- How to Use Regex with the `awk` Command
- The basic characters used in patterns
- Create a file
- Example 1: Define a regex pattern using the character class
- Example 2: Define a regex pattern using the ‘^’ symbol
- Example 3: Define a regex pattern using the gsub function
- Example 4: Define a regex pattern with ‘*’
- Example 5: Define a regex pattern using the ‘$’ symbol
- Example 6: Define a regex pattern using the ‘^’ and ‘|’ symbols
- Example 7: Define a regex pattern using the ‘+’ symbol
- Example 8: Define a regex pattern using the gsub() function
- Conclusion
- About the author
- Fahmida Yesmin
- AWK – Регулярные выражения
- точка
- пример
- Выход
- Начало строки
- пример
- Выход
- Конец линии
- пример
- Выход
- Совпадает с набором символов
- пример
- Выход
- Эксклюзивный набор
- пример
- Выход
- Внесение изменений
- пример
- Выход
- Ноль или одно вхождение
- пример
- Выход
- Ноль или более вхождение
- пример
- Выход
- Одно или несколько вхождений
- пример
- Выход
- группирование
- пример
- Awk linux примеры регулярные выражения
How to Use Regex with the `awk` Command
![]()
A regular expression (regex) is used to find a given sequence of characters within a file. Symbols such as letters, digits, and special characters can be used to define the pattern. Various tasks can be easily completed by using regex patterns. In this tutorial, we will show you how to use regex patterns with the `awk` command.
The basic characters used in patterns
Many characters can be used to define a regex pattern. The characters most commonly used to define regex patterns are defined below.
| Character | Description |
|---|---|
| . | Match any character without a newline (\n) |
| \ | Quote a new meta-character |
| ^ | Match the beginning of a line |
| $ | Match the end of a line |
| | | Define an alternate |
| () | Define a group |
| [] | Define a character class |
| \w | Match any word |
| \s | Match any white space character |
| \d | Match any digit |
| \b | Match any word boundary |
Create a file
To follow along with this tutorial, create a text file named products.txt. The file should contain four fields: ID, Name, Type, and Price.
p1001 15″Monitor Monitor $100
p1002 A4tech Mouse Mouse $10
p1003 Samsung Printer Printer $50
p1004 HP Scanner Scanner $60
p1005 Logitech Mouse Mouse $15
Example 1: Define a regex pattern using the character class
The following `awk` command will search for and print lines containing the character ‘n’ followed by the characters ‘er’.
The following output will be produced after running the above commands. The output shows the line that matches the pattern. Here, only one line matches the pattern.
Example 2: Define a regex pattern using the ‘^’ symbol
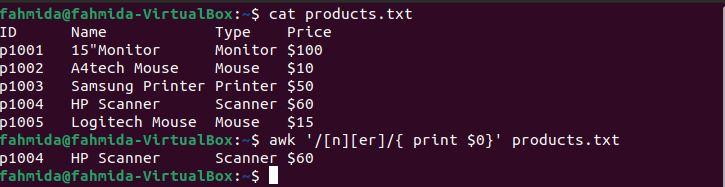
The following `awk` command will search for and print lines that start with the character ‘p’ and include the number 3.
The following output will be produced after running the above commands. Here, there is one line that matches the pattern.
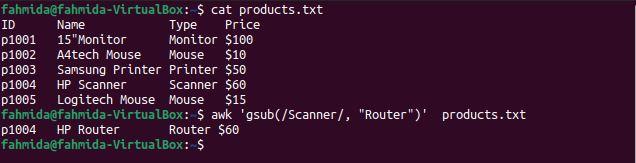
Example 3: Define a regex pattern using the gsub function
The gsub() function is used to globally search for and replace text. The following `awk` command will search for the word ‘Scanner’ and replace it with the word ‘Router’ before printing the result.
$ awk ‘gsub(/Scanner/, «Router»)’ products.txt
The following output will be produced after running the above commands. There is one line that contains the word ‘Scanner‘, and ‘Scanner‘ is replaced by the word ‘Router‘ before the line is printed.
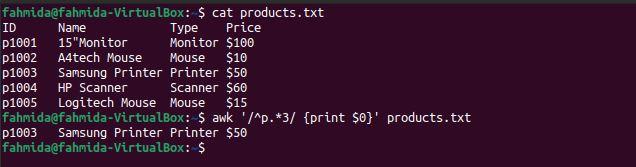
Example 4: Define a regex pattern with ‘*’
The following `awk` command will search for and print any string that starts with ‘Mo’ and includes any subsequent character.
The following output will be produced after running the above commands. Three lines match the pattern: two lines contain the word ‘Mouse‘ and one line contains the word ‘Monitor‘.
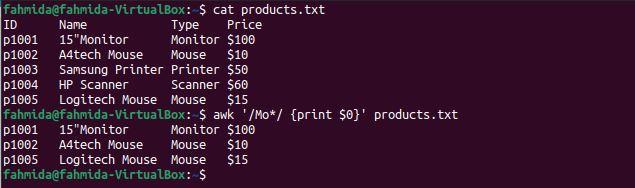
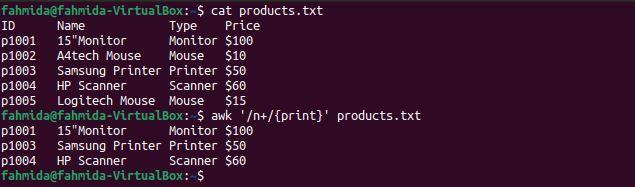
Example 5: Define a regex pattern using the ‘$’ symbol
The following `awk` command will search for and print lines in the file that end with the number 5.
The following output will be produced after running the above commands. There is only one line in the file that ends with the number 5.
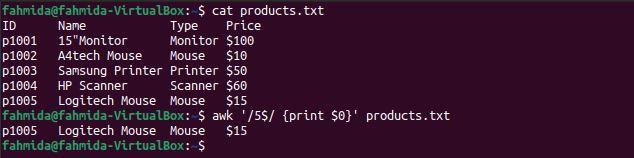
Example 6: Define a regex pattern using the ‘^’ and ‘|’ symbols
The ‘^‘ symbol indicates the start of a line, and the ‘|‘ symbol indicates a logical OR statement. The following `awk` command will search for and print lines that start with the character ‘p‘ and contain either ‘Scanner‘ or ‘Mouse‘.
$ awk ‘/^p.* (Scanner|Mouse)/’ products.txt
The following output will be produced after running the above commands. The output shows that two lines contain the word ‘Mouse‘ and one line contains the word ‘Scanner‘. The three lines start with the character ‘p‘.
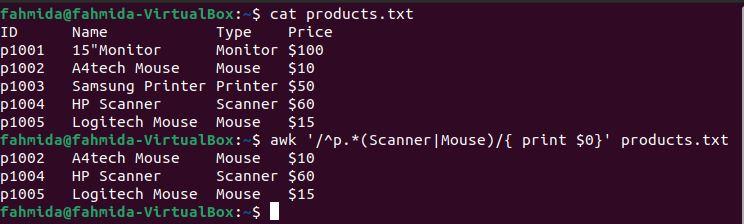
Example 7: Define a regex pattern using the ‘+’ symbol
The ‘+‘ operator is used to find at least one match. The following `awk` command will search for and print lines that contain the character ‘n‘ at least once.
The following output will be produced after running the above commands. Here, the character ‘n‘ contains occurs at least once in the lines that contain the words Monitor, Printer, and Scanner.
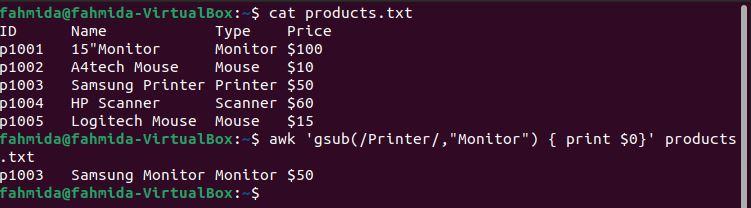
Example 8: Define a regex pattern using the gsub() function
The following `awk` command will globally search for the word ‘Printer‘ and replace it with the word ‘Monitor‘ using the gsub() function.
$ awk ‘gsub(/Printer/, “Monitor”) < print$0>‘ products.txt
The following output will be produced after running the above commands. The fourth line of the file contains the word ‘Printer‘ twice, and in the output, ‘Printer‘ has been replaced by the word ‘Monitor‘.
Conclusion
Many symbols and functions can be used to define regex patterns for different search and replace tasks. Some symbols commonly used in regex patterns are applied in this tutorial with the `awk` command.
About the author
Fahmida Yesmin
I am a trainer of web programming courses. I like to write article or tutorial on various IT topics. I have a YouTube channel where many types of tutorials based on Ubuntu, Windows, Word, Excel, WordPress, Magento, Laravel etc. are published: Tutorials4u Help.
AWK – Регулярные выражения
AWK очень мощный и эффективный в обработке регулярных выражений. Ряд сложных задач можно решить с помощью простых регулярных выражений. Любой эксперт командной строки знает силу регулярных выражений.
В этой главе рассматриваются стандартные регулярные выражения с подходящими примерами.
точка
Он соответствует любому отдельному символу, кроме символа конца строки. Например, следующий пример соответствует fin, fun, fan и т. Д.
пример
[jerry]$ echo -e "cat\nbat\nfun\nfin\nfan" | awk '/f.n/'
Выполнив приведенный выше код, вы получите следующий результат –
Выход
Начало строки
Это соответствует началу строки. Например, в следующем примере печатаются все строки, начинающиеся с шаблона The .
пример
[jerry]$ echo -e "This\nThat\nThere\nTheir\nthese" | awk '/^The/'
Выполнив этот код, вы получите следующий результат –
Выход
Конец линии
Это соответствует концу строки. Например, в следующем примере печатаются строки, заканчивающиеся буквой n .
пример
[jerry]$ echo -e "knife\nknow\nfun\nfin\nfan\nnine" | awk '/n$/'
Выход
Выполнив этот код, вы получите следующий результат –
Совпадает с набором символов
Используется для соответствия только одному из нескольких символов. Например, следующий пример соответствует шаблону Call и Tall, но не Ball .
пример
[jerry]$ echo -e "Call\nTall\nBall" | awk '/[CT]all/'
Выход
Выполнив этот код, вы получите следующий результат –
Эксклюзивный набор
В эксклюзивном наборе карат сводит на нет набор символов в квадратных скобках. Например, следующий пример печатает только Ball .
пример
[jerry]$ echo -e "Call\nTall\nBall" | awk '/[^CT]all/'
Выполнив этот код, вы получите следующий результат –
Выход
Внесение изменений
Вертикальная черта позволяет регулярным выражениям быть логически ИЛИ. Например, следующий пример печатает Ball and Call .
пример
[jerry]$ echo -e "Call\nTall\nBall\nSmall\nShall" | awk '/Call|Ball/'
Выполнив этот код, вы получите следующий результат –
Выход
Ноль или одно вхождение
Это соответствует нулю или одному вхождению предыдущего символа. Например, следующий пример соответствует цвету, а также цвет . Мы сделали вас необязательным персонажем, используя ? ,
пример
[jerry]$ echo -e "Colour\nColor" | awk '/Colou?r/'
Выполнив этот код, вы получите следующий результат –
Выход
Ноль или более вхождение
Это соответствует нулю или более вхождений предыдущего символа. Например, следующий пример соответствует ca, cat, catt и так далее.
пример
[jerry]$ echo -e "ca\ncat\ncatt" | awk '/cat*/'
Выполнив этот код, вы получите следующий результат –
Выход
Одно или несколько вхождений
Это соответствует одному или нескольким вхождениям предыдущего символа. Например, приведенный ниже пример соответствует одному или нескольким вхождениям из 2 .
пример
[jerry]$ echo -e "111\n22\n123\n234\n456\n222" | awk '/2+/'
Выполнив приведенный выше код, вы получите следующий результат –
Выход
группирование
Круглые скобки () используются для группировки и символа | используется для альтернатив. Например, следующее регулярное выражение соответствует строкам, содержащим либо Apple Juice, либо Apple Cake .
пример
[jerry]$ echo -e "Apple Juice\nApple Pie\nApple Tart\nApple Cake" | awk '/Apple (Juice|Cake)/'
Выполнив этот код, вы получите следующий результат –
Awk linux примеры регулярные выражения
A regular expression can be used as a pattern by enclosing it in slashes. Then the regular expression is tested against the entire text of each record. (Normally, it only needs to match some part of the text in order to succeed.) For example, the following prints the second field of each record where the string ‘ li ’ appears anywhere in the record:
$ awk '/li/ < print $2 >' mail-list -| 555-5553 -| 555-0542 -| 555-6699 -| 555-3430
Regular expressions can also be used in matching expressions. These expressions allow you to specify the string to match against; it need not be the entire current input record. The two operators ‘ ~ ’ and ‘ !~ ’ perform regular expression comparisons. Expressions using these operators can be used as patterns, or in if , while , for , and do statements. (See Control Statements in Actions.) For example, the following is true if the expression exp (taken as a string) matches regexp :
This example matches, or selects, all input records with the uppercase letter ‘ J ’ somewhere in the first field:
$ awk '$1 ~ /J/' inventory-shipped -| Jan 13 25 15 115 -| Jun 31 42 75 492 -| Jul 24 34 67 436 -| Jan 21 36 64 620
This next example is true if the expression exp (taken as a character string) does not match regexp :
The following example matches, or selects, all input records whose first field does not contain the uppercase letter ‘ J ’:
$ awk '$1 !~ /J/' inventory-shipped -| Feb 15 32 24 226 -| Mar 15 24 34 228 -| Apr 31 52 63 420 -| May 16 34 29 208 …
When a regexp is enclosed in slashes, such as /foo/ , we call it a regexp constant, much like 5.27 is a numeric constant and «foo» is a string constant.