- HackWare.ru
- Этичный хакинг и тестирование на проникновение, информационная безопасность
- Азы работы в командной строке Linux (часть 3)
- Стандартный вывод и стандартный ввод. Перенаправление вывода
- cat – для отображения содержимого файлов
- wc – для подсчёта строк, слов и байт
- grep – вывод строк, соответствующих шаблону
- uniq – сообщает о повторяющихся строках или удаляет их
- Различия между > и |
- less – для просмотра содержимого больших файлов
- head — Вывод только начала текстового файла
- tail — Вывод только конца текстового файла
- Ввод имён файлов в Linux
- Связанные статьи:
- Рекомендуется Вам:
- 2 комментария to Азы работы в командной строке Linux (часть 3)
HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
Азы работы в командной строке Linux (часть 3)
Стандартный вывод и стандартный ввод. Перенаправление вывода
Для командной строки существует такое понятие как «стандартный вывод». Стандартным является вывод в консоль. Например, команда
выводит в консоль список файлов:
Стандартный вывод можно перенаправить – вместо отображения в консоли его можно:
- сохранить в файл;
- передать другой программе;
- безвозвратно уничтожить без вывода и сохранения куда-либо.
Для сохранения в файл используется символ >
После этого символа нужно указать имя файла. Например:
При этом на экран ничего не вывелось. Но если проверить файлы, то можно увидеть новый с именем files.txt.
cat – для отображения содержимого файлов
Главной функцией cat является «склеивание» нескольких файлов. После неё можно указать название нескольких файлов, и она последовательно их выведет. Если вы указали название только одного файла, то будет отображён только он. Для показа только что созданного файла:
wc – для подсчёта строк, слов и байт
Программа wc считает, сколько ей передали строк, сколько слов и сколько байт.
После команды wc нужно указать имя файла, например:
Будет выведено что-то вроде:
- 11 – количество строк в файле
- 93 – количество слов в файле
- 619 – количество байт в файле
Если вы хотите, чтобы вывод ограничился количеством строк, то используйте ключ -l:
wc -l files.txt 11 files.txt
Там вы увидите, что если файл не задан, то читается стандартный вывод. Мы уже выяснили, что стандартный вывод – это то, что другие программы выводят в консоль. Если мы хотим передать вывод одной программы в другую, то используется символ |. Например:
Если программа принимает от другой программы вывод через символ |, то это называется стандартным вводом.
Мы также можем использовать различные опции, как с первой, так и со второй командой:
Можно воспользоваться стандартным выводом команды cat:
grep – вывод строк, соответствующих шаблону
Общий вид использования команды:
Означает искать в файле files.txt строки, соответствующие шаблону «txt».

Команда grep также поддерживает стандартный ввод:
ls -l | grep txt -rw-rw-r-- 1 mial mial 619 июн 23 13:08 files.txt -rw-rw-r-- 1 mial mial 4 июн 23 12:59 f.txt
Поиск по шаблону осуществляется с учётом регистра. Т.е. txt, Txt и TXT – это три разных шаблона и если вы указали txt, то строка, содержащая TXT будет считаться неподходящей. Для поиска без учёта регистра используется опция -i.
Чтобы было интереснее, скачайте или создайте текстовый файл. Если у вас нет своего файла, то скачайте словарик:
wget https://kali.tools/files/passwords/leaked_passwords/rockyou.txt.bz2 bunzip2 rockyou.txt.bz2
Примечание: wget и bunzip2 – это также команды Linux. Первая используется для получения файлов по сети, вторая для распаковки архивов. Пока мы не будем останавливаться на них подробно.
Итак, в результате работы этих двух команд мы скачали и распаковали текстовый файл. В текущей рабочей директории у нас присутствует файл rockyou.txt.
Поищем в этом файле строки, содержащие, например, шаблон «russia», чтобы поиск осуществлялся без учёта регистра, добавим ключ -i:
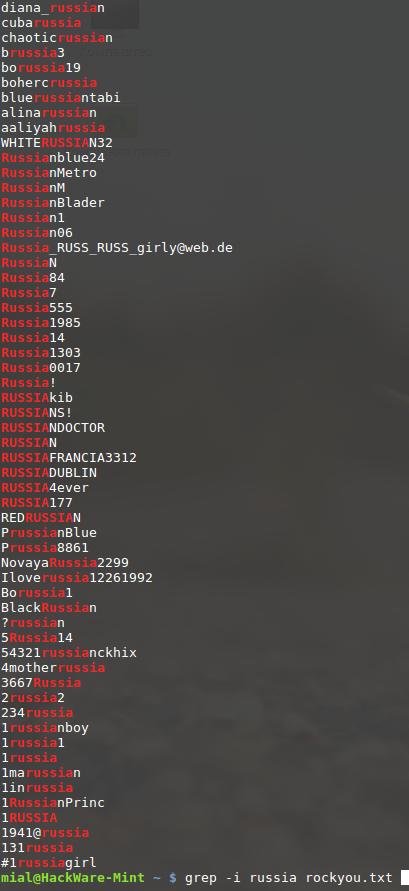
Как мы помним, команда grep может работать со стандартным вводом. Поэтому следующая команда абсолютно аналогична:
cat rockyou.txt | grep -i russia
Будет найдено довольно много совпадений. А сколько именно? Легко:
grep -i russia rockyou.txt | wc -l

Если вы немного запутались, поясню. Команда cat считывает файл rockyou.txt и выводит его в стандартный вывод, по стандартному вводу (символ |) стандартный вывод передаётся команде grep, которая без учёта регистра (-i) ищет все строки, содержащие слово russia, найденные строки по стандартному вводу (символ |) передаются команде wc, которая считает их количество, при этом считается только количество строк, а количество слов и количество байт не отображается (-l).
uniq – сообщает о повторяющихся строках или удаляет их
Команда uniq удаляет одинаковые строки или показывает их. Но она «видит» одинаковые строки только если они являются смежными (следуют друг за другом). Т.е. перед применением команды uniq, записи в файле нужно отсортировать. Для этого применяется команда sort.
Давайте начнём с того, что посчитаем общее количество строк в файле rockyou.txt. Для этого мы выведем его содержимое в стандартный вывод командой cat, а затем применим команду wc:
cat rockyou.txt | wc -l 14344391
Теперь перед тем, как посчитать количество строк, мы их отсортируем (команда sort) и удалим одинаковые (команда uniq). Обе эти команды умеют работать со стандартным вводом (а также и с файлами). Далее показан пример при работе со стандартным вводом:
cat rockyou.txt | sort | uniq | wc -l 14341564

Как можно заметить, в файле rockyou.txt имеется почти три тысячи абсолютно одинаковых строк.
Задание для самостоятельной работы: посмотрите справку по командам uniq, sort и wc и удалите дубликаты из файла rockyou.txt без использования стандартного ввода. А затем посчитайте количество уникальный записей также без использования стандартного ввода.
У команды uniq имется ключ -d, который позволяет просмотреть одинаковые строки. Но вначале очистим словарь от нечитаемых символов:
iconv -f utf-8 -t utf-8 -c ~/rockyou.txt > ~/rockyou_clean.txt
Подробности о проблеме, которую решает предыдущая команда, вы найдёте в статье «Как из текстового файла найти и удалить символы, отличные от UTF-8».
А теперь выведем список дублирующихся строк:
cat rockyou_clean.txt | sort | uniq -d
Различия между > и |
Оба символа: > и | используются для перенаправления стандартного вывода. Но символ > отправляет данные в файл, а символ | (его ещё называют «труба») отправляет их другой программе. Если сделать так:
То этой командой вы пытаетесь переписать бинарный (исполнимый) файл программы sort тем, что выдаст cat. Если вы обычный пользователь, то система не позволит вам испортить файл программы. Но если вы работаете под учётной записью администратора, то таким образом вы навредите системе, результат будет совершенно другим от ожидаемого вами.
Если вы хотите очистить файл rockyou.txt от дублей и сохранить результат в новый файл, то нужно сделать так:
cat rockyou.txt | sort | uniq > cleaned_rockyou.txt
Здесь cleaned_rockyou.txt – это название нового файла без дублей.
less – для просмотра содержимого больших файлов
Вы могли обратить внимание, что когда мы вывели результаты поиска командой:
cat rockyou.txt | grep -i russia
то вывод получил достаточно большим и пришлось прокручивать окно консоли вверх.
Что делать, если нужно просмотреть большой вывод или очень объёмный текстовый файл? Команда
в этом случае абсолютно бы не помогла, она только переполнит окно консоли, и вы даже не сможете просмотреть самые верхние строки файла.
Для таких случаев имеется команда less. Она может работать и с файлами и со стандартным вводом. Для просмотра файла:
Вы можете прокручивать большие файлы вверх и вниз.
Вы можете вводить команды для поиска и навигации по файлу:
| Команда | Действие |
|---|---|
| Page Up или b | Прокрутка назад на одну страницу |
| Page Down или пробел | Прокрутка вперёд на одну страницу |
| Стрелка вверх (↑) | Прокрутка вверх на одну строку |
| Стрелка вниз (↓) | Прокрутка вниз на одну строку |
| G | Перейти к концу файла |
| 1G или g | Перейти к началу файла |
| /символы | Поиск вперёд по файлу введённых символов |
| n | Поиск следующего вхождения предыдущего поиска |
| h | Показать справку |
| q | Выйти из less |
Для выхода из команды less используйте клавишу q.
head — Вывод только начала текстового файла
Команда head выводит только начало текстового файла. По умолчанию будет выведено первые 10 строк, например, чтобы вывести начало файла ZTE F2.txt:
Если вам нужно оставить только определённое число строк, то используйте опцию -n, после которой укажите желаемое число строк, например, чтобы вывести только одну первую строку файла:
Чтобы вывести первые 100 строк:
tail — Вывод только конца текстового файла
Эта команда похожа на head, но выводит конец файла.
По умолчанию выводятся последние 10 строк, но вы можете изменить их количество опцией -n:
Ввод имён файлов в Linux
Консоль поддерживает drag-and-drop, т.е. вы можете перетащить и бросить в консоль файл, после этого в консоли появится полный путь до файла.
Также используйте клавишу TAB для автодополнения имени файла и пути до него.
Будьте внимательны с файлами, у которых присутствуют в имени пробелы. Например, если вы хотите переименовать файл files.txt в файл new file.txt, то следующая команда завершиться шибкой:
Чтобы избежать ошибку, нужно:
- взять путь до файла, содержащий пробелы, в кавычки;
- экранировать пробел;
- вместо пробела использовать знак нижнего подчёркивания (_), который по общепринятому соглашению символизирует пробел.
Т.е. все следующие команды являются верными. Имя файла в кавычках:
Замена пробела на знак нижнего подчёркивания:
В Linux можно создавать файлы с именами, невозможными в Windows, например, в именах можно использовать слеши, двоеточие, нулевой байт и т.д. Будьте внимательны с такими файлами – в Windows вы не сможете их ни открыть, ни переименовать, ни удалить.
Связанные статьи:
Рекомендуется Вам:
2 комментария to Азы работы в командной строке Linux (часть 3)
Всех приветсвую, можете подсказать в чем проблема.
Я скачал файл rockyou без проблем.
Но когда я делаю поиск дубликатов cat rockyou.txt | sort | uniq -d у меня ничего не выводится, показыает 0; Пробовал сразу удалить дубликаты cat rockyou | sort | uniq таже история, сколько файлов было столько и есть.
После я создал свой небольшой текстовый файл, где разместил одинаковые и неодинаковые строки. С помощью этих команд эти дубликаты находились…
А именно в документе rockyou по прежнему нет, я решил в самом документе вручную добавить пару дубликатов что бы посмотреть, найдет ли он их. И действительно нашел, но помимо моих дубликатов нашлись и все остальные, как это понимать, почему только после редактирования файла в ручную дубликаты возможно было обнаружить?

Alexey :
Приветствую! Важное наблюдение. Дело в том, что файл rockyou.txt имеет несколько строк с неверными, с точки зрения UTF-8 символами, из-за которых команда uniq с опцией -d терпит неудачу. Очистим словарь от нечитаемых символов:
iconv -f utf-8 -t utf-8 -c rockyou.txt > rockyou_clean.txt
Подробности о проблеме, которую решает предыдущая команда, вы найдёте в статье «Как из текстового файла найти и удалить символы, отличные от UTF-8». А теперь можно вывести список дубликатов (в новом правильном файле):
cat rockyou_clean.txt | sort | uniq -d
Ваши действия (пересохранение файла) приводили к тому, что редактор сам удалял неправильные символы и после этого uniq -d начинала работать как надо.