Разворачиваем MPI кластер на Linux
Сейчас любое серьезное приложение, работающее в продуктивной среде, требует обеспечение высокого уровня надежности функционирования. Обеспечение такой надежности требует использования ряда средств, таких как отказоустойчивые каналы связи, наличие дублирования источников питания и т. д. Но наиболее важным элементом обеспечения надежности является создание отказоустойчивой конфигурации серверов, на которых работает данное приложение.
Совершенно очевидно, что если приложение запущено на одном сервере, то в случае его отказа приложение будет недоступно до тех пор, пока не будет исправлен сбой сервера. Основная задача кластеризации это устранение данной ситуации с помощью своевременного, обнаружения аппаратных и программных сбоев и немедленно переключение на другой узел кластера – это процесс, известный как отработка отказа.
Существует много различных вариантов создания кластеров под Linux. Мы будем использовать MPI (Message Passing Interface) для обеспечения взаимодействия между узлами нашего кластера.
Установка на Ubuntu Linux
Перед началом создания собственного двухузлового кластера нам потребуются два сервера с установленной ОС Ubuntu 22.04. Между этими узлами нам необходимо установить прямое соединение для обмена heartbeat. Каждому из этих сетевых интерфейсов необходимо назначить статический IP адрес. У нас это будут 10.0.0.1 (node_1) и 10.0.0.2 (node_2).
Далее я буду предполагать, что у вас уже установлен SSH сервер. Если это по какой-то причине не так, то установите SSH на оба узла с помощью команды:
sudo apt install openssh-server
Первое, что нам потребуется сделать это настроить беспарольный доступ по SSH с помощью сертификатов. Выполним следующую команду:
sudo ssh-keygen -t rsa -b 4096
После ее запуска вам будут заданы несколько вопросов, на которые можно ответить предлагаемыми значениями по умолчанию. В результате будут созданы два файла ~/.ssh: id_rsa и id_rsa.pub. Последний является открытым ключом. Содержимое этого файла необходимо скопировать в файл ~/.ssh/authorized-keys на удаленном компьютере. Это можно сделать к примеру с помощью утилиты scp.
scp ~/.ssh/authorized_keys 10.0.0.2:~/.ssh/
Аналогичные действия необходимо проделать на втором узле и скопировать сгенерированный ключ в настройки SSH на первом сервере.
Устанавливаем протокол коммуникаций
Далее для работы нашего кластера нам потребуется установить средство для обмена сообщениями. Мы будем использовать MPI (Message Passing Interface) – стандартный коммуникационный протокол для распределенных вычислений. Не вдаваясь в технические особенности и версии данного протокола установим на обоих узлах одну из реализаций MPI с помощью команды:
sudo apt install libopenmpi-dev
После этого нам необходимо проверить возможность выполнять команды на удаленном узле. Для этого выполним следующее на узле 10.0.0.1:
mpirun -np 2 -host 10.0.0.2:2 hostname
В результате нам должен быть выведен на экран результат выполнения данной команды, то есть имя второго узла.
Для удобства работы с узлами кластера рекомендуется прописать в файле /etc/hosts соответствие IP адресов каждого из узлов и их имен:
10.0.0.2 node_2 10.0.0.1 node_1Есть причина, по которой мы до сих пор использовали команду hostname: она доступна по умолчанию во всех системах. При использовании MPI важно помнить, что мы, по сути, используем сетевое подключение только для того, чтобы позволить нескольким запущенным заданиям взаимодействовать друг с другом. Однако каждое задание выполняется на своем собственном компьютере, имеющем доступ к своему собственному жесткому диску. Это, в частности, означает, что команда для запуска должна существовать на всех компьютерах и в одном и том же расположении.
Таким образом, для совместного выполнения задач и обмена результатом нам необходим общий ресурс. В данном случае мы будем использовать файловую систему NFS.
Для установки ее компонентов на узле node_1 выполним следующую команду:
sudo apt install nfs-kernel-server nfs-common
Далее вам нужно создать точку монтирования для общего каталога. Будем расшаривать домашний каталог пользователя user на node_1.
Далее на том же node_1 добавим в файл /etc/exports строку для доступа со второй ноды:
На узле node_2 создадим каталог /nfs
И добавим в fstab следующую запись:
. 10.0.0.1:/home/user /nfs nfs defaults 0 0Далее выполним монтирование:
Если монтирование завершилось успешно, то мы можем перейти в папку nfs и увидеть содержимое, реально находящееся на node_1.
drwxr-xr-x 80 user user 12288 Sep 7 14:17 .
drwxr-xr-x 25 root root 4096 Aug 27 06:19 ..
Таким образом мы получили кластерную конфигурацию в которой мы можем выполнять команды на каждом из узлов и использовать общую файловую шару для взаимодействия между нодами.
Заключение
В этой статье мы рассмотрели один из вариантов создания кластера на Ubuntu, с помощью которого затем можно реализовать выполнение различных вычислительных задач.
В завершение порекомендую открытый урок, посвященный настройке Nginx для высоких нагрузок и защиты от DoS-атак. Узнать подробнее и записаться можно по ссылке.
Introduction and Advantages/Disadvantages of Clustering in Linux – Part 1
Hi all, this time I decided to share my knowledge about Linux clustering with you as a series of guides titled “Linux Clustering For a Failover Scenario“.

Following are the 4-article series about Clustering in Linux:
First of all, you will need to know what clustering is, how it is used in industry and what kind of advantages and drawbacks it has etc.
What is Clustering
Clustering is establishing connectivity among two or more servers in order to make it work like one. Clustering is a very popular technic among Sys-Engineers that they can cluster servers as a failover system, a load balance system or a parallel processing unit.
By this series of guide, I hope to guide you to create a Linux cluster with two nodes on RedHat/CentOS for a failover scenario.
Since now you have a basic idea of what clustering is, let’s find out what it means when it comes to failover clustering. A failover cluster is a set of servers that works together to maintain the high availability of applications and services.
For an example, if a server fails at some point, another node (server) will take over the load and gives end user no experience of down time. For this kind of scenario, we need at least 2 or 3 servers to make the proper configurations.
I prefer we use 3 servers; one server as the red hat cluster enabled server and others as nodes (back end servers). Let’s look at below diagram for better understanding.
Cluster Server: 172.16.1.250 Hostname: clserver.test.net node01: 172.16.1.222 Hostname: nd01server.test.net node02: 172.16.1.223 Hostname: nd02server.test.net
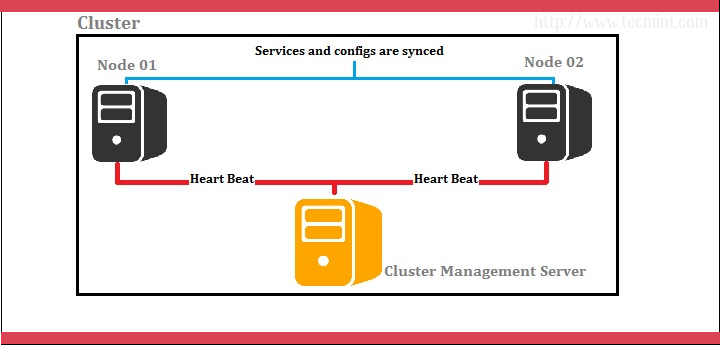
In above scenario, cluster management is done by a separate server and it handles two nodes as shown by the diagram. Cluster management server constantly sends heartbeat signals to both nodes to check whether if anyone is failing. If anyone has failed, the other node takes over the load.
Advantages of Clustering Servers
- Clustering servers is completely a scalable solution. You can add resources to the cluster afterwards.
- If a server in the cluster needs any maintenance, you can do it by stopping it while handing the load over to other servers.
- Among high availability options, clustering takes a special place since it is reliable and easy to configure. In case of a server is having a problem providing the services furthermore, other servers in the cluster can take the load.
Disadvantages of Clustering Servers
- Cost is high. Since the cluster needs good hardware and a design, it will be costly comparing to a non-clustered server management design. Being not cost effective is a main disadvantage of this particular design.
- Since clustering needs more servers and hardware to establish one, monitoring and maintenance is hard. Thus increase the infrastructure.
Now let’s see what kind of packages/installations we need to configure this setup successfully. The following packages/RPMs can be downloaded by rpmfind.net.
- Ricci (ricci-0.16.2-75.el6.x86_64.rpm)
- Luci (luci-0.26.0-63.el6.centos.x86_64.rpm)
- Mod_cluster (modcluster-0.16.2-29.el6.x86_64.rpm)
- CCS (ccs-0.16.2-75.el6_6.2.x86_64.rpm)
- CMAN(cman-3.0.12.1-68.el6.x86_64.rpm)
- Clusterlib (clusterlib-3.0.12.1-68.el6.x86_64.rpm)
Let’s see what each installation does for us and their meanings.
- Ricci is a daemon which used for cluster management and configurations. It distributes/dispatches receiving messages to the nodes configured.
- Luci is a server that runs on the cluster management server and communicates with other multiple nodes. It provides a web interface to make things easier.
- Mod_cluster is a load balancer utility based on httpd services and here it is used to communicate the incoming requests with the underlying nodes.
- CCS is used to create and modify the cluster configuration on remote nodes through ricci. It is also used to start and stop the cluster services.
- CMAN is one of the primary utilities other than ricci and luci for this particular setup, since this acts as the cluster manager. Actually, cman stands for CLUSTER MANAGER. It is a high-availability add-on for RedHat which is distributed among the nodes in the cluster.
Read the article, understand the scenario we’re going to create the solution to, and set the pre-requisites for the implementation. Let’s meet with the Part 2, in our upcoming article, where we learn How to install and create the cluster for the given scenario.
References:
Keep connected with Tecmint for handy and latest How To’s. Stay Tuned up for the part 02 (Linux Servers clustering with 2 Nodes for a failover scenario on RedHAT/CentOS – Creating the cluster) soon.