- converting binary to text in linux
- 2 Answers 2
- Related
- Hot Network Questions
- Subscribe to RSS
- How to Edit and Convert Binary Files on Linux
- Create Binary File in Linux
- Editing Binary Files in Linux
- Convert Binary File to Text in Linux
- Convert binary mode to text mode and the reverse option
- 3 Answers 3
- Thread: convert binary to text
- convert binary to text
- Re: convert binary to text
- Re: convert binary to text
- How to convert «binary text» to «visible text»?
- 1 Answer 1
converting binary to text in linux
I have a big binary file I have produced by writing an array of float numbers in binary format. Now how can I simply convert that binary file to text ?
I just opened a binary file using ofstream out(blah , ios::out | ios::binary) and wrote in it out.write((char* ) blah, size); . what format is this?
Make your goal clearer, please. Do you want to read the values back in and produce formatted output a la printf ? In that case, an unpack() Perl or PHP script would probably much easier than C++.
2 Answers 2
Use the UNIX od command, with the -t f4 option to read the file as 4 byte floating point values. The -A n option is also useful to avoid printing the file offsets. Here is the output of an example file that I created.
/tmp> od -A n -t f4 b.dump -999.876 -998.876 -997.876 -996.876 -995.876 -994.876 -993.876 -992.876 -991.876 -990.876 -989.876 -988.876 -987.876 -986.876 -985.876 -984.876 You will need to reverse the process.
- Read the file back into an array of floats.
- Print the array use printf() or your favorite io function.
Any other approach will be ugly and painful; not to say this isn’t ugly to start with.
Related
Hot Network Questions
Subscribe to RSS
To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
Site design / logo © 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA . rev 2023.7.14.43533
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
How to Edit and Convert Binary Files on Linux
If a file stores data in contiguous bytes format, a program trying to read this file will need to be instructed on how to read it since such files do not directly define a compatible method for reading their associated content.
This type of file is called a binary file. Opening such a file on a normal text editor program will only display unreadable characters. It is because binary data store data as bytes and not as textual characters.
The headers of a binary file are accompanied by an instruction set that reveals how its stored data should be read. Since binary files can store any data type, we can broadly classify all file types as either binary or text.
Create Binary File in Linux
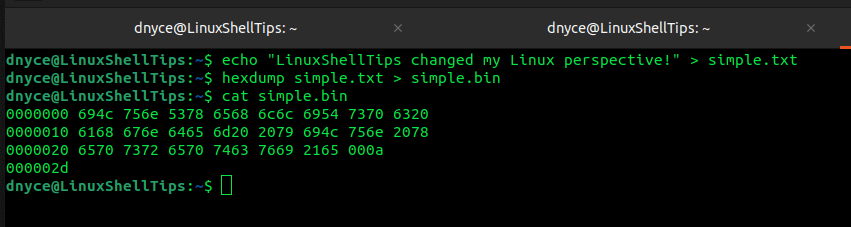
We are going to create a sample binary file that we will try to edit. We will first create a text file with some data in it and then convert the text file to a binary file using the hexdump command.
$ echo "LinuxShellTips changed my Linux perspective!" > simple.txt $ hexdump simple.txt > simple.bin
The cat command should confirm to us that the binary conversion was a success.
Editing Binary Files in Linux
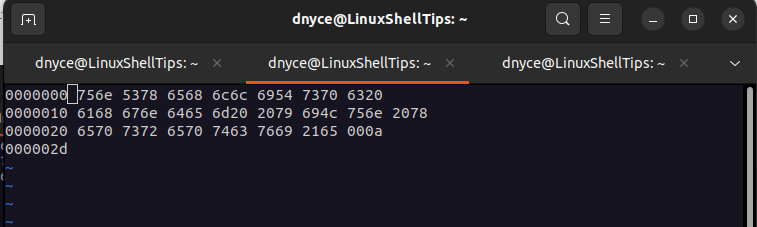
We are going to use the xxd command associated with the vim editor package. We first need to open the file on Vim editor using the -b flag since we are dealing with a binary file.
Use keyboard key [i] to enter insert mode and edit the binary file where needed. For instance, we can remove the first-line hex entries 694c to see what happens.
Convert Binary File to Text in Linux
To convert the binary file to text mode to view the implemented changes, we will switch to command mode using the keyboard key [Esc] and then key in the vim command:
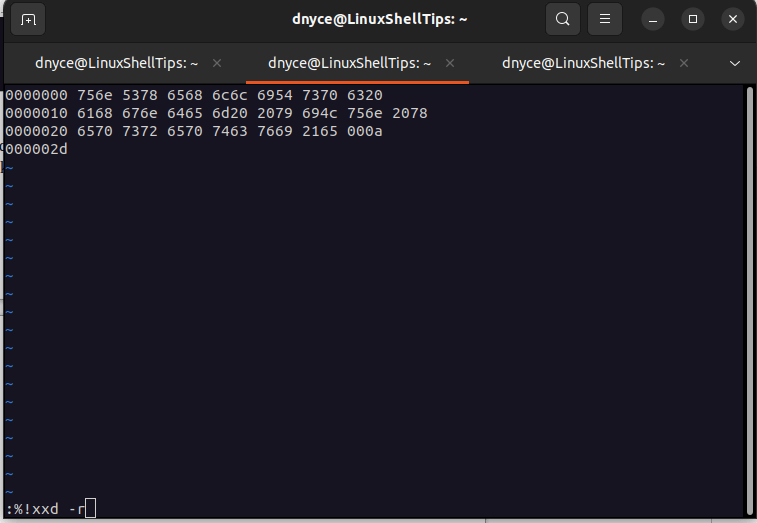
Once we hit [Enter] on the keyboard, we should see the edits we made.
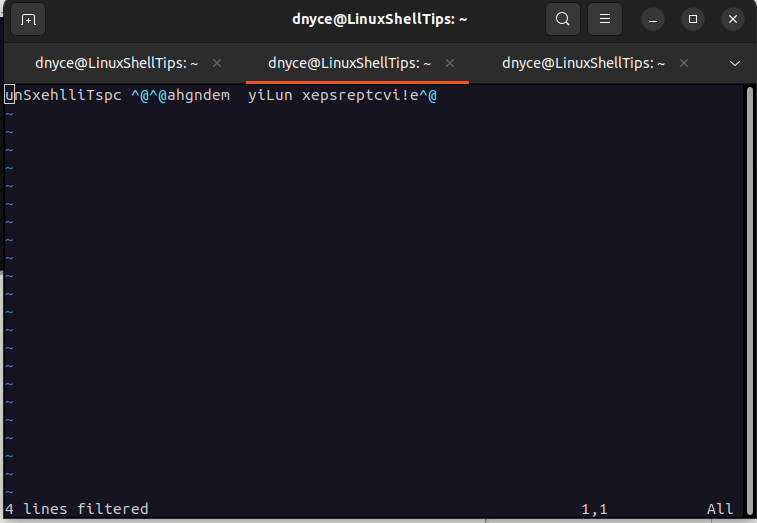
To save changes and quit vim use:
We have successfully demonstrated the possibility of editing a binary file in Linux using vim editor. Know of other cool ways of editing binary files? Feel free to leave a comment or feedback.
Convert binary mode to text mode and the reverse option
What leads you to believe it’s still a text file? xxd -r -p is the exact reverse of the od conversion you did; the output of cuonglm’s command should be strictly identical to the original tarball.
3 Answers 3
od -An -vtx1 Check.tar > Check.txt You need -v or od will condense sequences of identical bytes.
LC_ALL=C tr -cd 0-9a-fA-F < Check.txt | xxd -r -p >Check.tar perl -ape '$_=pack "(H2)*", @F' Check.txt > Check.tar If your purpose is to transfer files over a channel that only supports ASCII text, then there are dedicated tools for that like uuencode :
tar cf - myfiles.* | xz | uuencode myfiles.tar.xz | that-channel And to recover those files on the other end:
would recreate myfiles.tar.xz .
@maihabunash If you created file.txt without -v and with removing the address, then you can’t reliably recover file.tar if there were condensed sequences (do a grep ‘[*]’ file.txt to check) as you’ve lost the information of how long those condensed sequences were by removing the address.
hi , my target is to compress more then 30 perl script with tar or zip or whatever then convert it to text and then convert it back to compressed file , is it possible? ( I see tar is problem but can we do it with other options )
@maihabunash, you’re looking for uuencode or base64 encoding. Note that my answer covers your question. I give the code to convert back to binary from od output provided you don’t forget the -v option. If you’re transferring files over FTP, don’t forget to set the mode to «binary» ( TYPE I FTP command, something like binary in your client)
@pmor, It looks like you want the output of xxd -p which can be decoded with xxd -r -p . the tr | xxd -r -p approach already removes all whitepace (anything but xdigits). perl -pe ‘chomp;$_=pack»H*»,$_’ to decode the output of xxd -p
Answering the X part of this XY problem, I would recommend you investigate the reason your binary file transfers don’t transfer properly.
If it turns out the reason is because you don’t have an 8-bit clean datapath you could then use existing tools that were created to handle this situation, such as base64 or even uuencode . Old but still very effective.
tar czvf - /etc/h* | base64 >/tmp/tar.tgz.b64 ls -l /tmp/tar.tgz.b64 -rw-r--r-- 1 root root 7364 May 26 11:52 /tmp/tar.tgz.b64 . base64 -d /tmp/tar.tgz.b64 | tar tzvf - tar czvf - /etc/h* | uuencode - >/tmp/tar.tgz.uue ls -l /tmp/tar.tgz.uue -rw-r--r-- 1 root root 7530 May 26 11:51 /tmp/tar.tgz.uue . uudecode /tmp/tar.tgz.uue | tar xzvf - Thread: convert binary to text
 First Cup of Ubuntu
First Cup of Ubuntu ![]()
convert binary to text
Ubuntu addict and loving it ![]()
Re: convert binary to text
You will have to be more specific. Do you have a binary file which you want to search for ASCII strings? Do you have a text file containing binary data as 1’s and 0’s which you need to convert to ASCII text? Do you want to convert binary data to a text friendly representation such as base64 encoding?
Dark Roasted Ubuntu ![]()
Re: convert binary to text
Yeah i know this is an old thread but I’ve had success with this and also have a question. Now I could use some CLI tools w/bash script to achieve my ends here but I’m curious if there is already a linux tool for this. I can take a binary file and see the output in ascii text using hexdump, aka hd:
000000a0 30 e3 d3 60 e1 00 aa aa 03 00 00 00 08 00 45 00 |0..`. E.| 000000b0 00 8f bd 2a 40 00 6e 06 fb 0b 4d ff 44 4b c0 a8 |. *@.n. M.DK..| 000000c0 01 40 ba fd b8 e5 1f ca 95 17 49 4f b8 22 50 18 |.@. IO."P.| 000000d0 44 10 94 6a 00 00 9c ca f7 49 a2 f0 4f 91 59 54 |D..j. I..O.YT| 000000e0 04 ed 05 08 6c d4 3d 3a 96 82 51 f3 8f 33 d6 7d |. l.=. Q..3.>| 000000f0 ad 0a 7f a6 ae cf 24 34 ee ff 24 af 63 ae 5d dd |. $4..$.c.].| 00000100 6c 90 ab d2 82 4e 86 d2 b5 6f 8b fd 4b d1 7c 68 |l. N. o..K.|h| 00000110 0a 67 6e ee 73 6f 34 8c 44 8d 6f a3 87 96 04 35 |.gn.so4.D.o. 5| 00000120 f6 ea e8 c8 82 cf 2c fd 4e 65 64 0f 3e 8c 44 54 |. Ned.>.DT| 00000130 c5 6e 91 17 01 4d 0e 75 58 4e f4 95 9d 84 18 f2 |.n. M.uXN. | 00000140 c3 36 d4 ff 4d 24 7a 0b 00 0a 00 00 00 0a 00 00 |.6..M$z. | 00000150 00 d4 00 00 00 00 24 2b 28 04 e6 36 d4 ff 4d 40 |. $+(..6..M@| 00000160 7a 0b 00 4c 00 00 00 4c 00 00 00 08 41 34 00 98 |z..L. L. A4..| 00000170 2c be 0b ec 31 00 24 2b 28 04 e6 98 2c be 0b ec |. 1.$+(. | 00000180 31 80 59 39 2e 1b 00 aa aa 03 00 00 00 08 00 45 |1.Y9. E|
I don’t want the hexadecimal data, I just want the ascii on the right. Any tools or proper tool use for this? thanks in advance.
PS, I apologize in advance if i’m «thread hijacking» but I figured it was along the topic and didn’t want to start a new thread.
How to convert «binary text» to «visible text»?
I have a text file full of non-ASCII characters. I can not detect the encoding by either file or enca .
file non_ascii.txt non_ascii.txt: Non-ISO extended-ASCII text enca non_ascii.txt Unrecognized encoding But I can open it normally in Windows Notepad++ Edit: The expression above leads misunderstanding. Sorry for this. In fact, I picked some parts of the original file and put them into new text file, then opened in notepad++. The 2 parts shows as below. They are decoded in 2 different ways by notepad++. 
 Question:
Question:
- How could I detect the files encoding under linux?
- how do I recover the characters represented by ? I couldn’t get result by «grep ‘сойдя’ win.txt» even though the «сойдя» is encoded into ?
The file content slice as follows:
less non_ascii.txt «non_ascii.txt» may be a binary file. See it anyway?
I get 2 snippets from the file. they are showing «Windows-1251» and «ANSI». There maybe other encoding contained in the parts of the file. So is there ways to convert the mixed encoded content into UTF-8?
I got this file content from vary of sources. By python script reading lines from multiple files then write into one file finally.
You cannot concatenate files in different encodings and then mechanucally transform the resulting mess into something that makes sense.
1 Answer 1
Your question really has two parts: (1) how do I identify an unknown encoding and (2) how do I convert that to something useful?
The first part is the real challenge, and really cannot be answered in universal terms — in the general case, there is no reliable way to identify an unknown 8-bit encoding. Some encodings give you good hints (UTF-8 is an excellent example) and in many cases, if you have a good idea what the text is supposed to represent, the problem can be solved.
A mapping of 8-bit character meanings can be helpful (cough, the link is to mine) and in this case quickly hints at Windows code page 1251. Kudos for the hex dumps and the picture with the representation you expect!
With that out of the way, converting is easy.
iconv -f cp1251 -t utf-8 non_ascii.txt >utf8.txt Provided your Linux system is set up to use UTF-8 at the terminal, your grep command should work on utf-8.txt now.
The indication that some of the text is «ANSI» (which is a bogus term anyway) is probably just a red herring — as far as I can tell, everything in your excerpt looks like well-formed CP1251.
Some tools like chardet do a reasonable job of at least steering you in the right direction, though you have to understand that, like a human expert, they have to guess what the text is supposed to represent. There are corner cases where they just don’t have enough information to guess correctly, either because there are several candidate encodings with very few differences (for example, Latin-1 vs Latin-9 vs Windows-1252, all of which also overlap with plain 7-bit US-ASCII in the first 128 positions) or because the input doesn’t contain enough information to establish any common patterns.