размера PG должно быть число, являющееся степенью 2 (64, 128, 256. ). При этом необходимо соблюсти баланс между количеством групп на OSD и их размером. Чем больше PG на одной OSD, тем больше понадобится памяти для хранения информации об их расположении. А чем больше размер самой PG, тем больше данных будет перемещаться при балансировке. Примерная формула расчета PG:
Total PGs = (Number OSD * 100) / max_replication_count
Оглавление
В статье описаны шаги по настройке кластерной файловой системы OCFS2 в режиме global hearbeat.
Установка
Установить пакеты кластерной файловой системы OCFS2 на каждом узле кластера командой:
Создание файла конфигурации
Конфигурационные файлы на каждом узле кластера должны быть идентичны.
Допускается на одном из узлов кластера выполнить описанные ниже действия по созданию файл конфигурации /etc/ocfs2/cluster.conf , а затем скопировать его на другие узлы.
o2cb add-node ocfs2cluster node1 —ip 192.168.55.11 o2cb add-node ocfs2cluster node2 —ip 192.168.55.12 o2cb add-node ocfs2cluster node3 —ip 192.168.55.13
Подключение в качестве heartbeat-устройства отдельного дискового устройства /dev/sdd :
mkfs.ocfs2 -N 3 -L cluster_hb —cluster-name=ocfs2cluster —cluster-stack=o2cb —global-heartbeat /dev/sdd
o2cb add-heartbeat ocfs2cluster /dev/sdd
В качестве heartbeat-устройства также может выступать диск на котором в последующем могут располагаться данные. Предварительно устройство надо отформатировать.
Для использования диска в качестве hearbeat-устройства необходимо указывать целый диск, нельзя настроить global heartbeat на разделе диска.
Ниже приведено содержание итогового файла конфигурации.
node: name = node1 cluster = ocfs2cluster number = 0 ip_address = 192.168.55.11 ip_port = 7777 node: name = node2 cluster = ocfs2cluster number = 1 ip_address = 192.168.55.12 ip_port = 7777 node: name = node3 cluster = ocfs2cluster number = 2 ip_address = 192.168.55.13 ip_port = 7777 cluster: name = ocfs2cluster heartbeat_mode = global node_count = 3 heartbeat: cluster = ocfs2cluster region = 7DA5015346C245E6A41AA85E2E7EA3CFНастройка кластерной файловой системы OCFS2.
Файловые
В данном разделе описаны варианты настройки хранилищ облака с использованием кластерных файловых систем. Образы ВМ будут храниться в виде файлов в этих файловых системах.
Требования
Прежде чем начать работу необходимо убедиться, что соблюдены следующие условия:
Создание хранилищ
Создадим хранилище images. В веб-интерфейсе управления облаком перейти в Storage — Datastores.
Нажать + и заполнить, как представлено ниже и нажать Create
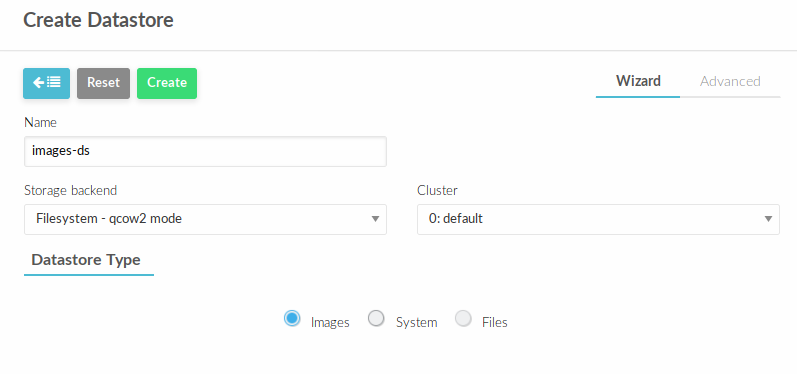
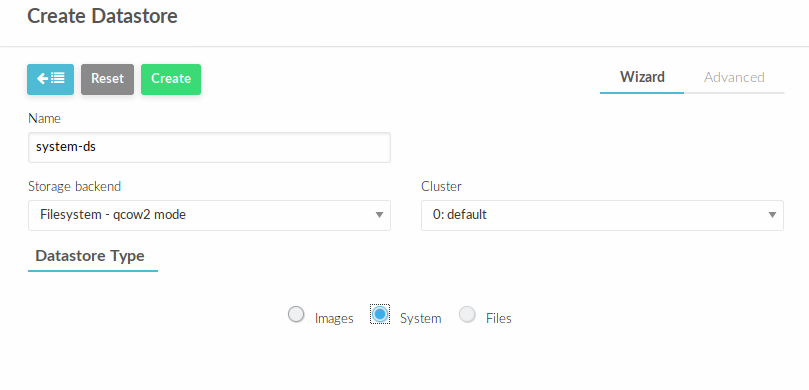
Аналогичным способом создать хранилище типа system
В Datastores отобразятся созданные хранилища с их идентификаторами (ID)
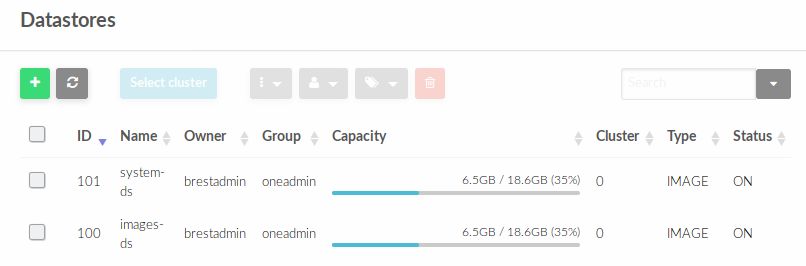
На Front-end по пути /var/lib/one/datastores будут созданы два каталога с именами, с соответствующими идентификаторами datastore-id .
В данном случае это 100 и 101. В дальнейшем в эти пути необходимо смонтировать созданные на СХД LUN-ы, но для начала необходимо разметить их одной из кластерных файловых систем.
Далее необходимо отформатировать оба LUN , как описано ниже
Создание файловых систем
На данный момент поддерживаются два кластерные ФС — OCFS2 и GFS2
На каждом узле кластера (F ront-end и узлах виртуализации) выполните шаги по статье OCFS2
Далее на одном из узлов отформатируйте LUN-a следующим образом:
sudo mkfs.ocfs2 --cluster-stack=o2cb --cluster-name=ocfs2 /dev/
— имя блочного устройства LUN
Перед настройкой автоматического монтирования каталогов при загрузке ОС, на узлах виртулазиции требуется создать каталоги с соответствующими datastore-id , т.к. в отличие от Front-end , автоматически они не создаются на узлах виртуализации.
sudo mkdir /var/lib/one/datastores/
После этого, на каждом узле необходимо добавить данные ФС к каталогом, которые будут автоматически монтироваться при загрузке узла. Определите UUID uuid разделов командой:
и добавьте его монтирование в /etc/fstab :
UUID= /var/lib/one/datastores/ ocfs2 _netdev,x-systemd.requires=o2cb.service 0 0Проверка
На всех узлах кластера выполните команду:
убедиться, что монтирование прошло без ошибок.
Файловые
В данном разделе описаны варианты настройки хранилищ облака с использованием кластерных файловых систем. Образы ВМ будут храниться в виде файлов в этих файловых системах.
Требования
Прежде чем начать работу необходимо убедиться, что соблюдены следующие условия:
Создание хранилищ
Создадим хранилище images. В веб-интерфейсе управления облаком перейти в Storage — Datastores.
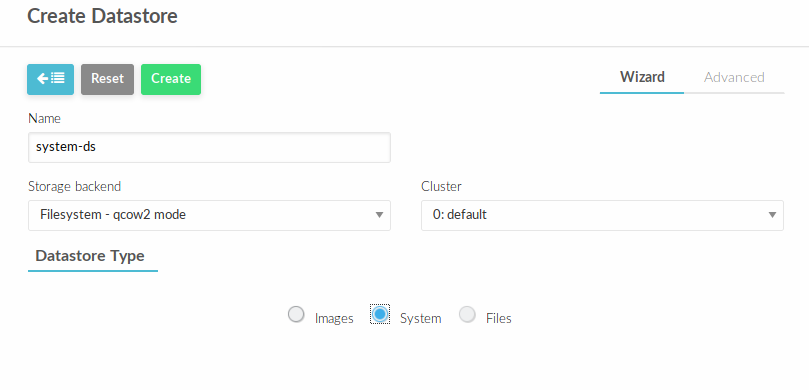
Нажать + и заполнить, как представлено ниже и нажать Create
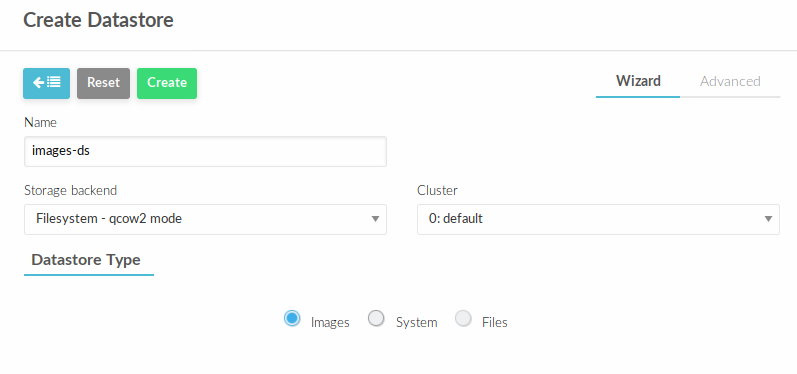
Аналогичным способом создать хранилище типа system
В Datastores отобразятся созданные хранилища с их идентификаторами (ID)
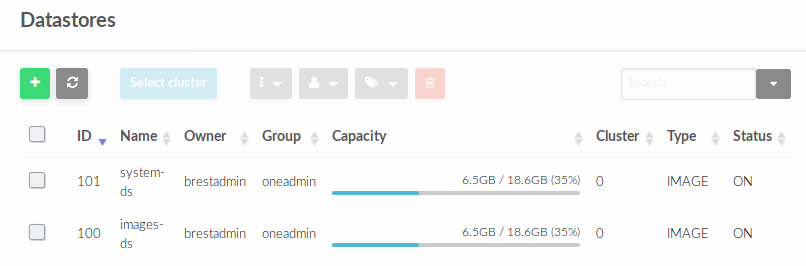
На Front-end по пути /var/lib/one/datastores будут созданы два каталога с именами, с соответствующими идентификаторами datastore-id .
В данном случае это 100 и 101. В дальнейшем в эти пути необходимо смонтировать созданные на СХД LUN-ы, но для начала необходимо разметить их одной из кластерных файловых систем.
Далее необходимо отформатировать оба LUN , как описано ниже
Создание файловых систем
На данный момент поддерживаются два кластерные ФС — OCFS2 и GFS2
На каждом узле кластера (F ront-end и узлах виртуализации) выполните шаги по статье OCFS2
Далее на одном из узлов отформатируйте LUN-a следующим образом:
sudo mkfs.ocfs2 --cluster-stack=o2cb --cluster-name=ocfs2 /dev/
— имя блочного устройства LUN
Перед настройкой автоматического монтирования каталогов при загрузке ОС, на узлах виртулазиции требуется создать каталоги с соответствующими datastore-id , т.к. в отличие от Front-end , автоматически они не создаются на узлах виртуализации.
sudo mkdir /var/lib/one/datastores/
После этого, на каждом узле необходимо добавить данные ФС к каталогом, которые будут автоматически монтироваться при загрузке узла. Определите UUID uuid разделов командой:
и добавьте его монтирование в /etc/fstab :
UUID= /var/lib/one/datastores/ ocfs2 _netdev,x-systemd.requires=o2cb.service 0 0Проверка
На всех узлах кластера выполните команду:
убедиться, что монтирование прошло без ошибок.