- Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
- Программы для определения кодировки в Linux
- Команда file -i показывает неверную кодировку
- Программа enca для определения кодировки файла
- Как определить кодировку строки
- Изменение кодировки в Linux
- Использование команды iconv
- Конвертирование файлов из windows-1251 в UTF-8 кодировку
- Изменение кодировки программой enca
- Конвертация строки в правильную кодировку
- How can I enable UTF-8 support in the Linux console?
- 3 Answers 3
Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Символ биты A 01000001 B 01000010
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или —mime, которые включают вывод строки с типом MIME. Пример:
file -i mypoem_draft.txt file -i mynovel.txt

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
enca mypoem_draft.txt enca mynovel.txt
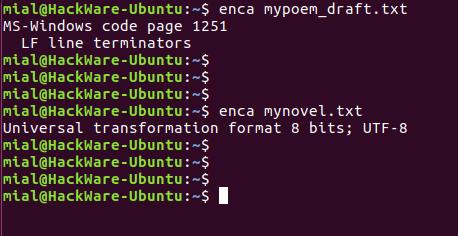
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
MS-Windows code page 1251 LF line terminators
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
enca -e mypoem_draft.txt CP1251/LF
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
enca -i mypoem_draft.txt CP1251
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
enca -m mypoem_draft.txt windows-1251
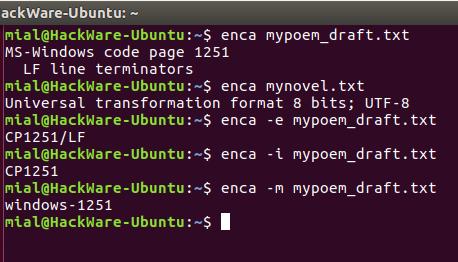
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
enca -m -L russian mypoem_draft.txt
Чтобы узнать список доступных языков наберите:
belarusian: CP1251 IBM866 ISO-8859-5 KOI8-UNI maccyr IBM855 KOI8-U bulgarian: CP1251 ISO-8859-5 IBM855 maccyr ECMA-113 czech: ISO-8859-2 CP1250 IBM852 KEYBCS2 macce KOI-8_CS_2 CORK estonian: ISO-8859-4 CP1257 IBM775 ISO-8859-13 macce baltic croatian: CP1250 ISO-8859-2 IBM852 macce CORK hungarian: ISO-8859-2 CP1250 IBM852 macce CORK lithuanian: CP1257 ISO-8859-4 IBM775 ISO-8859-13 macce baltic latvian: CP1257 ISO-8859-4 IBM775 ISO-8859-13 macce baltic polish: ISO-8859-2 CP1250 IBM852 macce ISO-8859-13 ISO-8859-16 baltic CORK russian: KOI8-R CP1251 ISO-8859-5 IBM866 maccyr slovak: CP1250 ISO-8859-2 IBM852 KEYBCS2 macce KOI-8_CS_2 CORK slovene: ISO-8859-2 CP1250 IBM852 macce CORK ukrainian: CP1251 IBM855 ISO-8859-5 CP1125 KOI8-U maccyr chinese: GBK BIG5 HZ none:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
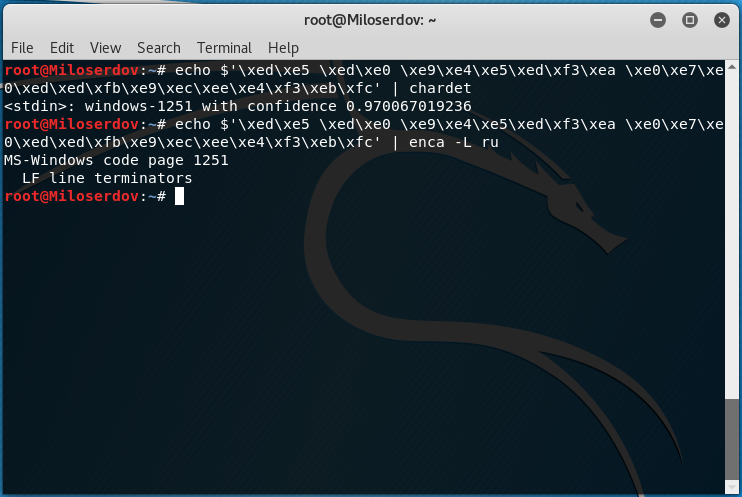
echo $'СТРОКА_ДЛЯ_ПРОВЕРКИ' | chardet
echo $'СТРОКА_ДЛЯ_ПРОВЕРКИ' | enca -L ru
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.
echo $'\xed\xe5 \xed\xe0 \xe9\xe4\xe5\xed\xf3\xea \xe0\xe7\xe0\xed\xed\xfb\xe9\xec\xee\xe4\xf3\xeb\xfc' | chardet : windows-1251 with confidence 0.970067019236
echo $'\xed\xe5 \xed\xe0 \xe9\xe4\xe5\xed\xf3\xea \xe0\xe7\xe0\xed\xed\xfb\xe9\xec\xee\xe4\xf3\xeb\xfc' | enca -L ru MS-Windows code page 1251 LF line terminators
Если возникло сообщение об ошибке:
bash: chardet: команда не найдена
то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
iconv опция iconv опции -f из-кодировки -t в-кодировку файл(ы) ввода -o файлы вывода
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
enca -i mypoem_draft.txt cat mypoem_draft.txt iconv -f CP1251 -t UTF-8//TRANSLIT mypoem_draft.txt -o poem.txt cat poem.txt enca -i poem.txt
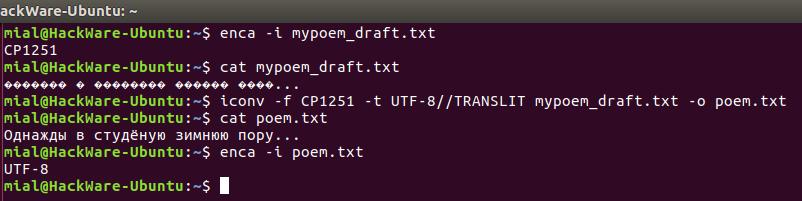
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном.
Внимание! Следующая команда изменяет исходный файл, при этом иногда его просто обнуляет. Поэтому обязательно начните с создания резервной копии:
cp mypoem_draft.txt mypoem_draft.txt.bac
Желаемую кодировку нужно указать после ключа -x:
enca -x UTF-8 mypoem_draft.txt
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:
echo $'СТРОКА_ДЛЯ_ИЗМЕНЕНИЯ_КОДИРОВКИ' | iconv -f 'ЖЕЛАЕМАЯ_КОДИРОВКА'
echo $'\xed\xe5 \xed\xe0\xe9\xe4\xe5\xed \xf3\xea\xe0\xe7\xe0\xed\xed\xfb\xe9 \xec\xee\xe4\xf3\xeb\xfc' | iconv -f 'Windows-1251' не найден указанный модуль

Также для изменения кодировки применяются программы:
How can I enable UTF-8 support in the Linux console?

Right now, it looks like this:
it’s a real 80×25 textmode terminal, so you can’t use more than 256 characters. Use framebuffer console if you want real utf-8.
3 Answers 3
Check that you have the locales package installed
you can navigate that list with the up/down arrow keys, for example choose en_US-UTF-8
edit your .bashrc by adding the following lines:
export LC_ALL=en_US.UTF-8 export LANG=en_US.UTF-8 export LANGUAGE=en_US.UTF-8 Run the locale command ,the output should be similar to this::
LANG=en_US.UTF-8 LANGUAGE=en_US:en LC_CTYPE="en_US.UTF-8" LC_NUMERIC="en_US.UTF-8" LC_TIME="en_US.UTF-8" LC_COLLATE="en_US.UTF-8" LC_MONETARY="en_US.UTF-8" LC_MESSAGES="en_US.UTF-8" LC_PAPER="en_US.UTF-8" LC_NAME="en_US.UTF-8" LC_ADDRESS="en_US.UTF-8" LC_TELEPHONE="en_US.UTF-8" LC_MEASUREMENT="en_US.UTF-8" LC_IDENTIFICATION="en_US.UTF-8" LC_ALL= I do have the package installed — I think it comes by default with Debian Wheezy. It’s just that the console wasn’t in UTF-8 mode.
Sure (it’s limited on the number of glyphs, but it seems your locale is using UTF-8 encoding).
#!/bin/sh # send character-string to enable UTF-8 mode if test ".$1" = ".off" ; then printf '\033%%@' else printf '\033%%G' fi and (calling it «utf8»), «utf8 on» turns the encoding on.
Using the example given with pstree , here is an example after running the script (before, the same sort of output as in the question):
As noted in a comment, there’s a script unicode_start which does more, but all that is needed to address the question posed is the small script used as an example.
Addressing a different comment: At least on my system (and in the screenshot shown in the question), all of the characters used by pstree are supplied in the 512-glyph font used by default for Unicode support in the Linux console.