3.2.2 Сетевая модель данных
Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных.
Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков.
В сетевой структуре при тех же понятиях уровень, узел, связь, каждый элемент может быть связан с любым другим элементом.
Сетевая модель СУБД во многом подобна иерархической: если в иерархической модели для каждого сегмента записи допускается только один входной сегмент при N выходных, то в сетевой модели для сегментов допускается несколько входных сегментов наряду с возможностью наличия сегментов без входов с точки зрения иерархической структуры.
Графическое изображение структуры связей сегментов такого типа моделей представляет собой сеть. Сегменты данных в сетевых БД могут иметь множественные связи с сегментами старшего уровня. При этом направление и характер связи в сетевых БД не являются столь очевидными, как в случае иерархических БД. Поэтому имена и направление связей должны идентифицироваться при описании БД.
Таким образом, под сетевой БД понимается система, поддерживающая сетевую организацию: любая запись, называемая записью старшего уровня, может содержать данные, которые относятся к набору других записей, называемых записями подчиненного уровня. Возможно обращение ко всем записям в наборе, начиная с записи старшего уровня. Обращение к набору записей реализуется по указателям.
Сетевые БД поддерживают сложные соотношения между типами данных, что делает их пригодными во многих различных приложениях. Однако пользователи таких БД ограничены связями, определенными для них разработчиками БД-приложений. Среди недостатков сетевых СУБД следует особо выделить проблему обеспечения сохранности информации в БД, решению которой уделяется повышенное внимание при проектировании сетевых БД.
Достоинства сетевой модели данных:
1)эффективное использование памяти;
Недостатки сетевой модели данных:
1) сложность доступа к элементам (навигационный принцип доступа);
2) сложно отследить смысл такой модели данных.
Сетевая модель данных изображена на рисунке 3.4.
Рисунок 3.4 – Сетевая модель данных
3.2.3 Реляционная модель данных
Реляционная модель данных — логическая модель данных, прикладная теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в реляционных базах данных. Понятие реляционный связано с разработками известного американского специалиста в области систем баз данных, сотрудника фирмы IBM Е. Кодда, которым впервые был применен термин «реляционная модель данных».
Термин «реляционный» означает, что теория основана на математическом понятии отношение (relation). В качестве неформального синонима термину «отношение» часто встречается слово таблица
В течение долгого времени реляционный подход рассматривался как удобный формальный аппарат анализа баз данных, не имеющий практических перспектив, так как его реализация требовала слишком больших машинных ресурсов. Только с появлением персональных ЭВМ реляционные и близкие к ним системы стали распространяться, практически не оставив места другим моделям.
Эти модели характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
- каждый элемент таблицы — один элемент данных; повторяющиеся группы отсутствуют;
- все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину;
- каждый столбец имеет уникальное имя;
- одинаковые строки в таблице отсутствуют;
- порядок следования строк и столбцов может быть произвольным.
- деревья (a) и (b), показанные на рис. 4.2, заменяются одной сетевой структурой, в которой запись СОТРУДНИК входит в два групповых отношения;
- для отображения типа M:N вводится запись СОТРУДНИК_КОНТРАКТ, которая не имеет полей и служит только для связи записей КОНТРАКТ и СОТРУДНИК, см. рис. 4.3 (Отметим, что в этой записи может храниться и полезная информация, например, доля данного сотрудника в общем вознаграждении по данному контракту.)
- произвольный,
- хронологический /очередь/,
- обратный хронологический /стек/,
- сортированный.
- Фиксированное. Подчиненная запись жестко связана с записью владельцем и ее можно исключить из группового отношения только удалив. При удалении записи–владельца все подчиненные записи автоматически тоже удаляются. В рассмотренном выше примере фиксированное членство предполагает групповое отношение «ЗАКЛЮЧАЕТ» между записями «КОНТРАКТ» и «ЗАКАЗЧИК», поскольку контракт не может существовать без заказчика.
- Обязательное. Допускается переключение подчиненной записи на другого владельца, но невозможно ее существование без владельца. Для удаления записи-владельца необходимо, чтобы она не имела подчиненных записей с обязательным членством. Таким отношением связаны записи «СОТРУДНИК» и «ОТДЕЛ». Если отдел расформировывается, все его сотрудники должны быть либо переведены в другие отделы, либо уволены.
- Необязательное. Можно исключить запись из группового отношения, но сохранить ее в базе данных не прикрепляя к другому владельцу. При удалении записи-владельца ее подчиненные записи — необязательные члены сохраняются в базе, не участвуя более в групповом отношении такого типа. Примером такого группового отношения может служить «ВЫПОЛНЯЕТ» между «СОТРУДНИКИ» и «КОНТРАКТ», поскольку в организации могут существовать работники, чья деятельность не связана с выполнением каких-либо договорных обязательств перед заказчиками.
Таблица такого рода называется отношением.
База данных, построенная с помощью отношений, называется реляционной базой данных.
Отношения представлены в виде таблиц, строки которых соответствуют записям, а столбцы – полям.
Поле, каждое значение которого однозначно определяет соответствующую запись, называется ключевым. Если записи однозначно определяются значениями нескольких полей, то такая таблица базы данных имеет составной ключ.
Достоинства реляционной модели:
1) простота и доступность понимания конечным пользователем — единственной информационной конструкцией является таблица;
2) при проектировании реляционной БД применяются строгие правила, базирующие на математическом аппарате;
3) полная независимость данных. При изменении структуры реляционной изменения, которые требуют произвести в прикладных программах, минимальны.
Недостатки реляционной модели:
1) относительно низкая скорость доступа и большой объем внешней памяти;
2) трудность понимания структуры данных из-за появления большого кол-ва таблиц в результате логического проектирования;
3) далеко не всегда предметную область можно представить в виде совокупности таблиц.
В последнее время всё большее количество БД основываются на РМ в виду её простоты и удобства, а также большого количества программных продуктов для разработки этой СУБД. И даже недостатки реляционной модели компенсируются ростом быстродействия и ресурсов памяти современных ЭВМ.
Для курсового проекта была выбрана реляционная модель данных. Для данной предметной области она является оптимальной, поскольку обладает такими свойствами, как удобство реализации, простота. Сетевая модель не подходит из-за сложного доступа к элементам и является довольно громоздкой, что затрудняет отслеживание смысла связей между объектами. В реляционной модели связи легко определимы. В иерархической модели данных отсутствует механизм, поддерживающий связи между элементами различных поддеревьев, что также может затруднить работу.
Реляционная модель данных представлена на рисунке 3.5. Таблица Аптека содержит название аптеки, № аптеки, адрес, телефон, лицензию. Таблица Изготовитель содержит название изготовителя, телефон, адрес. В таблице Тип хранится информация о названии типа медикамента. Таблица Препараты хранит названия препаратов дату изготовления, рецепт. Таблица Медикамент хранит информацию о названии медикамента и цену. Таблица Владелец хранит Ф.И.О. владельца, дату рождения, страховку. Таблица Поступает хранит информацию о дате поступления медикамента и количестве.
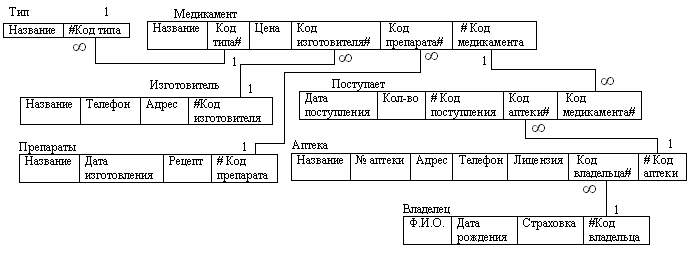
Рисунок 3.5 – Реляционная модель данных
Проанализировав типы моделей данных, я пришла к выводам, что удобнее реализовывать базу данных на основе реляционной модели.
Реляционная модель данных проста и удобна для понимания, в отличии от сетевой, где очень легко запутаться в связях между объектами и не так громоздка, как иерархическая модель.
Данные в реляционной модели не зависимы и при изменении структуры не требуется переделывать всю базу, как в иерархической и сетевой моделях. Также реляционная модель рассчитана на разнообразные типы запросов, в отличии от иерархической, ориентированной на конкретные запросы.
В настоящее время для разработки реляционной СУБД существует множество программных продуктов и систем поддержки. Все это делает разработку именно такой модели данных наиболее удобной.
Сетевая модель базы данных.
На разработку этого стандарта большое влияние оказал американский ученый Ч.Бахман. Основные принципы сетевой модели данных были разработаны в середине 60-х годов, эталонный вариант сетевой модели данных описан в отчетах рабочей группы по языкам баз данных (COnference on DAta SYstem Languages) CODASYL (1971 г.).
Сетевая модель данных определяется в тех же терминах, что и иерархическая. Она состоит из множества записей, которые могут быть владельцами или членами групповых отношений. Связь между записью-владельцем и записью-членом также имеет вид 1:N.
Основное различие этих моделей состоит в том, что в сетевой модели запись может быть членом более чем одного группового отношения. Согласно этой модели каждое групповое отношение именуется и проводится различие между его типом и экземпляром. Тип группового отношения задается его именем и определяет свойства общие для всех экземпляров данного типа. Экземпляр группового отношения представляется записью-владельцем и множеством (возможно пустым) подчиненных записей. При этом имеется следующее ограничение: экземпляр записи не может быть членом двух экземпляров групповых отношений одного типа (т.е. сотрудник из примера в п..1, например, не может работать в двух отделах).
Иерархическая структура рис.4.2 преобразовывается в сетевую следующим образом (см. рис. 4.3):
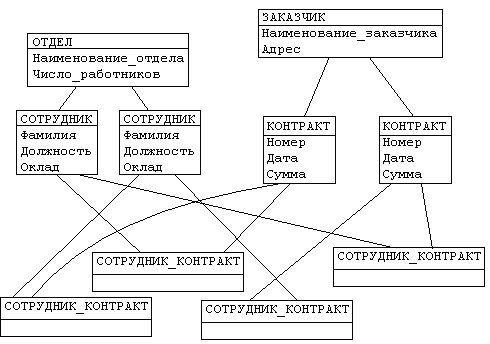
Рисунок 4.3. Сетевая модель базы данных Каждый экземпляр группового отношения характеризуется следующими признаками: способ упорядочения подчиненных записей:
Если запись объявлена подчиненной в нескольких групповых отношениях, то в каждом из них может быть назначен свой способ упорядочивания. режим включения подчиненных записей: автоматический — невозможно занести в БД запись без того, чтобы она была сразу же закреплена за неким владельцем; ручной — позволяет запомнить в БД подчиненную запись и не включать ее немедленно в экземпляр группового отношения. Эта операция позже инициируется пользователем). режим исключения. Принято выделять три класса членства подчиненных записей в групповых отношениях: