- difference between grep Vs cat and grep
- 5 Answers 5
- Как вывести содержимое файла Linux? Открываем текстовый файл в Linux
- Просмотр текстового файла в Linux полностью
- Как просмотреть файл в Linux с прокруткой
- Просматриваем начало или конец файла в Linux
- Просматриваем содержимое файла по шаблону в Linux
- Просматриваем Linux-файл в сжатом виде
difference between grep Vs cat and grep
i would like to know difference between below 2 commands, I understand that 2) should be use but i want to know the exact sequence that happens in 1) and 2) suppose filename has 200 characters in it 1) cat filename | grep regex 2) grep regex filename
5 Answers 5
Functionally (in terms of output), those two are the same. The first one actually creates a separate process cat which simply send the contents of the file to standard output, which shows up on the standard input of the grep , because the shell has connected the two with a pipe.
Where you’ll start seeing the difference is in variants when the extra information (the file names) is used by grep , such as with:
grep -n regex filename1 filename2 The difference between that and:
cat filename1 filename2 | grep -n regex is that the former knows about the individual files whereas the latter sees it as one file (with no name).
While the former may give you:
filename1:7:line with regex in 10-line file filename2:2:another regex line the latter will be more like:
7:line with regex in 10-line file 12:another regex line Another executable that acts differently if it knows the file names is wc , the word counter programs:
$ cat qq.in 1 2 3 $ wc -l qq.in # knows file so prints it 3 qq.in $ cat qq.in | wc -l # does not know file 3 $ wc -l Normally cat opens file and prints its contents line by line to stdout. But here it outputs its content to pipe'|'. After that grep reads from pipe(it takes pipe as stdin) then if matches regex prints line to stdout. But here there is a detail grep is opened in new shell process so pipe forwards its input as output to new shell process.
Here grep directly reads from file(above it was reading from pipe) and matches regex if matched prints line to stdout.
+1: A pedant (e.g. me) might argue that cat always writes to its standard output, but in the context of the pipe, its standard output is the write end of a pipe. Similarly, when grep is invoked with no file name arguments, or when it processes a filename argument of - , it will read its standard input, which in this case, is the read end of the pipe. Note that pipe or | is not a command; it isn't quite clear whether you recognize that with 'so pipe forwards its input as output to new shell process'.
If you want to check the actual execution time diffrence, first create a file with 100000 lines:
user@server ~ $ for i in $(seq 1 100000); do echo line$ >> test_f; done user@server ~ $ wc -l test_f 100000 test_f user@server ~ $ time grep line test_f #. real 0m1.320s user 0m0.101s sys 0m0.122s user@server ~ $ time cat test_f | grep line #. real 0m1.288s user 0m0.132s sys 0m0.108s As we can see, the diffrence is not too big.
How much of the time you observed was due to the omitted output being written to screen? I tried with the output of grep redirected to /dev/null and got times of in the 10-50 ms range, not 1 second range. Now, my machine is no slouch, but 20 times as fast as yours seems unlikely (even allowing that the file is probably mostly in memory, not on disk). It is very hard to do good benchmarking. What I fear you are measuring is the time taken to write 100,000 lines to your terminal, rather than the raw performance of grep vs cat | grep .
For anyone who may be curious about the results with the above feedback, I just reran these using the same file as above, but with these timing commands: time grep line test_f > /dev/null and time (cat test_f | grep line > /dev/null) . The times are more in line with @JonathanLeffler 's results, but both commands still are almost the exact same speed.
Как вывести содержимое файла Linux? Открываем текстовый файл в Linux
Если вы работаете с операционной системой Linux, вы должны уметь быстро и правильно просматривать содержимое Linux-файлов, используя терминал. В этой статье мы изучим команды, посредством которых можно открывать текстовые файлы Linux. И поговорим о том, как следует ими пользоваться.
Просмотр текстового файла в Linux полностью
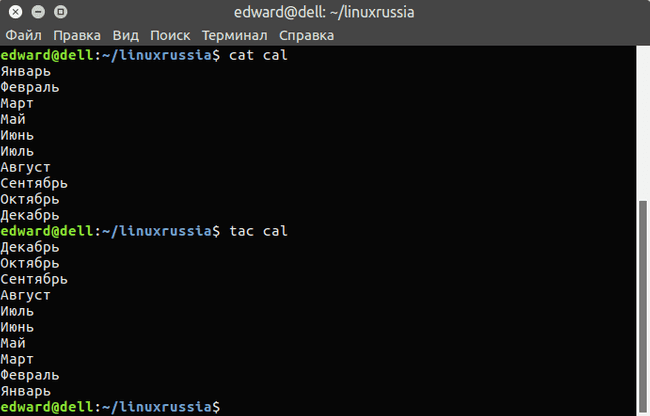
Чтобы вывести содержимое всего текстового файла, в Linux используют команду cat. Она отлично походит для вывода небольших текстовых файлов, к примеру, конфигурационных файлов. Синтаксис прост:
Представьте, что надо посмотреть содержимое файла с названием myfile.txt:
Также можно вместо имени прописать адрес (путь) к файлу:
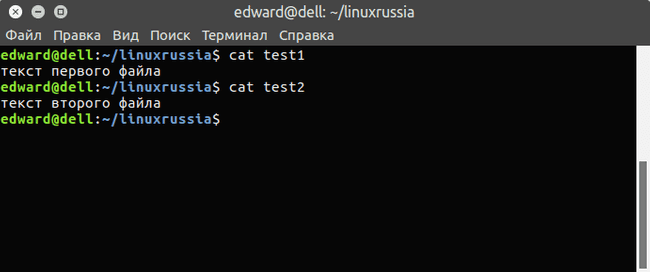
Если нужно посмотреть несколько файлов сразу, это тоже не вызовет проблем:
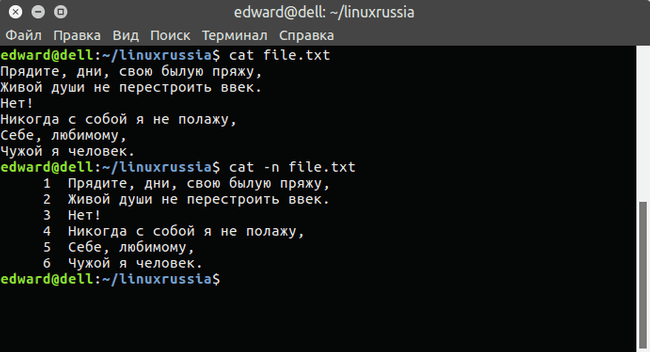
Кроме того, при просмотре текстового файла в Linux мы можем отобразить номера строк. Для этого потребуется всего лишь использовать опцию -n :
Команда nl функционирует аналогично команде cat с опцией -n , выводя номера строк в столбце слева.
При необходимости вы можете сделать так, чтобы при выводе текстового файла в конце каждой строки отображался символ $ :
hello everyone, how do you do?$ $ Hey, am fine.$Кроме cat, для вывода содержимого текстового файла в Linux используется команда tac. Её разница заключается в том, что она выводит содержимое файла в обратном порядке.
Как просмотреть файл в Linux с прокруткой
Бывает, что текстовый файл большой, поэтому его содержимое не помещается в один экран. Использовать в таком случае cat неудобно, зато есть less. Синтаксис у неё такой же:
Команда less обеспечит постраничный просмотр, что очень удобно. При этом: 1) less позволяет просматривать текст по определённому числу строк, для чего достаточно указать - (тире или минус) и количество строк:
2) можно начать просмотр с конкретной строки в файле, указав + (плюс) и номер строки, с которой хотим начать чтение:
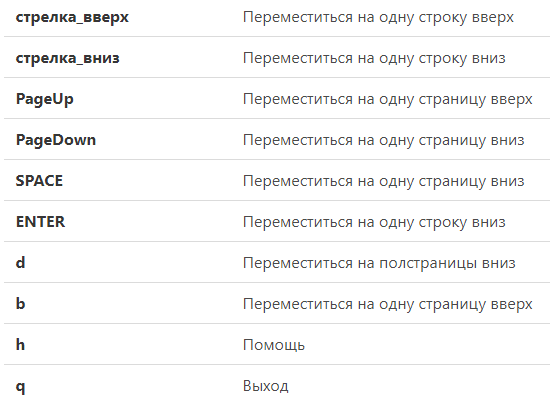
Открыв текст, мы можем управлять его просмотром:
Просматриваем начало или конец файла в Linux
Порой, нам не нужно выводить содержимое всего файла и мы хотим, к примеру, посмотреть лишь несколько строчек лога. Такое часто бывает, если мы подозреваем, что в начале или в конце конфигурационного файла есть ошибки. Для решения данного вопроса у нас существуют команды head и tail (как вы уже догадались, это голова и хвост).
Команда head по умолчанию показывает лишь 10 первых строчек в текстовом файле в Linux:
root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/bin/false daemon:x:2:2:daemon:/sbin:/bin/false adm:x:3:4:adm:/var/adm:/bin/false lp:x:4:7:lp:/var/spool/lpd:/bin/false sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt news:x:9:13:news:/var/spool/news:/bin/false uucp:x:10:14:uucp:/var/spool/uucp:/bin/falseКстати, тут мы тоже можем открыть сразу несколько текстовых файлов в Linux одновременно. Вот просмотр сразу двух файлов:
Если же вас не интересуют все 10 строчек, то, как и в случае с cat, можно использовать опцию –n , цифрой указывая число строк к выводу:
В итоге мы вывели только пять строк:
1394924012: Started emerge on: Mar 15, 2014 22:53:31 1394924012: *** emerge --sync 1394924012: === sync 1394924012: >>> Synchronization of repository 'gentoo' located in '/usr/portage'. 1394924027: >>> Starting rsync with rsync://212.113.35.39/gentoo-portageПо правде говоря, букву n можно и не использовать, достаточно просто передать цифру:
Кстати, выводить содержимое текстового файла в Linux можно не построчно, а посимвольно. Давайте зададим число символов, которое нужно вывести (используем опцию -с ):
1394924012: Started emerge on: Mar 15, 2014 2Не верите, что их действительно 45? Проверить можно командой wc:
head -c45 /var/log/emerge.log | wc -c 45С «головой» разобрались, давайте поговорим про «хвост». Очевидно, что команда tail работает наоборот, выводя десять последних строк текстового Linux-файла:
Количество строк при выводе тоже можно менять. Однако в tail есть такая полезная опция, как -f . С её помощью содержимое текстового файла будет постоянно обновляться, в результате чего вы станете видеть изменения сразу (постоянно открывать и закрывать файл не придётся). Это весьма удобно, если вы хотите просматривать логи Linux в реальном времени:
Просматриваем содержимое файла по шаблону в Linux
На практике зачастую нам необходим не весь текстовый файл, а лишь несколько строк из него. Используя grep, мы можем вывести Linux-файл, предварительно отсеяв лишнее:
Команду можно применять и совместно с cat:
cat файл | grep опции шаблонДавайте выведем из лога лишь предупреждения:
cat /var/log/Xorg.0.log | grep WW(WW) warning, (EE) error, (NI) not implemented, (??) unknown. [ 85.839] (WW) Hotplugging is on, devices using drivers 'kbd', 'mouse' or 'vmmouse' will be disabled. [ 85.839] (WW) Disabling Keyboard0 [ 85.839] (WW) Disabling Mouse0 [ 87.395] (WW) evdev: A4TECH USB Device: ignoring absolute axes.Есть и ряд полезных опций: -A , -B , -C . Допустим, нам надо выполнить вывод двух строк после вхождения enp2s0:
enp2s0: flags=4163 mtu 1500 inet 192.168.1.2 netmask 255.255.255.0 broadcast 192.168.1.255 inet6 fe80::beae:c5ff:febe:8bb7 prefixlen 64 scopeid 0x20
А теперь, то же самое, но до вхождения loop:
inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10 loop txqueuelen 0 (Local Loopback)Можно по две строки как до, так и после loop:
inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10 loop txqueuelen 0 (Local Loopback) RX packets 9810 bytes 579497 (565.9 KiB) RX errors 0 dropped 0 overruns 0 frameПросматриваем Linux-файл в сжатом виде
Порой, в системе встречаются текстовые файлы в сжатом виде и формате gz. Это могут быть конфигурационные файлы ядра либо логи программ. Открыть такие файлы можно тоже через терминал, не прибегая к распаковке. Для этого существует множество аналогов вышеназванных утилит с той лишь разницей, что они имеют приставку z: zgerp, zegrep, zcat, zless.
Давайте откроем сжатый файл в Linux для просмотра:
Или выполним просмотр сжатого файла с прокруткой:
Вот, пожалуй, и всё. Теперь вы точно в курсе, как правильно открывать и просматривать текстовые файлы в терминале Linux.