Direct Memory Access in Linux
I’m trying to access physical memory directly for an embedded Linux project, but I’m not sure how I can best designate memory for my use. If I boot my device regularly, and access /dev/mem, I can easily read and write to just about anywhere I want. However, in this, I’m accessing memory that can easily be allocated to any process; which I don’t want to do My code for /dev/mem is (all error checking, etc. removed):
mem_fd = open("/dev/mem", O_RDWR)); mem_p = malloc(SIZE + (PAGE_SIZE - 1)); if ((unsigned long) mem_p % PAGE_SIZE) < mem_p += PAGE_SIZE - ((unsigned long) mem_p % PAGE_SIZE); >mem_p = (unsigned char *) mmap(mem_p, SIZE, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_FIXED, mem_fd, BASE_ADDRESS); And this works. However, I’d like to be using memory that no one else will touch. I’ve tried limiting the amount of memory that the kernel sees by booting with mem=XXXm, and then setting BASE_ADDRESS to something above that (but below the physical memory), but it doesn’t seem to be accessing the same memory consistently. Based on what I’ve seen online, I suspect I may need a kernel module (which is OK) which uses either ioremap() or remap_pfn_range() (or both. ), but I have absolutely no idea how; can anyone help? EDIT: What I want is a way to always access the same physical memory (say, 1.5MB worth), and set that memory aside so that the kernel will not allocate it to any other process. I’m trying to reproduce a system we had in other OSes (with no memory management) whereby I could allocate a space in memory via the linker, and access it using something like
EDIT2: I guess I should provide some more detail. This memory space will be used for a RAM buffer for a high performance logging solution for an embedded application. In the systems we have, there’s nothing that clears or scrambles physical memory during a soft reboot. Thus, if I write a bit to a physical address X, and reboot the system, the same bit will still be set after the reboot. This has been tested on the exact same hardware running VxWorks (this logic also works nicely in Nucleus RTOS and OS20 on different platforms, FWIW). My idea was to try the same thing in Linux by addressing physical memory directly; therefore, it’s essential that I get the same addresses each boot. I should probably clarify that this is for kernel 2.6.12 and newer. EDIT3: Here’s my code, first for the kernel module, then for the userspace application. To use it, I boot with mem=95m, then insmod foo-module.ko, then mknod mknod /dev/foo c 32 0, then run foo-user , where it dies. Running under gdb shows that it dies at the assignment, although within gdb, I cannot dereference the address I get from mmap (although printf can) foo-module.c
#include #include #include #include #include #include #define VERSION_STR "1.0.0" #define FOO_BUFFER_SIZE (1u*1024u*1024u) #define FOO_BUFFER_OFFSET (95u*1024u*1024u) #define FOO_MAJOR 32 #define FOO_NAME "foo" static const char *foo_version = "@(#) foo Support version " VERSION_STR " " __DATE__ " " __TIME__; static void *pt = NULL; static int foo_release(struct inode *inode, struct file *file); static int foo_open(struct inode *inode, struct file *file); static int foo_mmap(struct file *filp, struct vm_area_struct *vma); struct file_operations foo_fops = < .owner = THIS_MODULE, .llseek = NULL, .read = NULL, .write = NULL, .readdir = NULL, .poll = NULL, .ioctl = NULL, .mmap = foo_mmap, .open = foo_open, .flush = NULL, .release = foo_release, .fsync = NULL, .fasync = NULL, .lock = NULL, .readv = NULL, .writev = NULL, >; static int __init foo_init(void) < int i; printk(KERN_NOTICE "Loading foo support module\n"); printk(KERN_INFO "Version %s\n", foo_version); printk(KERN_INFO "Preparing device /dev/foo\n"); i = register_chrdev(FOO_MAJOR, FOO_NAME, &foo_fops); if (i != 0) < return -EIO; printk(KERN_ERR "Device couldn't be registered!"); >printk(KERN_NOTICE "Device ready.\n"); printk(KERN_NOTICE "Make sure to run mknod /dev/foo c %d 0\n", FOO_MAJOR); printk(KERN_INFO "Allocating memory\n"); pt = ioremap(FOO_BUFFER_OFFSET, FOO_BUFFER_SIZE); if (pt == NULL) < printk(KERN_ERR "Unable to remap memory\n"); return 1; >printk(KERN_INFO "ioremap returned %p\n", pt); return 0; > static void __exit foo_exit(void) < printk(KERN_NOTICE "Unloading foo support module\n"); unregister_chrdev(FOO_MAJOR, FOO_NAME); if (pt != NULL) < printk(KERN_INFO "Unmapping memory at %p\n", pt); iounmap(pt); >else < printk(KERN_WARNING "No memory to unmap!\n"); >return; > static int foo_open(struct inode *inode, struct file *file) < printk("foo_open\n"); return 0; >static int foo_release(struct inode *inode, struct file *file) < printk("foo_release\n"); return 0; >static int foo_mmap(struct file *filp, struct vm_area_struct *vma) < int ret; if (pt == NULL) < printk(KERN_ERR "Memory not mapped!\n"); return -EAGAIN; >if ((vma->vm_end - vma->vm_start) != FOO_BUFFER_SIZE) < printk(KERN_ERR "Error: sizes don't match (buffer size = %d, requested size = %lu)\n", FOO_BUFFER_SIZE, vma->vm_end - vma->vm_start); return -EAGAIN; > ret = remap_pfn_range(vma, vma->vm_start, (unsigned long) pt, vma->vm_end - vma->vm_start, PAGE_SHARED); if (ret != 0) < printk(KERN_ERR "Error in calling remap_pfn_range: returned %d\n", ret); return -EAGAIN; >return 0; > module_init(foo_init); module_exit(foo_exit); MODULE_AUTHOR("Mike Miller"); MODULE_LICENSE("NONE"); MODULE_VERSION(VERSION_STR); MODULE_DESCRIPTION("Provides support for foo to access direct memory"); #include #include #include #include #include int main(void) < int fd; char *mptr; fd = open("/dev/foo", O_RDWR | O_SYNC); if (fd == -1) < printf("open error. \n"); return 1; >mptr = mmap(0, 1 * 1024 * 1024, PROT_READ | PROT_WRITE, MAP_FILE | MAP_SHARED, fd, 4096); printf("On start, mptr points to 0x%lX.\n",(unsigned long) mptr); printf("mptr points to 0x%lX. *mptr = 0x%X\n", (unsigned long) mptr, *mptr); mptr[0] = 'a'; mptr[1] = 'b'; printf("mptr points to 0x%lX. *mptr = 0x%X\n", (unsigned long) mptr, *mptr); close(fd); return 0; > 6. Что могут делать программисты — оптимизация кэша
Один из источников промахов кэша в современных операционных системах — это обслуживание внешнего потока данных. Современное аппаратное обеспечение, такое как сетевые карты и дисковые контроллеры, имеет способность записывать получаемые или читать данные прямо в память, не задействуя процессор. Это играет решающую роль для производительности устройств, которые мы сегодня имеем, но это также создает проблемы. Предположим из сети прибывает пакет и операционная система должна решить что с ним делать, посмотрев на его заголовок. Сетевая карта помещает пакет в память и оповещает процессор о его прибытии. У процессора нет шансов на предварительную загрузку этих данных, так как он не знает, когда эти данные прибудут, и может быть даже где конкретно они будут сохранены. Результатом будет промах кэша при чтении заголовка.
Intel добавил в свои чипсеты и процессоры технологию, призванную смягчить эту проблему (см.[3]). Идея состоит в том, чтобы заполнить кэш процессора, который будет извещен о прибытии пакета, данными этого пакета. Полезная загрузка пакета здесь не критична, эти данные, в общем, будут обрабатываться функциями более высокого уровня, или в ядре или на пользовательском уровне. Заголовок ядра используется для того, чтобы принять решение о том, что делать с этим пакетом, поэтому эти данные нужны немедленно.
У сетевой системы ввода/вывода уже есть прямой доступ к память, чтобы записать пакет. Это означает, что она взаимодействует непосредственно с контроллером памяти, который возможно интегрирован в Северный мост. Другая часть контроллера памяти — это интерфейс к процессорам через FSB (в предположении, что контроллер памяти не интегрирован в сам процессор).
Идея прямого доступа к кэшу (DCA — Direct Cache Access) состоит в том, чтобы расширить протокол между сетевой картой и контроллером памяти. На рисунке 6.9 первая картинка показывает начало передачи данных с прямым доступом к памяти на обычной машине с Южным и Северным мостами.
DMA Initiated DMA and DCA Executed Рисунок 6.9: Прямой доступ к кэшу
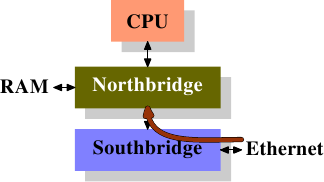
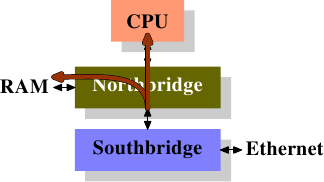
Сетевая карта присоединена к Южному мосту (или является его частью). Она начинает прямой доступ к памяти, но предоставляет новую информацию о заголовке пакета, которая должна быть помещена в кэш процессора.
Традиционное поведение предполагает, что на втором шаге прямой доступ к памяти просто завершается присоединением к памяти. Для передачи данных прямым доступом к памяти с включенным флагом DCA Северный мост дополнительно посылает данные по FSB со специальным новым флагом DCA. Процессор просматривает FSB и, если он обнаруживает флаг DCA, то он пытается загрузить данные, направленные процессору в нижний уровень кэша. Флаг DCA — это просто индикатор, процессор может просто игнорировать его. После того, как передача с прямым доступом к памяти завершена, процессор извещается об этом.
Когда операционная система обрабатывает пакет, ей в первую очередь нужно определить какого он типа. Если индикатор DCA не игнорируется, то загрузки, необходимые операционной системе для того, чтобы идентифицировать пакет, скорее всего приведут к попаданию в кэш. Умножте эту экономию сотен циклов на пакет на десятки тысяч пакетов, которые процессор обрабатывает за секунду, и экономия составит очень значительную величину, особенно когда дело касается задержки.
Без этой интеграции между аппаратурой ввода/вывода (в данном случае сетевой картой), чипсетом и процессорами, такая оптимизация невозможна. Следовательно, при выборе платформы нужно учитывать, понадобится ли эта технология.
[1] Melo, Arnaldo Carvalho de. The 7 dwarves: debugging information beyond gdb. Proceedings of the linux symposium. 2007.
[3] Huggahalli, Ram, Ravi Iyer and Scott Tetrick. Direct Cache Access for High Bandwidth Network I/O . , 2005.