- How To Use grep Command In Linux/UNIX
- What is the grep Command?
- Using the grep Command
- To Search a File
- To Search Multiple Files
- Search All Files in Directory
- To Find Whole Words Only
- To Ignore Case in Grep Searches
- To Search Subdirectories
- Inverse grep Search
- To Show Lines That Exactly Match a Search String
- To List Names of Matching Files
- To Count the Number of Matches
- To Display the Number of Lines Before or After a Search String
- To Display Line Numbers with grep Matches
- Limit grep Output to a Fixed Number of Lines
- Find all words containing characters in UNIX
- 6 Answers 6
How To Use grep Command In Linux/UNIX
This guide details the most useful grep commands for Linux / Unix systems.
After going through all the commands and examples, you will learn how to use grep to search files for a text from the terminal.

- Linux or UNIX-like system
- Access to a terminal/command line
- A user with permissions to access the desired files and directories
Note: A line does not represent a line of text as viewed on the terminal screen. A line in a text file is a sequence of characters until a line break is introduced. The output of grep commands may contain whole paragraphs unless the search options are refined.
What is the grep Command?
Grep is an acronym that stands for Global Regular Expression Print.
Grep is a Linux / Unix command-line tool used to search for a string of characters in a specified file. The text search pattern is called a regular expression. When it finds a match, it prints the line with the result. The grep command is handy when searching through large log files.
Using the grep Command
The grep command consists of three parts in its most basic form. The first part starts with grep , followed by the pattern that you are searching for. After the string comes the file name that the grep searches through.
The simplest grep command syntax looks like this:

The command can contain many options, pattern variations, and file names. Combine as many options as necessary to get the results you need. Below are the most common grep commands with examples.
Note: Grep is case-sensitive. Make sure to use the correct case when running grep commands.
To Search a File
To print any line from a file that contains a specific pattern of characters, in our case phoenix in the file sample2 , run the command:
Grep will display every line where there is a match for the word phoenix . When executing this command, you do not get exact matches. Instead, the terminal prints the lines with words containing the string of characters you entered. Here is an example:

Tip: If your search pattern includes characters other than alphanumeric, use quotation marks. This includes blank spaces or any symbol.
To Search Multiple Files
To search multiple files with the grep command, insert the filenames you want to search, separated with a space character.
In our case, the grep command to match the word phoenix in three files sample , sample2 , and sample3 looks like this example:
grep phoenix sample sample2 sample3The terminal prints the name of every file that contains the matching lines, and the actual lines that include the required string of characters.
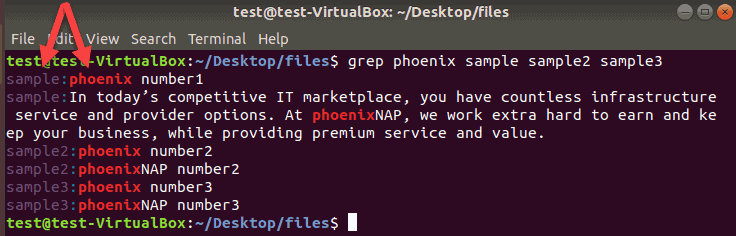
You can append as many filenames as needed. The terminal prints a new line with the filename for every match it finds in the listed files.
Tip: Refer to our article Xargs Commands to learn how to use xargs with grep to search for a string in the list of files.
Search All Files in Directory
To search all files in the current directory, use an asterisk instead of a filename at the end of a grep command.
In this example, we use nix as a search criterion:
The output shows the name of the file with nix and returns the entire line.
To Find Whole Words Only
Grep allows you to find and print the results for whole words only. To search for the word phoenix in all files in the current directory, append -w to the grep command.
This option only prints the lines with whole-word matches and the names of the files it found them in:

When -w is omitted, grep displays the search pattern even if it is a substring of another word.
If you would like to search for multiple strings and word patterns, check out our article on how to grep for multiple strings, patterns or words.
To Ignore Case in Grep Searches
As grep commands are case sensitive, one of the most useful operators for grep searches is -i. Instead of printing lowercase results only, the terminal displays both uppercase and lowercase results. The output includes lines with mixed case entries.
An example of this command:
If we use the -i operator to search files in the current directory for phoenix , the output looks like this:
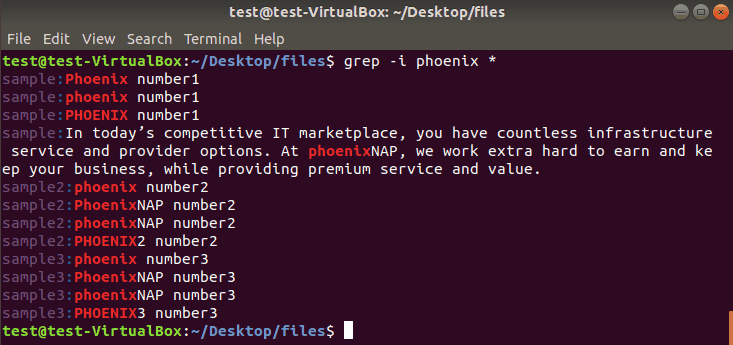
To Search Subdirectories
To include all subdirectories in a search, add the -r operator to the grep command.

This command prints the matches for all files in the current directory, subdirectories, and the exact path with the filename. In the example below, we also added the -w operator to show whole words, but the output form is the same.
Inverse grep Search
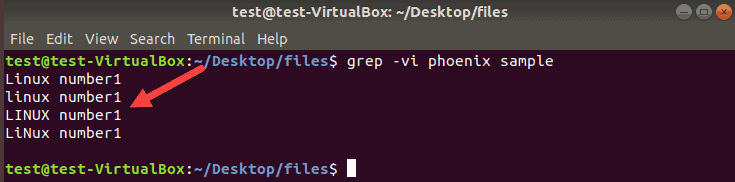
You can use grep to print all lines that do not match a specific pattern of characters. To invert the search, append -v to a grep command.
To exclude all lines that contain phoenix , enter:
The terminal prints all lines that do not contain the word used as a search criterion. Use -i to ignore case to exclude completely the word used for this search:
To Show Lines That Exactly Match a Search String
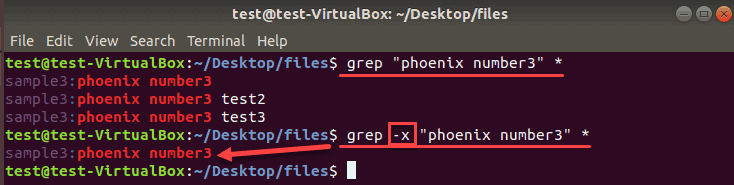
The grep command prints entire lines when it finds a match in a file. To print only those lines that completely match the search string, add the -x option.
The output shows only the lines with the exact match. If there are any other words or characters in the same line, the grep does not include it in the search results. Do not forget to use quotation marks whenever there is a space or a symbol in a search pattern.
Here is a comparison of the results without and with the -x operator in our grep command:
To List Names of Matching Files
Sometimes, you only need to see the names of the files that contain a word or string of characters and exclude the actual lines. To print only the filenames that match your search, use the -l operator:

The output shows the exact filenames that contain phoenix in the current directory but does not print the lines with the corresponding word:
As a reminder, use the recursive search operator -r to include all subdirectories in your search.
To Count the Number of Matches
Grep can display the filenames and the count of lines where it finds a match for your word.
Use the -c operator to count the number of matches:

To Display the Number of Lines Before or After a Search String
Sometimes you need more content in search results to decide what is most relevant.
Use the following operators to add the desired lines before, after a match, or both:
- Use -Aand a number of lines to display after a match: grep -A 3 phoenix sample — this command prints three lines after the match.
- Use -Band a number of lines to display before a match: grep -B 2 phoenix sample — this command prints two lines before the match.
- Use -Cand a number of lines to display before and after the match: grep -C 2 phoenix sample — this command prints two lines before and after the match.
To Display Line Numbers with grep Matches
When grep prints results with many matches, it comes handy to see the line numbers. Append the -n operator to any grep command to show the line numbers.
We will search for Phoenix in the current directory, show two lines before and after the matches along with their line numbers.
grep -n -C 2 Phoenix sample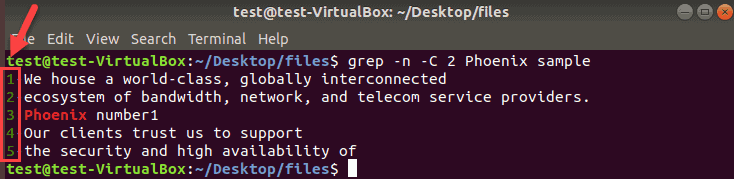
Limit grep Output to a Fixed Number of Lines
Individual files, such as log files, can contain many matches for grep search patterns. Limit the number of lines in the grep output by adding the -m option and a number to the command.
In this case, the terminal prints the first two matches it finds in the sample file.
If you do not specify a file and search all files in a directory, the output prints the first two results from every file along with the filename that contains the matches.
Now you know how to use the grep command in Linux/Unix.
The grep command is highly flexible with many useful operators and options. By combining grep commands, you can get powerful results and find the text hiding in thousands of files. To get started, check out our grep regex guide article.
Find all words containing characters in UNIX
Given a word W, I want to find all words containing the letters in W from /usr/dict/words. For example, «bat» should return «bat» and «tab» (but not «table»). Here is one solution which involves sorting the input word and matching:
word=$1 sortedWord=`echo $word | grep -o . | sort | tr -d '\n'` while read line do sortedLine=`echo $line | grep -o . | sort | tr -d '\n'` if [ "$sortedWord" == "$sortedLine" ] then echo $line fi done < /usr/dict/words Is there a better way? I'd prefer using basic commands (instead of perl/awk etc), but all solutions are welcome! To clarify, I want to find all permutations of the original word. Addition or deletion of characters is not allowed.
your dictionary file is more than 400000 entries if i am not wrong. calling/piping to external command like grep,sort,tr for EVERY line of the dictionary is inefficient.
my dictionary file only has 25143 entries. I am on Solaris 10. But, I agree completely that my approach is inefficient, hence the question.
6 Answers 6
here's an awk implementation. It finds the words with those letters in "W".
dict="/usr/share/dict/words" word=$1 awk -vw="$word" 'BEGIN < m=split(w,c,"") for(p=1;p<=m;p++)< chars[c[p]]++ >> length($0)==length(w)< f=0;g=0 n=split($0,t,"") for(o=1;o<=n;o++)< if (!( t[o] in chars) )< f=1; break >else < st[t[o]]++ >> if (!f || $0==w) < for(z in st)< if ( st[z] != chars[z] ) < g=1 ;break>> if(!g) < print "found: "$0 >> delete st >' $dict Update: change of algorithm, using sorting
dict="/usr/share/dict/words" awk 'BEGIN < w="table" m=split(w,c,"") b=asort(c,chars) >length($0)==length(w) < f=0 n=split($0,t,"") e=asort(t,d) for(i=1;i<=e;i++) < if(d[i]!=chars[i])< f=1;break >> if(!f) print $0 >' $dict $ time ./shell.sh #looking for table ablet batel belat blate bleat tabel table real 0m1.416s user 0m1.343s sys 0m0.014s $ time ./shell.sh #looking for chairs chairs ischar rachis real 0m1.697s user 0m1.660s sys 0m0.014s $ time perl perl.pl #using beamrider's Perl script table tabel ablet batel blate bleat belat real 0m2.680s user 0m1.633s sys 0m0.881s $ time perl perl.pl # looking for chairs chairs ischar rachis real 0m14.044s user 0m8.328s sys 0m5.236s This is not what I want. Only permutations of the original word are allowed. You cannot add/remove characters.
Nope, still not right. You cannot get loo from low, because low has only one 'o'. You cannot add another 'o'. You can only use one 'l', one 'o' and one 'w'. Your result should be low and owl only.
Edited. Next time, show examples in your question and describe as much as possible the output you want.
Here's a shell solution. The best algorithm seems to be #4. It filters out all words that are of incorrect length. Then, it sums the words using a simple substitution cipher (a=1, b=2, A=27, . ). If the sums match, then it will actually do the original sort and compare. On my system, it can churn through ~235k words looking for "bat" in just under 1/2 second. I'm providing all of my solutions so you can see the different approaches.
Update: not shown, but I also tried putting the sum inside the first bin of the histogram approach I tried, but it was even slower than the histograms without. I thought it would function as a short circuit, but it didn't work.
Update2: I tried the awk solution and it runs in about 1/3 the time of my best shell solution or ~0.126s versus ~0.490s. The perl solution runs ~1.1s.
#!/bin/bash word=$1 #dict=words dict=/usr/share/dict/words #dict=/usr/dict/words alg1() < sortedWord=`echo $word | grep -o . | sort | tr -d '\n'` while read line do sortedLine=`echo $line | grep -o . | sort | tr -d '\n'` if [ "$sortedWord" == "$sortedLine" ] then echo $line fi done < $dict >check_sorted_versus_not() < local word=$1 local line=`echo $2 | grep -o . | sort | tr -d '\n'` if [ "$word" == "$line" ] then echo $2 fi ># Filter out all words of incorrect length alg2() < sortedWord=`echo $word | grep -o . | sort | tr -d '\n'` grep_string="^`echo -n $word | tr 'a-zA-Z' '.'`\$" grep "$grep_string" "$dict" | \ while read line do sortedLine=`echo $line | grep -o . | sort | tr -d '\n'` if [ "$sortedWord" == "$sortedLine" ] then echo $line fi done ># Create a lot of variables like this: # _a=1, _b=2, . _z=26, _A=27, _B=28, . _Z=52 gen_chars() < # [ -n "$GEN_CHARS" ] && return GEN_CHARS=1 local alpha="abcdefghijklmnopqrstuvwxyz" local upperalpha=`echo -n $alpha | tr 'a-z' 'A-Z'` local both="$alpha$upperalpha" for ((i=0; i < $; i++)) do ACHAR=$ eval "_$ACHAR=$((i+1))" done > # I think it's faster to return the value in a var then to echo it in a sub process. # Try summing the word one char at a time by building an arithmetic expression # and then evaluate that expression. # Requires: gen_chars sum_word() < SUM=0 local s="" # parsing input one character at a time for ((i=0; i < $; i++)) do ACHAR=$ s="$s\$_$ACHAR+" done SUM=$(( $(eval echo -n $0) )) > # I think it's faster to return the value in a var then to echo it in a sub process. # Try summing the word one char at a time using a case statement. sum_word2() < SUM=0 local s="" # parsing input one character at a time for ((i=0; i < $; i++)) do ACHAR=$ case $ACHAR in a) SUM=$((SUM+ 1));; b) SUM=$((SUM+ 2));; c) SUM=$((SUM+ 3));; d) SUM=$((SUM+ 4));; e) SUM=$((SUM+ 5));; f) SUM=$((SUM+ 6));; g) SUM=$((SUM+ 7));; h) SUM=$((SUM+ 8));; i) SUM=$((SUM+ 9));; j) SUM=$((SUM+ 10));; k) SUM=$((SUM+ 11));; l) SUM=$((SUM+ 12));; m) SUM=$((SUM+ 13));; n) SUM=$((SUM+ 14));; o) SUM=$((SUM+ 15));; p) SUM=$((SUM+ 16));; q) SUM=$((SUM+ 17));; r) SUM=$((SUM+ 18));; s) SUM=$((SUM+ 19));; t) SUM=$((SUM+ 20));; u) SUM=$((SUM+ 21));; v) SUM=$((SUM+ 22));; w) SUM=$((SUM+ 23));; x) SUM=$((SUM+ 24));; y) SUM=$((SUM+ 25));; z) SUM=$((SUM+ 26));; A) SUM=$((SUM+ 27));; B) SUM=$((SUM+ 28));; C) SUM=$((SUM+ 29));; D) SUM=$((SUM+ 30));; E) SUM=$((SUM+ 31));; F) SUM=$((SUM+ 32));; G) SUM=$((SUM+ 33));; H) SUM=$((SUM+ 34));; I) SUM=$((SUM+ 35));; J) SUM=$((SUM+ 36));; K) SUM=$((SUM+ 37));; L) SUM=$((SUM+ 38));; M) SUM=$((SUM+ 39));; N) SUM=$((SUM+ 40));; O) SUM=$((SUM+ 41));; P) SUM=$((SUM+ 42));; Q) SUM=$((SUM+ 43));; R) SUM=$((SUM+ 44));; S) SUM=$((SUM+ 45));; T) SUM=$((SUM+ 46));; U) SUM=$((SUM+ 47));; V) SUM=$((SUM+ 48));; W) SUM=$((SUM+ 49));; X) SUM=$((SUM+ 50));; Y) SUM=$((SUM+ 51));; Z) SUM=$((SUM+ 52));; *) SUM=0; return;; esac done > # I think it's faster to return the value in a var then to echo it in a sub process. # Try summing the word by building an arithmetic expression using sed and then evaluating # the expression. # Requires: gen_chars sum_word3() < SUM=$(( $(eval echo -n `echo -n $1 | sed -E -ne 's. $_&+,pg'`) 0)) #echo "SUM($1)=$SUM" ># Filter out all words of incorrect length # Sum the characters in the word: i.e. a=1, b=2, . and "abbc" = 1+2+2+3 = 8 alg3() < gen_chars sortedWord=`echo $word | grep -o . | sort | tr -d '\n'` sum_word $word word_sum=$SUM grep_string="^`echo -n $word | tr 'a-zA-Z' '.'`\$" grep "$grep_string" "$dict" | \ while read line do sum_word $line line_sum=$SUM if [ $word_sum == $line_sum ] then check_sorted_versus_not $sortedWord $line fi done ># Filter out all words of incorrect length # Sum the characters in the word: i.e. a=1, b=2, . and "abbc" = 1+2+2+3 = 8 # Use sum_word2 alg4() < sortedWord=`echo $word | grep -o . | sort | tr -d '\n'` sum_word2 $word word_sum=$SUM grep_string="^`echo -n $word | tr 'a-zA-Z' '.'`\$" grep "$grep_string" "$dict" | \ while read line do sum_word2 $line line_sum=$SUM if [ $word_sum == $line_sum ] then check_sorted_versus_not $sortedWord $line fi done ># Filter out all words of incorrect length # Sum the characters in the word: i.e. a=1, b=2, . and "abbc" = 1+2+2+3 = 8 # Use sum_word3 alg5() < gen_chars sortedWord=`echo $word | grep -o . | sort | tr -d '\n'` sum_word3 $word word_sum=$SUM grep_string="^`echo -n $word | tr 'a-zA-Z' '.'`\$" grep "$grep_string" "$dict" | \ while read line do sum_word3 $line line_sum=$SUM if [ $word_sum == $line_sum ] then check_sorted_versus_not $sortedWord $line fi done ># I think it's faster to return the value in a var then to echo it in a sub process. # Try summing the word one char at a time using a case statement. # Place results in a histogram sum_word4() < SUM=(0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0) # parsing input one character at a time for ((i=0; i < $; i++)) do ACHAR=$ case $ACHAR in a) SUM[1]=$((SUM[ 1] + 1));; b) SUM[2]=$((SUM[ 2] + 1));; c) SUM[3]=$((SUM[ 3] + 1));; d) SUM[4]=$((SUM[ 4] + 1));; e) SUM[5]=$((SUM[ 5] + 1));; f) SUM[6]=$((SUM[ 6] + 1));; g) SUM[7]=$((SUM[ 7] + 1));; h) SUM[8]=$((SUM[ 8] + 1));; i) SUM[9]=$((SUM[ 9] + 1));; j) SUM[10]=$((SUM[10] + 1));; k) SUM[11]=$((SUM[11] + 1));; l) SUM[12]=$((SUM[12] + 1));; m) SUM[13]=$((SUM[13] + 1));; n) SUM[14]=$((SUM[14] + 1));; o) SUM[15]=$((SUM[15] + 1));; p) SUM[16]=$((SUM[16] + 1));; q) SUM[17]=$((SUM[17] + 1));; r) SUM[18]=$((SUM[18] + 1));; s) SUM[19]=$((SUM[19] + 1));; t) SUM[20]=$((SUM[20] + 1));; u) SUM[21]=$((SUM[21] + 1));; v) SUM[22]=$((SUM[22] + 1));; w) SUM[23]=$((SUM[23] + 1));; x) SUM[24]=$((SUM[24] + 1));; y) SUM[25]=$((SUM[25] + 1));; z) SUM[26]=$((SUM[26] + 1));; A) SUM[27]=$((SUM[27] + 1));; B) SUM[28]=$((SUM[28] + 1));; C) SUM[29]=$((SUM[29] + 1));; D) SUM[30]=$((SUM[30] + 1));; E) SUM[31]=$((SUM[31] + 1));; F) SUM[32]=$((SUM[32] + 1));; G) SUM[33]=$((SUM[33] + 1));; H) SUM[34]=$((SUM[34] + 1));; I) SUM[35]=$((SUM[35] + 1));; J) SUM[36]=$((SUM[36] + 1));; K) SUM[37]=$((SUM[37] + 1));; L) SUM[38]=$((SUM[38] + 1));; M) SUM[39]=$((SUM[39] + 1));; N) SUM[40]=$((SUM[40] + 1));; O) SUM[41]=$((SUM[41] + 1));; P) SUM[42]=$((SUM[42] + 1));; Q) SUM[43]=$((SUM[43] + 1));; R) SUM[44]=$((SUM[44] + 1));; S) SUM[45]=$((SUM[45] + 1));; T) SUM[46]=$((SUM[46] + 1));; U) SUM[47]=$((SUM[47] + 1));; V) SUM[48]=$((SUM[48] + 1));; W) SUM[49]=$((SUM[49] + 1));; X) SUM[50]=$((SUM[50] + 1));; Y) SUM[51]=$((SUM[51] + 1));; Z) SUM[52]=$((SUM[52] + 1));; *) SUM[53]=-1; return;; esac done #echo $ > # Check if two histograms are equal hist_are_equal() < # Array sizes differ? [ $!= $ ] && return 1 # parsing input one index at a time for ((i=0; i < $; i++)) do [ $ != $ ] && return 1 done return 0 > # Check if two histograms are equal hist_are_equal2() < # Array sizes differ? local size=$[ $size != $ ] && return 1 # parsing input one index at a time for ((i=0; i < $size; i++)) do [ $!= $ ] && return 1 done return 0 > # Filter out all words of incorrect length # Use sum_word4 which generates a histogram of character frequency alg6() < sum_word4 $word _h1=$grep_string="^`echo -n $word | tr 'a-zA-Z' '.'`\$" grep "$grep_string" "$dict" | \ while read line do sum_word4 $line if hist_are_equal then echo $line fi done > # Filter out all words of incorrect length # Use sum_word4 which generates a histogram of character frequency alg7() < sum_word4 $word _h1=$grep_string="^`echo -n $word | tr 'a-zA-Z' '.'`\$" grep "$grep_string" "$dict" | \ while read line do sum_word4 $line if hist_are_equal2 then echo $line fi done > run_test() < echo alg$1 eval time alg$1 >#run_test 1 #run_test 2 #run_test 3 run_test 4 #run_test 5 run_test 6 #run_test 7