- Faster way to delete large number of files [duplicate]
- 8 Answers 8
- 5 Ways to Empty or Delete a Large File Content in Linux
- 1. Empty File Content by Redirecting to Null
- 2. Empty File Using ‘true’ Command Redirection
- 3. Empty File Using cat/cp/dd utilities with /dev/null
- 4. Empty File Using echo Command
- 5. Empty File Using truncate Command
- How to Delete HUGE (100-200GB) Files in Linux
- Deleting HUGE (200GB) Files in Linux Using ionice Command
Faster way to delete large number of files [duplicate]
I have a directory where lots of cached files are getting generated very quickly. Since these are very small files, it is consuming all my inodes very quickly. Currently I am running the following command to find all the files older than 12 hours and delete them.
$ find ./cache -mtime +0.5 -exec rm <> \; But the rate at which this command is deleting is slower than the rate at which files are being generated. Can someone tell me some alternative way to remove large number of files quickly.
Maybe the problem is that it’s not deleting enough files. You are aware that your command is deleting files whose mtime is more than 12 hours, right? If the files are generated very quickly, then you probably need to delete more recent files than that.
Actually the command which @Gnouc mentioned worked faster. I dont know the reason how it works faster.
8 Answers 8
find … -exec rm <> \; executes the rm command for each file. Even though starting a new process is pretty fast, it’s still a lot slower than the mere act of deleting a file.
find … -exec rm <> + would call rm in batches, which is a lot faster: you pay the cost of running rm once per batch, and each batch performs many deletion.
Even faster is to not invoke rm at all. The find command on Linux has an action -delete to delete a matching file.
find ./cache -type f -mtime +0.5 -delete However, if you’re producing files at such a rate that find … -exec rm <> \; can’t keep up, there’s probably something wrong with your setup. If cache contains millions of files, you should split it into subdirectories for faster access.
Nearly 7 million very small DHCP lease files consumed all the inodes. find -delete saved the day; removed about 6.5 million files in the same time as rm took to remove about 20 thousand.
There is a subtle and possibly sinister problem with all these answers. Find does a depth first search — including subdirectories. If ./cache contains subdirectories those contents will ALSO be removed, but as written, find will try to delete the directories BEFORE deleting the content. There are solutions here: 1. Add -depth if deletion of subdirectories is desired. and 2. Add -type f to avoid attempting sub-directory deletion. Another way to limit to the CURRENT directory only is to use -prune
@SteventheEasilyAmused -delete automatically turns on -prune . But skipping directories is a good idea: find won’t delete non-empty directories, but it will signal an error.
find ./cache -mtime +0.5 -print0 | xargs -0 rm -f Update explaination for @pradeepchhetri
If you use find with -exec , every file that find found will call rm one time. So if you found a huge of files, i.e 10000 files, you called rm 10000 times.
xargs will treat ouput of find as command argument to rm , so that, xargs will provide as many arguments as rm can handle at once, i.e rm -f file1 file2 . So it makes less fork call, make program run faster.
@pradeepchhetri With your method, find starts a new rm process for every file that meets the criteria. With Gnouc’s method, xargs starts only one instance for rm for a bunch of files. Starting many less programs makes it faster.
@kurtm: Thank you for the explanation. But i saw remarkable difference between the two commands, is the number of fork() syscalls is the only difference between the two ?
if you use find with \+ instead of \; it will bundle up the execs and will only launch an exec when the command line gets «big»
Although find is the best (simplest, idiomatic) approach,
You could move the directory aside, create a new directory (for your program), and then delete.
mv $idr old$dir && mkdir $dir && rm -rf old$dir but maybe your problem is creating too many files. Why not change your program to append to an existing file, rather than create a new file? And then you could move this (logfile) aside, and then your program could create/append to a new file, for example,
if the creation rate exceeds deletion rate you are best of by making the cache completely empty, and removing old files without any mtime evaluation
mv cache foobar mkdir cache # may require app restart rm -rf foobar But this would cause the process accessing the cache directory to either fail, or continue to write into the foobar directory (depending on how it is written). Meanwhile, this would remove ALL entries that were originally in cache
If you just want to get rid of many files as soon as possible ls -f1 /path/to/folder/with/many/files/ | xargs rm might work okay, but better don’t run it on production systems because your system might become IO issues and applications might get stuck during the delete operation.
This script works nicely for many files and should not affect the ioload of the system.
#!/bin/bash # Path to folder with many files FOLDER="/path/to/folder/with/many/files" # Temporary file to store file names FILE_FILENAMES="/tmp/filenames" if [ -z "$FOLDER" ]; then echo "Prevented you from deleting everything! Correct your FOLDER variable!" exit 1 fi while true; do FILES=$(ls -f1 $FOLDER | wc -l) if [ "$FILES" -gt 10000 ]; then printf "[%s] %s files found. going on with removing\n" "$(date)" "$FILES" # Create new list of files ls -f1 $FOLDER | head -n 5002 | tail -n 5000 > "$FILE_FILENAMES" if [ -s $FILE_FILENAMES ]; then while read FILE; do rm "$FOLDER/$FILE" sleep 0.005 done < "$FILE_FILENAMES" fi else printf "[%s] script has finished, almost all files have been deleted" "$(date)" break fi sleep 5 done 5 Ways to Empty or Delete a Large File Content in Linux
Occasionally, while dealing with files in Linux terminal, you may want to clear the content of a file without necessarily opening it using any Linux command line editors. How can this be achieved? In this article, we will go through several different ways of emptying file content with the help of some useful commands.
Caution: Before we proceed to looking at the various ways, note that because in Linux everything is a file, you must always make sure that the file(s) you are emptying are not important user or system files. Clearing the content of a critical system or configuration file could lead to a fatal application/system error or failure.
With that said, below are means of clearing file content from the command line.
Important: For the purpose of this article, we’ve used file access.log in the following examples.
1. Empty File Content by Redirecting to Null
A easiest way to empty or blank a file content using shell redirect null (non-existent object) to the file as below:
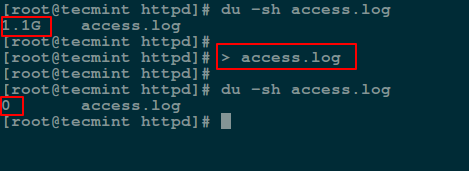
2. Empty File Using ‘true’ Command Redirection
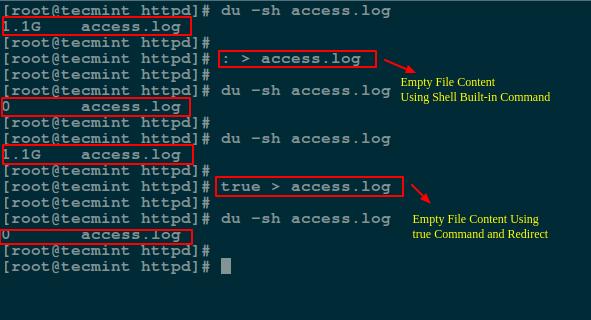
Here we will use a symbol : is a shell built-in command that is essence equivalent to the true command and it can be used as a no-op (no operation).
Another method is to redirect the output of : or true built-in command to the file like so:
# : > access.log OR # true > access.log
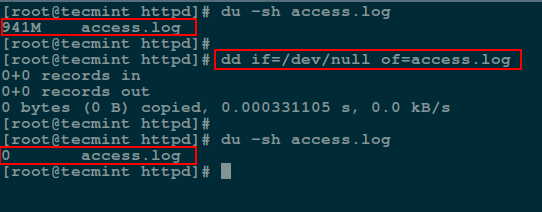
3. Empty File Using cat/cp/dd utilities with /dev/null
In Linux, the null device is basically utilized for discarding of unwanted output streams of a process, or else as a suitable empty file for input streams. This is normally done by redirection mechanism.
And the /dev/null device file is therefore a special file that writes-off (removes) any input sent to it or its output is same as that of an empty file.
Additionally, you can empty contents of a file by redirecting output of /dev/null to it (file) as input using cat command:
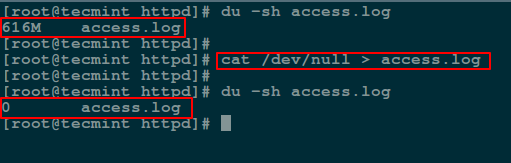
Next, we will use cp command to blank a file content as shown.
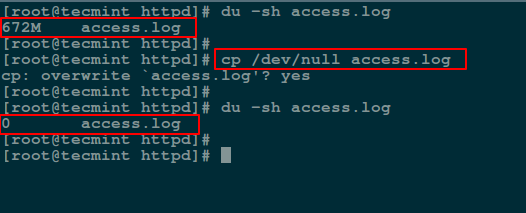
In the following command, if means the input file and of refers to the output file.
4. Empty File Using echo Command
Here, you can use an echo command with an empty string and redirect it to the file as follows:
# echo "" > access.log OR # echo > access.log
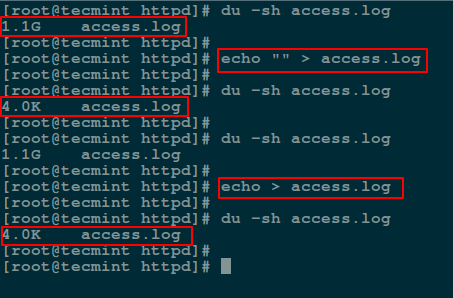
Note: You should keep in mind that an empty string is not the same as null. A string is already an object much as it may be empty while null simply means non-existence of an object.
For this reason, when you redirect the out of the echo command above into the file, and view the file contents using the cat command, is prints an empty line (empty string).
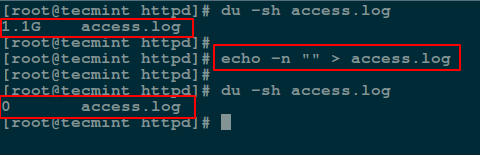
To send a null output to the file, use the flag -n which tells echo to not output the trailing newline that leads to the empty line produced in the previous command.
5. Empty File Using truncate Command
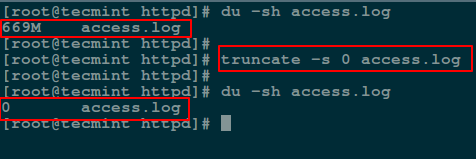
The truncate command helps to shrink or extend the size of a file to a defined size.
You can employ it with the -s option that specifies the file size. To empty a file content, use a size of 0 (zero) as in the next command:
That’s it for now, in this article we have covered multiple methods of clearing or emptying file content using simple command line utilities and shell redirection mechanism.
These are not probably the only available practical ways of doing this, so you can also tell us about any other methods not mentioned in this guide via the feedback section below.
How to Delete HUGE (100-200GB) Files in Linux
Usually, to delete/remove a file from a Linux terminal, we use the rm command (delete files), shred command (securely delete a file), wipe command (securely erase a file), or secure-deletion toolkit (a collection of secure file deletion tools).
We can use any of the above utilities to deal with relatively small files. What if we want to delete/remove a huge file/directory say about 100-200GB?
This may not be as easy as it seems, in terms of the time taken to remove the file (I/O scheduling) as well as the amount of RAM consumed while carrying out the operation.
In this tutorial, we will explain how to efficiently and reliably delete huge files/directories in Linux.
The main aim here is to use a technique that will not slow down the system while removing a huge file, resulting to reasonable I/O. We can achieve this using the ionice command.
Deleting HUGE (200GB) Files in Linux Using ionice Command
ionice is a useful program that sets or gets the I/O scheduling class and priority for another program. If no arguments or just -p is given, ionice will query the current I/O scheduling class and priority for that process.
If we give a command name such as rm command, it will run this command with the given arguments. To specify the process IDs of running processes for which to get or set the scheduling parameters, run this:
To specify the name or number of the scheduling class to use (0 for none, 1 for real-time, 2 for best-effort, 3 for idle) the command below.
This means that rm will belong to the idle I/O class and only uses I/O when any other process does not need it:
---- Deleting Huge Files in Linux ----- # ionice -c 3 rm /var/logs/syslog # ionice -c 3 rm -rf /var/log/apache
If there won’t be much idle time on the system, then we may want to use the best-effort scheduling class and set a low priority like this:
# ionice -c 2 -n 6 rm /var/logs/syslog # ionice -c 2 -n 6 rm -rf /var/log/apache
Note: To delete huge files using a secure method, we may use the shred, wipe and various tools in the secure-deletion toolkit mentioned earlier on, instead of the rm command.
For more info, look through the ionice man page:
That’s it for now! What other methods do you have in mind for the above purpose? Use the comment section below to share with us.