- How to convert .xlsx to .txt?
- 7 Answers 7
- Convert doc to txt via commandline
- 4 Answers 4
- Convert binary mode to text mode and the reverse option
- 3 Answers 3
- 3 Ways of .odt to .txt File Conversion in Command Line in Linux
- .odt to .txt file conversion using LibreOffice
- Convert .odt to .txt file using pandoc
- Convert .odt to Markdown .txt file using pandoc
- Summary
How to convert .xlsx to .txt?
Not a very clear question to be honest. What do you have in the file? Just data? Or are there charts, macros, etc. as well?
There are lots of them available online. xlsx is a proprietary (and a relatively new) format so the effectiveness of open source tools will be limited I think. Try tinyurl.com/2vbb7m5
7 Answers 7
The ssconvert tool that comes with Gnumeric can convert xlsx files to text:
ssconvert Book1.xlsx file.csv Another way is rename it as .zip and unzip it as all the .***x files are just zipped folders containing xml. Inside you will find a folder «xl» with a subfolder «worksheets», inside is an xml file for each worksheet. The format of them is pretty simple and should be easy to parse with any of the xml packages.
+1 interesting. I’m looking at these XML files now, and at least in this case it is more complicated than you imply — sheet1.xml doesn’t have any actual text in, but seems to refer to another XML file called sharedStrings.xml, which is where the «content» of the file is stored.
If it’s just textual/numerical data (which I have to assume it is, otherwise a text file would be a bit ambitious), then you could try xlsx2csv to generate CSV files from your spreadsheets.
I can’t vouch for its effectiveness, but it’s worth a try.
I do not know about a tool in linux, but you can use Google Docs.
You upload the spreadsheet there and you can then export it as txt.
Not a shell script, (unlike the script mentioned in Andy’s post from Oct 20 ’10 at 8:44), but a python script:
This exports date values as floats though:
«2012/07/01 01:00:00» => 41091.0416666667
xlsx2csv.py --help Usage: xlsx2csv.py [options] infile [outfile] Options: --version show program's version number and exit -h, --help show this help message and exit -s SHEETID, --sheet=SHEETID sheet no to convert (0 for all sheets) -d DELIMITER, --delimiter=DELIMITER delimiter - csv columns delimiter, 'tab' or 'x09' for tab (comma is default) -p SHEETDELIMITER, --sheetdelimiter=SHEETDELIMITER sheets delimiter used to separate sheets, pass '' if you don't want delimiters (default '--------') -f DATEFORMAT, --dateformat=DATEFORMAT override date/time format (ex. %Y/%m/%d) -i, --ignoreempty skip empty lines -r, --recursive convert recursively Convert doc to txt via commandline
We’re searching a programm that allows us to convert a doc or docx document to a txt file. We’re working with linux and we want to start a website that converts user uploaded doc files. We don’t wanna use open office/libre office cause we have bad experience with that. Pandoc can’t handle doc files :/ Anyone have a idea?
4 Answers 4
You will have to use two different command-line tools, depending if you are working with .doc or .docx format.
The latter will produce a file called foo.txt in the same directory as the original.
I’m not sure which Linux distribution you are using, but both catdoc and docx2txt are available from the Ubuntu repositories, for example:
Thanks for the info, unfortunately for me brew install docx2txt didn’t work, ‘catdoc’ command is not available and I need to use ‘docx2txt.sh’ instead of ‘docx2txt’.
It turns out catdoc got delegated to the boneyard but one can build it from source, details here: apple.stackexchange.com/a/294259/36790
here is a perl project which claims to do it. I have done a lot of this by hand also, using XSLT on the document.xml. the Docx file itself is just a zip file, you can unzip it and inspect the elements. I will say that this is not hard to do for specific files, but is very hard to do in the general case, because of the lack of documentation for how Word internally stores things, and the variance of internal representation.
Convert binary mode to text mode and the reverse option
What leads you to believe it’s still a text file? xxd -r -p is the exact reverse of the od conversion you did; the output of cuonglm’s command should be strictly identical to the original tarball.
3 Answers 3
od -An -vtx1 Check.tar > Check.txt You need -v or od will condense sequences of identical bytes.
LC_ALL=C tr -cd 0-9a-fA-F < Check.txt | xxd -r -p >Check.tar perl -ape '$_=pack "(H2)*", @F' Check.txt > Check.tar If your purpose is to transfer files over a channel that only supports ASCII text, then there are dedicated tools for that like uuencode :
tar cf - myfiles.* | xz | uuencode myfiles.tar.xz | that-channel And to recover those files on the other end:
would recreate myfiles.tar.xz .
@maihabunash If you created file.txt without -v and with removing the address, then you can’t reliably recover file.tar if there were condensed sequences (do a grep ‘[*]’ file.txt to check) as you’ve lost the information of how long those condensed sequences were by removing the address.
hi , my target is to compress more then 30 perl script with tar or zip or whatever then convert it to text and then convert it back to compressed file , is it possible? ( I see tar is problem but can we do it with other options )
@maihabunash, you’re looking for uuencode or base64 encoding. Note that my answer covers your question. I give the code to convert back to binary from od output provided you don’t forget the -v option. If you’re transferring files over FTP, don’t forget to set the mode to «binary» ( TYPE I FTP command, something like binary in your client)
@pmor, It looks like you want the output of xxd -p which can be decoded with xxd -r -p . the tr | xxd -r -p approach already removes all whitepace (anything but xdigits). perl -pe ‘chomp;$_=pack»H*»,$_’ to decode the output of xxd -p
Answering the X part of this XY problem, I would recommend you investigate the reason your binary file transfers don’t transfer properly.
If it turns out the reason is because you don’t have an 8-bit clean datapath you could then use existing tools that were created to handle this situation, such as base64 or even uuencode . Old but still very effective.
tar czvf - /etc/h* | base64 >/tmp/tar.tgz.b64 ls -l /tmp/tar.tgz.b64 -rw-r--r-- 1 root root 7364 May 26 11:52 /tmp/tar.tgz.b64 . base64 -d /tmp/tar.tgz.b64 | tar tzvf - tar czvf - /etc/h* | uuencode - >/tmp/tar.tgz.uue ls -l /tmp/tar.tgz.uue -rw-r--r-- 1 root root 7530 May 26 11:51 /tmp/tar.tgz.uue . uudecode /tmp/tar.tgz.uue | tar xzvf - 3 Ways of .odt to .txt File Conversion in Command Line in Linux
The Open Document .odt files can contain rich formats for the content. However, some times a plain text file is more handy. We may convert .odt files to plain text files for such needs. In this post, we discuss 3 ways of how to convert .odt files to .text files in command line in Linux. The ways here can be easily organized into a Bash script to do batch processing of a set of files too. Together with the ways of .docx/.doc to .odt File Conversion in Command Line in Linux, the methods here can be used to do .docx/.doc to plain text file conversion.
We use the LibreOffice and pandoc software. Make sure the software packages are installed in the Linux system. As an example, we use a .odt file as follows.
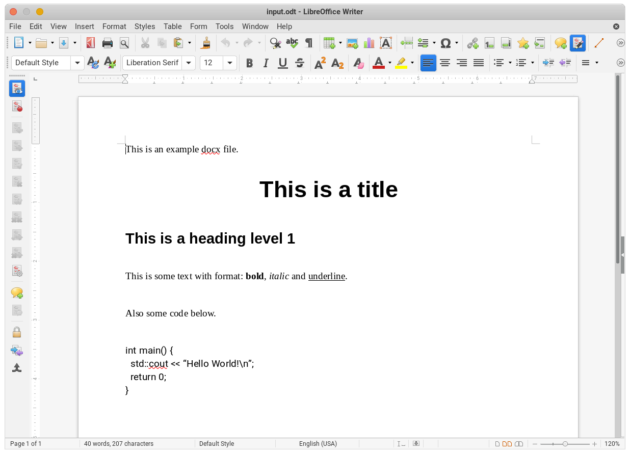
As shown in the following examples, different ways have different pros/cons. In actual usage, we may choose one suitable way or combine the results from different ways together according to the files or the purposes.
.odt to .txt file conversion using LibreOffice
We can use the —convert-to feature of the LibreOffice software to conver the .odt file to .txt file. The command to convertt the .odt file to .txt file is as follows.
$ libreoffice --convert-to txt input.odt convert /home/davidy/Downloads/input.odt -> /home/davidy/Downloads/input.txt using filter : TextThe converted .txt file looks like this.
$ cat input.txt This is an example docx file. This is a title This is a heading level 1 This is some text with format: bold, italic and underline. Also some code below. int main()
Here, we can see all the text including spaces (those in the code section) are kept. However, the format (like bold, italic, titles) are not included.
Convert .odt to .txt file using pandoc
The pandoc tool can convert many file formats. It can also read .odt files and generate .txt files.
Here is the command to convert the .odt file to .txt file is as follows.
The .txt file generated is as follows.
$ cat input-pandoc.txt This is an example docx file. This is a title THIS IS A HEADING LEVEL 1 This is some text with format: BOLD, _italic_ and _underline_. Also some code below. int main()
Here, we can see pandoc keeps some of the format (using BOLD for bold fonts, and _italic_ for italic format). However, it removes some spaces in the code section.
Convert .odt to Markdown .txt file using pandoc
Markdown format is a plain text format with its special markup elements into the text document to indicate formats. The markup elements are also in plain text and readable. It can be a good alternative plain text format.
Here is the command to convert the .odt file to Markdown format.
$ pandoc -t markdown input.odt > input-pandoc.mdThe converted Markdown file is as follows.
$ cat input-pandoc.md This is an example docx file. This is a title This is a heading level 1 ========================= This is some text with format: **bold**, *italic* and *underline*. Also some code below. int main()
Here, we can see the format are marked using Markdown markups ( **bold** , ==== and *italic* ). It is much better although it is not ideal regarding the code section handling.
Summary
This post introduce 3 ways of how to convert .odt to .txt files in command line in Linux. The ways have their pros and cons. But these methods can help us do the majority part of the conversion job. For example, for the example document in this post, by manually adjusting the Markdown plain text file based on pandoc ‘s output and LibreOffice ‘s output (for the code section), we can have a good plain text for the document.
This is an example docx file. This is a title This is a heading level 1 ========================= This is some text with format: **bold**, *italic* and *underline*. Also some code below. ``` int main() < std::cout ```The Markdown, if converted to HTML, will look like this:
