How to download a file from URL in Linux
However, I came accross a site that I suspect uses ASP.Net / IIS. A link to a ISO is in this form (I removed link contents incase of . policies):
http://some.ip.in.here/website.com/IMAGENAME.ISO?md5=hUhpyFjk7zEskw06ZhrWAQ&expires=1454811899 I am not sure how to download this since it has the MD5 and expiry time as parameters, and so wget only downloads a web page, not this ISO. Any suggestions?
Are you putting your asp.net url in quotes («)? There is «&» character which will have side effect of running it in background and your server will not get full url.
Unfortunately, if cookies are involved, it gets a lot harder. If correctly implemented by the web server, it’s even impossible without having a browser open on the same machine.
3 Answers 3
wget "http://some.ip.in.here/website.com/IMAGENAME.ISO?md5=hUhpyFjk7zEskw06ZhrWAQ&expires=1454811899" Explanation: There is «&» character in the url. On linux and alike systems, this makes it a background process. Solution it to enclose url in double quoutes («) so that its treated as one argument.
If you are just trying to get a reasonable filename the complex URL, you can use the output-document option.
-O file --output-document=file Either of these forms will work.
As noted previously, be sure none of the special characters in the URL are getting interpreted by the command parser.
There are two ways you can do this using Curl.
In this first method you would the -O flag to write out the file based on the remote name from the URL; in this case it would most likely write the file out to the system as IMAGENAME.ISO?md5=hUhpyFjk7zEskw06ZhrWAQ&expires=1454811899 ; note how the URL value is contained by double quotes since & and ? might be misinterpreted as Bash commands:
curl -O -L "http://some.ip.in.here/website.com/IMAGENAME.ISO?md5=hUhpyFjk7zEskw06ZhrWAQ&expires=1454811899"; While that method technically “works” but the filename is confusing at best. So in this other method you would use output redirection—with > followed by a filename after the URL—to output the file contents to a file named IMAGENAME.ISO :
curl -L "http://some.ip.in.here/website.com/IMAGENAME.ISO?md5=hUhpyFjk7zEskw06ZhrWAQ&expires=1454811899" > "IMAGENAME.ISO"; So if you ask me, the second method works best for most average use. Also notice the -L flag being used in both commands; that commands tells Curl to follow any redirection links that a file download URL might have since a lot of times files on download services redirect a few times before landing at the destination payload file.
Download file from URL on Linux using command line
There are numerous ways to download a file from a URL via the command line on Linux, and two of the best tools for the job are wget and curl. Both tools have their pros and cons, depending on the download task at hand. In this tutorial, we’ll show you how to use both commands to perform the task.
Downloading files from the command line comes in handy on servers that don’t have a GUI, or for Linux users that simply do most of their tasks on the command line and find it speedier than opening a browser to initiate a download. Other use cases include downloading many files at once or an entire website. We can also use the curl and wget commands in Bash scripting. You will see how to use these commands in a Bash script below.
In this tutorial you will learn:
- Wget vs cURL
- How to download a file with wget
- How to download a file with cURL
- Bash script download examples

| Category | Requirements, Conventions or Software Version Used |
|---|---|
| System | Linux (any distribution) |
| Software | Wget, cURL |
| Other | Privileged access to your Linux system as root or via the sudo command. |
| Conventions | # – requires given linux commands to be executed with root privileges either directly as a root user or by use of sudo command $ – requires given linux commands to be executed as a regular non-privileged user |
Wget vs cURL
Sometimes people get confused over the differences between wget and curl, but actually, it’s pretty simple. The confusion stems from both tools being capable of downloading files from the command line. But apart from this overlap in functionality, the commands are totally different. They are both used for different (albeit similar) things.
But we’re here to learn about downloading a file from the command line. So, which tool is better for the job? Each tool is usually installed by default on any Linux distribution, so it mostly boils down to user preference.
Wget may have a hair of an advantage because it’s a little more straight forward and simple to use. Wget can also download recursively. But curl supports far more protocols outside of FTP and HTTP, and also supports uploading data. As you can tell, they each have their advantages. Regardless of which one you decide to use, you’ll be able to follow along on your own system with our example commands below.
How to download a file with wget
Wget makes file downloads painless and easy. The base syntax for downloading a file is very simple:
$ wget http://example.com/file.tar
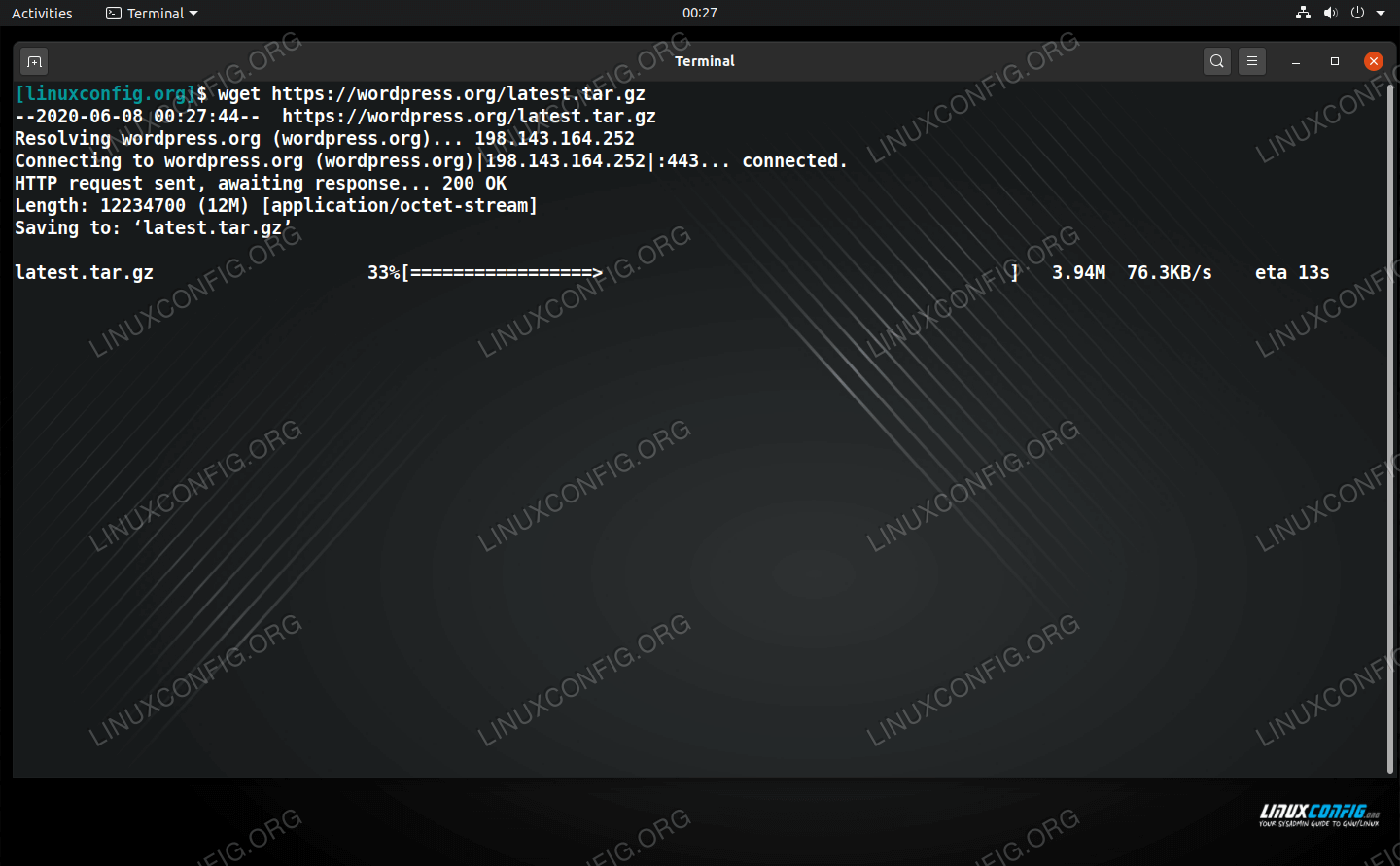
Despite lacking a GUI, wget gives us plenty information about our download, including the progress of the download, transfer speed, and estimated time of completion. The bit of output near the top of the terminal is just wget’s attempt to connect to the server to download the file. That output can be useful for troubleshooting when you’re having problems downloading a file.
HOW TO RESUME INTERRUPTED FILE DOWNLOAD?
If from any reason your file download gets interrupted while using wget command line tool, you can resume the file download by using the -c command line option.
Without supplying any extra parameters in the command, wget will save the downloaded file to whatever directory your terminal is currently set to. If you want to specify where the file should be saved, you can use the -O (output) option in the command.
$ wget http://example.com/file.tar -O /path/to/dir/file.tar
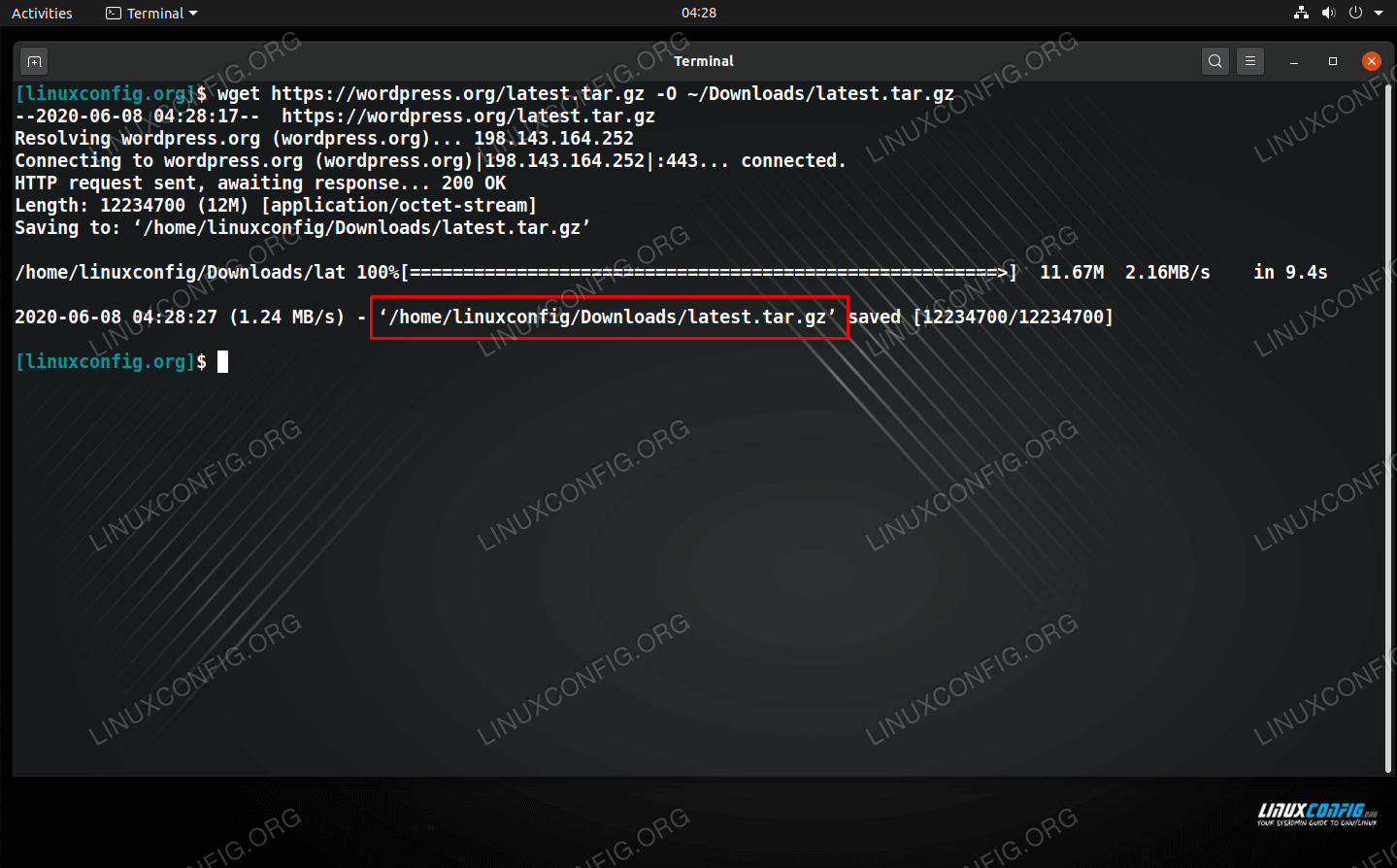
To see more examples of wget and learn what else it’s capable of, check out our full guide on wget.
How to download a file with curl
Curl is another great utility for downloading files from a URL. By default, curl will download a file to standard output. This might be alright if you’re downloading a plain text file or if you are piping the curl command to another tool. But if you’re just downloading a file to your PC, you don’t want curl to send a bunch of garbled text to your terminal, so you should use the -o (output) option in the command.
$ curl http://example.com/file.tar -o /path/to/dir/file.tar
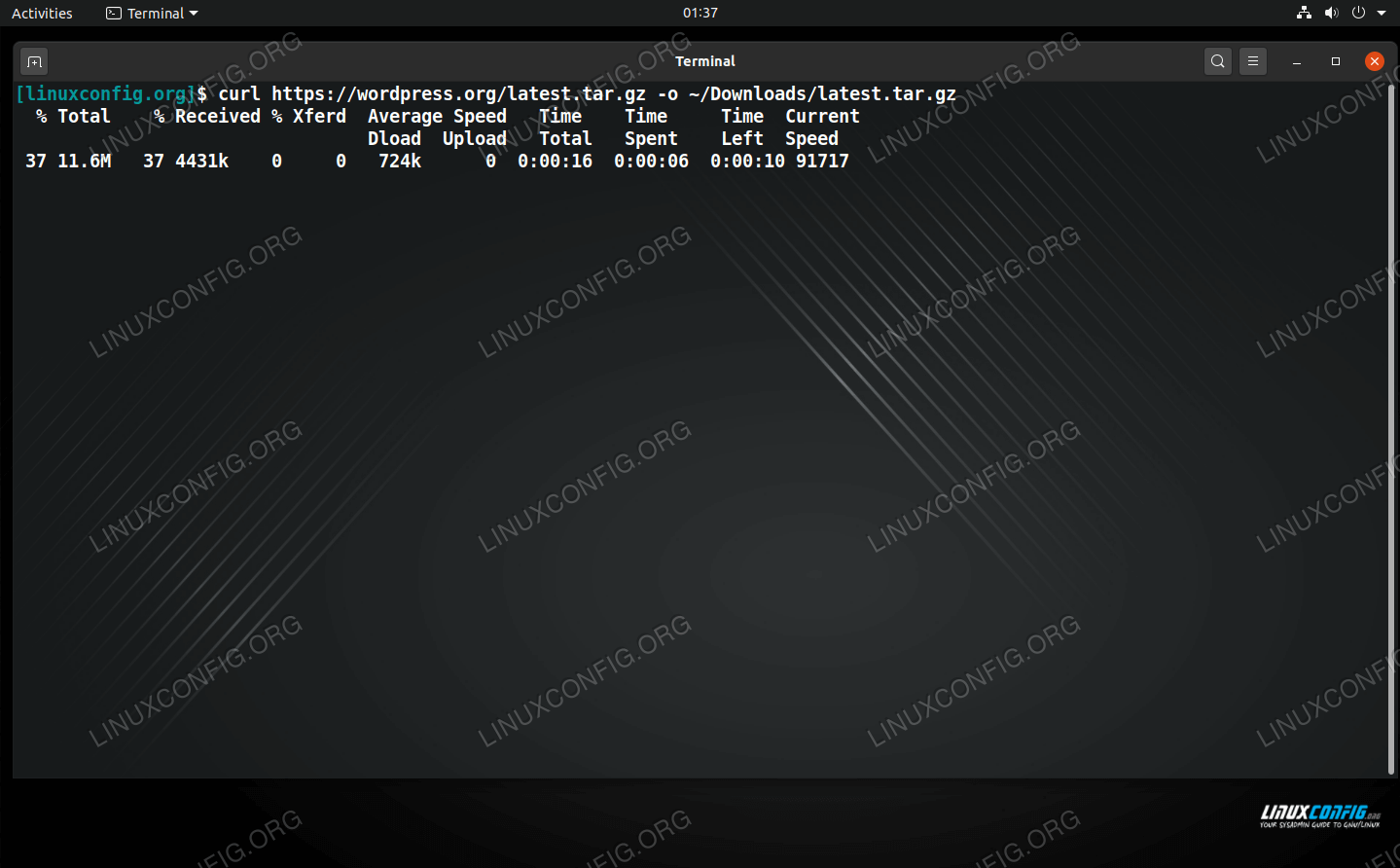
The output here is similar to wget’s where we’re shown the current download rate, estimated time of completion, etc. To see more examples of curl and learn what else its capable of, check out our full guide on curl.
Bash script download examples
Wget and curl are very easy to include in a bash script. In these examples, we’ll look at how to use either command to download a list of URLs in a text document.
First, let’s make a download bash script for wget. You’ll need two files – one called download.sh which contains our bash script, and one called urls.txt which contains our list of URLs to files that we want to download. Each URL needs to be on its own line.
#!/bin/bash while read url; do wget $url done < urls.txtAnd inside of urls.txt , put your list of files:
http://example.com/file1.tar http://example.com/file2.tar http://example.com/file3.tarThis script will loop through our URLs file and execute the wget command for each line. We’ve kept this script very basic, but you can add as many parameters to the wget command as you’d like.
After you’ve compiled a list of URLs into urls.txt and pasted the above code into download.sh with nano or your favorite text editor, give the file execute permissions and run the script:
$ chmod +x download.sh $ ./download.sh
For curl, you can follow the exact same instructions as above, but replace the wget command with curl, like so:
#!/bin/bash while read url; do curl $url -O done < urls.txtNotice that we’ve also appended the -O (note: the O is capitalized) option to our curl command, so curl will download the URLs as files and with their respective names. Without this option, curl would download the files to standard output.
Closing Thoughts
In this guide, we learned about two command line tools that can be used for downloading a URL on Linux: wget and curl. Both are perfect for the job and can perform the task equally well. We also saw how to download files from a Bash script. Be sure to check out their respective full length guides on our site to learn about what else these powerful tools can do.
Related Linux Tutorials:
Comments and Discussions
How to create a hyperlink file?
I know this question sounds too generic but I am unable to find an answer for it. How can I create a link (soft/hard) file which when opened, redirect me to a website with http protocol? One possible way I can think of is creating a lame shell script and making it executable which can make use of a browser to open a website. But isn't there a concept of a "hyperlink file"?
6 Answers 6
Now if you run firefox target.html it will open example.com.
To clarify, there is no such thing as a "hyperlink file". You may have heard of symbolic and hard links, but those are simply a way to refer to a file on disk - they are not URLs. From man ln :
Symbolic links can hold arbitrary text; if later resolved, a relative link is interpreted in relation to its parent directory.
$ cat ~/Desktop/Link.desktop [Desktop Entry] Encoding=UTF-8 Name=Link to your site URL=http://your-site-url.com Icon=text-html This is a possible answer when your solution needn't be command-line-based, but supposed to gain much comfort.
Of course the .desktop files don't have to be stored in ~/Desktop/ . I just used this location since they might be used in that location mostly.
This is missing Type=Link ; the key is unconditionally required, and the value is required in order to use it as a web link file.
xdbg-open is default application for open anything, so you can create bash script like this:
#!/bin/bash if which xdg-open > /dev/null then xdg-open YOUR_URL elif which gnome-open > /dev/null then gnome-open YOUR_URL fi Replace YOUR_URL accordingly, save file and make it executable ( chmod +x filename.sh )
One answer that has not come up yet, is using Linux’s binfmt_misc capabilities, to create a native executable link format that works on the kernel level!
To automatically open any .link files in xdg-open , put this inside an executable file at /etc/local.d/binfmt_misc.start , or any file your OS runs on startup:
#! /bin/sh echo ':open-hyperlink:E::link::/usr/local/bin/open-hyperlink:' > /proc/sys/fs/binfmt_misc/register and put the following into the /usr/local/bin/open-hyperlink executable:
After that, you can just “run” .link files that are marked as executable via any means, and it will open the link in the browser. Command line, GUI double click, whatever you like.
$ echo 'http://superuser.com/questions/986527/how-to-create-a-hyperlink-file' > this-page.link $ chmod +x this-page.link $ ./this-page.link [Browser opens…] You can of course change the extension and file format how you like, provided you change the open-hyperlink script accordingly. Even Windows .lnk files!
Of course your kernel has to have that module available and enabled, for it to work. (I have it compiled in.)
Check out the documentation on binfmt_misc , as there are a lot more possibilities, e.g. with matching on a pattern instead of a file extension.