- How to Convert PDF to Image in Linux Command Line
- 1. Convert PDF Document to Image
- 2. Convert Range of PDF Pages to Images
- 3. Convert First PDF Page to Image
- 4. Adjust DPI Quality to Conversion
- How can I convert a series of images to a PDF from the command line on Linux? [closed]
- 2 Answers 2
- How to Convert Image to PDF on Linux Command Line
- 1. ImageMagick
- 2. Img2PDF
- Conclusion
- About the author
- Denis Kariuki
- How To Convert PDF To Text On Linux (GUI And Command Line)
- Convert PDF to text with pdftotext (command line)
How to Convert PDF to Image in Linux Command Line
pdftoppm converts PDF document pages to image formats like PNG, and others. It is a command-line tool that can convert an entire PDF document into separate image files. With pdftoppm, you can specify the preferred image resolution, scale, and crop your images.
To use the pdftoppm command-line tool, you need to first install pdftoppm which is a part of the poppler / poppler-utils / poppler-tools package. Install this package as follows depending on your Linux distribution
$ sudo apt install poppler-utils [On Debian/Ubuntu & Mint] $ sudo dnf install poppler-utils [On RHEL/CentOS & Fedora] $ sudo zypper install poppler-tools [On OpenSUSE] $ sudo pacman -S poppler [On Arch Linux]
Below are examples of how you can use the pdftoppm tool to convert your pdf files to images:
1. Convert PDF Document to Image
The syntax for converting an entire pdf is as follows:
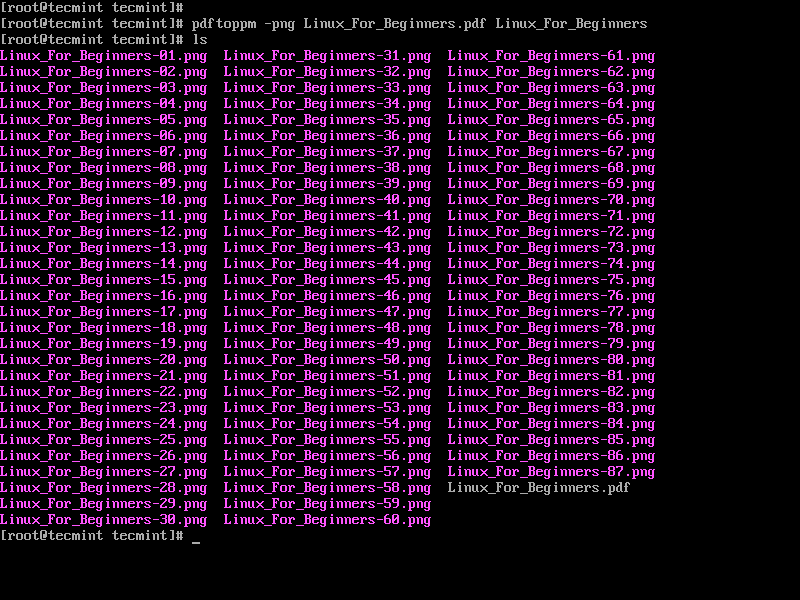
In the example below, the name of my document is Linux_For_Beginners.pdf and we will convert it to PNG format and name the images as Linux_For_Beginners.
$ pdftoppm -png Linux_For_Beginners.pdf Linux_For_Beginners
Each page of the PDF will be converted to PNG as Linux_For_Beginners-1.png, Linux_For_Beginners-2.png, etc.
2. Convert Range of PDF Pages to Images
The syntax for specifying range is as follows:
$ pdftoppm — -f N -l N $ pdftoppm — -f N -l N
Where N specifies the first-page number to covert and -l N for the last page to convert.
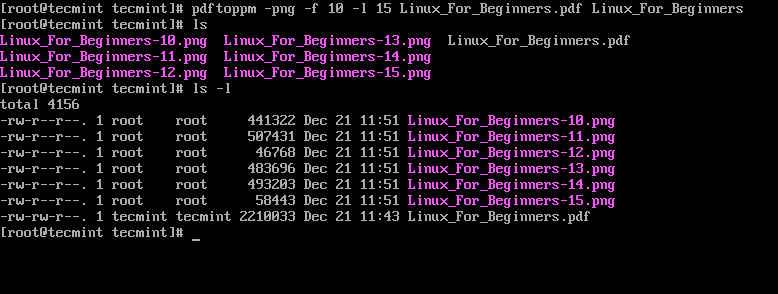
In the example below, we will convert pages 10 to 15 from Linux_For_Beginners.pdf to PNG.
$ pdftoppm -png -f 10 -l 15 Linux_For_Beginners.pdf Linux_For_Beginners
The output will be images named Linux_For_Beginners-10.png, Linux_For_Beginners-11.png, etc.
3. Convert First PDF Page to Image
To convert the first page only use the syntax below:
$ pdftoppm -png -f 1 -l 1 Linux_For_Beginners.pdf Linux_For_Beginners
4. Adjust DPI Quality to Conversion
Pdftoppm converts PDF pages to images with a DPI of 150 by default. To adjust, use the rx number which specifies the X resolution, and -ry the number which specifies the Y resolution, in DPI.
In this example, we adjust the DP quality of Linux_For_Beginners.pdf to 300.
$ pdftoppm -png -rx 300 -ry 300 Linux_For_Beginners.pdf Linux_For_Beginners
To see all the choices available and supported in pdftoppm, run the commands:
$ pdftoppm --help $ man pdftoppm
Hopefully, you can now convert your PDF pages to images in Linux using the Pdftoppm command-line tool.
How can I convert a series of images to a PDF from the command line on Linux? [closed]
I have a scanning server I wrote in CGI and Bash. I want to be able to convert a bunch of images (all in one folder) to a PDF from the command line. How can that be done?
Use img2pdf, not ImageMagick. ImageMagick decodes the JPEG, resulting in generation loss and is 10–100 times slower than img2pdf.
img2pdf $(find . -iname ‘*.jpg’ | sort -V) -o ./document.pdf will give you document.pdf containing all images with jpg or JPG extension in the current dir — one image per page. document.pdf will have all images ordered as pages naturally ( -V option for sort ) so there is no need to add any leading zeros when numbering image files.
2 Answers 2
what if page*.png does not sort the images in the way you want ? e.g. page_1.png, page_2.png . page_10.png -> page_10 will appear before page_1
To sort the files, you can use: ls page*.png | sort -n | tr ‘\n’ ‘ ‘ | sed ‘s/$/\ mydoc.pdf/’ | xargs convert
FYI you almost never need to use ls for anything apart from displaying files. i.e. do not parse it’s output. find is a much more suitable tool. Here is an example convert $(find -maxdepth 1 -type f -name ‘page*.png’ | sort -n | paste -sd\ ) output.pdf . Keep in mind that the aforementioned command will not work if your pathnames contain spaces. The addition of characters that need to be escaped makes things a little more complicated.
This is simple and works very well, thank you! To avoid generating huge PDF files, use something like convert -compress jpeg -quality 85 *.png out.pdf
ImageMagick decodes the JPEG, resulting in generation loss. Use img2pdf instead; it’s also 10–100 times faster.
How to Convert Image to PDF on Linux Command Line
![]()
Often, you may need to convert or add the images to the PDF files, especially if you have an application and you want the users to download the images as PDF files.
There are different online tools that convert the images to PDF. But security is always a concern, and you can’t trust these online sites with your data. The best method is to convert the images on your machine. Linux offers various command-line utilities to aid you with that. The two common tools are Img2PDF and ImageMagick.
1. ImageMagick
ImageMagick stands out for the image conversion to PDF for its fast speed. The open-source Linux tool utilizes the multiple CPU threads to keep the conversion process fast. Whether converting one image or multiple images, ImageMagick gets the job done.
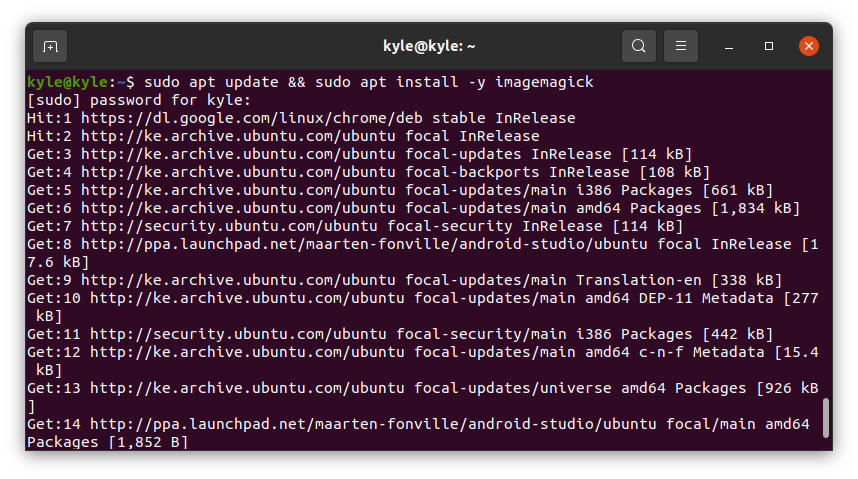
Let’s first install ImageMagick using the following command:
$ sudo apt install -y imagemagick
For Fedora users, the command is as follows:
With the ImageMagick already installed, navigate to the directory containing your pictures. We have different images in our example. We will see how we can convert them one by one and how to convert them all at once.
The syntax for conversion is as following:
Note that we are using convert, a utility for ImageMagick. Let’s start by converting one image.
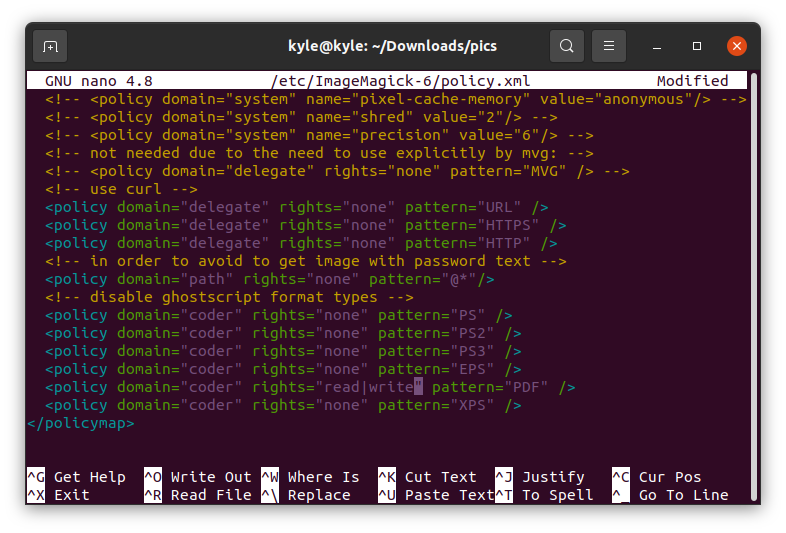
If you run the previous convert command, it should work fine. However, you may end up with an error message like the one reflected in the following image:
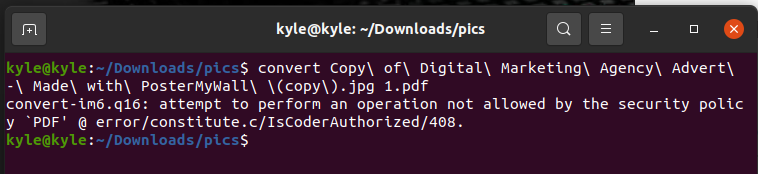
In that case, all you need is to edit the policy.xml file using an editor like nano.
Look for the line in the following example:
To fix the error, replace the rights from “none” to “read|write”
Save the file and rerun the command. You will now have a PDF file of the converted image.
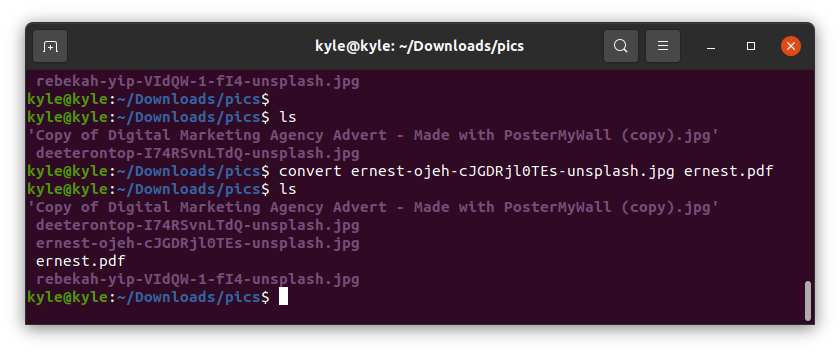
To convert all the images in the current directory to PDF, you can add their names one by one or select the image format if they are the same. In our case, the image formats are in “.jpg”. In this case, our command is as follows:
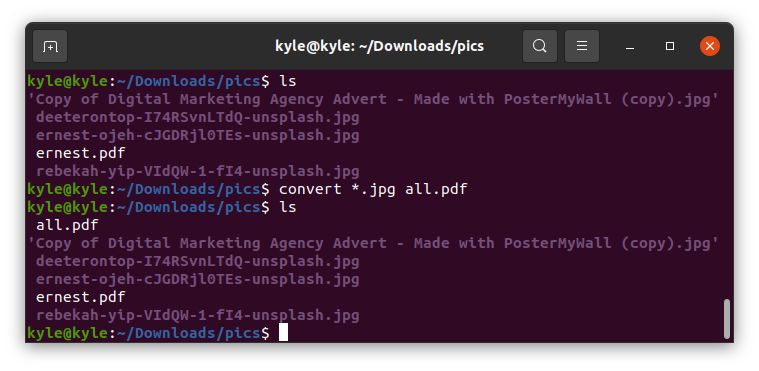
That’s it! You now have all your images converted into one PDF.
ImageMagick is a great tool for converting the images to PDF on the command line. The only bad side of it is that the resolution for the images changes and the PDF file doesn’t have the full resolution, reducing the image quality.
 2. Img2PDF
2. Img2PDF
 2. Img2PDF
2. Img2PDFThe ImageMagick converts the images to PDF, but the quality of the images reduces. The alternative is to use the Img2PDF to convert the same photos without losing the image quality. Besides, Img2PDF allows the specification of the image size when converting.
Start by installing Img2PDF using the following command:
You can verify the installation by checking the version.

Img2PDF can also be installed using pip in other distributions:
With the tool installed, let’s proceed to convert our images. We use the same pictures as we did with ImageMagick. First, navigate to the directory that contains your images. To convert a single file, use the following syntax:

We now have a PDF version of the image. If you want to convert multiple images, you can list them all. Or if they have the same format, use the * shorthand like in the following example:

To specify the page size or the image size for the output, use the –imgsize or –pagesize.
For instance, to specify the image size to 30cm by 45cm, the command is:

Conclusion
Converting the images of different formats to PDF shouldn’t trouble you when using Linux. There are command-line utilities at your disposal, and the syntax is easy. This guide has presented two utilities, Img2PDF and ImageMagick, that you can use to convert either one or multiple images to PDF.
About the author
Denis Kariuki
Denis is a Computer Scientist with a passion for Networking and Cyber Security. I love the terminal, and using Linux is a hobby. I am passionate about sharing tips and ideas about Linux and computing.
How To Convert PDF To Text On Linux (GUI And Command Line)

Calibre is a free and open source e-book software suite. It supports organizing, displaying, editing, and converting e-books, supporting a wide range of formats. The application runs on Linux, macOS, and Microsoft Windows.
Calibre should be available in your Linux distribution’s repositories, and you should be able to install it using whatever software store you have on your system. For example, to install it on Debian, Ubuntu, Linux Mint, Fedora, openSUSE, or Arch Linux, use:
sudo zypper install calibreCalibre may also be installed on Linux by using the Flathub package (requires setting up Flathub / Flatpak on some Linux distributions).
There’s yet another way to install Calibre on Linux explained on the application’s downloads page, where you’ll also find macOS and Windows binaries.
Now that Calibre is installed on your system, launch it and click Add books to add the PDF (or multiple PDFs — Calibre supports batch converting multiple PDF files to text) you want to convert to text.
From the list of books, select the PDF (or multiple PDFs for batch conversion to .txt) you want to convert to text, and click the Convert books button. In the upper right-hand side of the conversion window, choose TXT as the Output format :
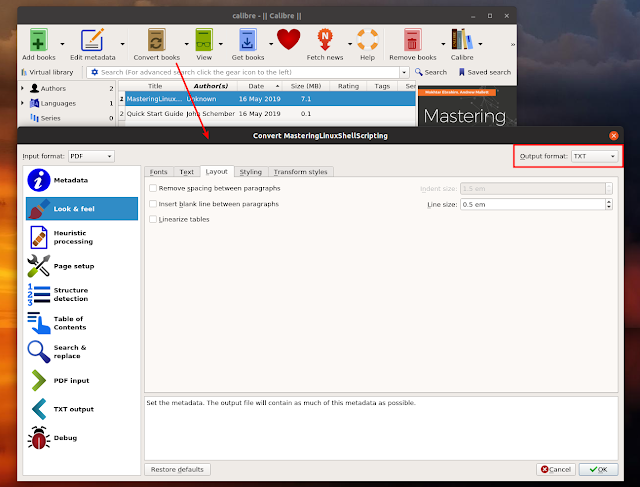
What Calibre lacks in this case is a way to only convert a page or a page range — it can currently only convert entire PDF files to text.
Convert PDF to text with pdftotext (command line)
pdftotext is a command line utility that converts PDF files to plain text. It has many options, including the ability to specify the page range to convert, maintain the original physical layout of the text as best as possible, set line endings (unix, dos or mac), and even work with password-protected PDF files.
pdftotextis part of the poppler / poppler-utils / poppler-tools package (depending on the Linux distribution you’re using). Install this package as follows:
sudo apt install poppler-utilssudo dnf install poppler-utilssudo zypper install poppler-toolsIn other Linux distributions use your package manager to install the poppler / poppler-utils package.
Now that the package is installed, you can convert a PDF file to plain text and preserve its layout (I recommend using this -layout option for maintaining the original physical layout, but you can try it without it too) with:
pdftotext -layout input.pdf output.txtYou’ll need to replace input.pdf with the name of the PDF file, and output.txt with the name you want the generated TXT file to be called. Also add the paths before filenames if needed (e.g. ~/Documents/mypdf.pdf ). If no output text file is specified, pdftotext will name the file with the same file name as the original PDF file.
The layout option preserves the PDF layout when converting it to text, even if multi-column PDF cases.
What if you want to only convert a page range of the PDF to text, instead of the whole PDF file? Use -f (first page to convert) and -l (last page to convert) followed by the page number, like this:
pdftotext -layout -f M -l N input.pdfReplace M and N with the first and last page number to extract, and input.pdf with the PDF filename.
Want to use mac, dos or unix end-of-line characters? You can specify that too, using -eol followed by mac , dos or unix . E.g. for unix line endings:
pdftotext -layout -eol unix input.pdfpdftotext -layout nopgbrk input.pdfWant to batch convert all PDF files from a folder to text files? pdftotext doesn’t support batch PDF to text conversion (and pdftotext *.pdf doesn’t work), but you can convert all the PDF files in a folder to text files by using a Bash FOR loop:
for file in *.pdf; do pdftotext -layout "$file"; doneFor more options, run man pdftotext and pdftotext —help .