- What is the best way to count «find» results?
- Find count of files matching a pattern in a directory in linux
- 7 Answers 7
- Find the number of files in a directory
- 8 Answers 8
- How To Count Files And Directories in Linux
- Count Files in Current Directory using WC
- How to Count Hidden Files
- Counting Files in Real Time
- Count Linux Files and Directories using Find
- How to Count Directories using Find
- How to Count Linux Files using Python
- Conclusion
What is the best way to count «find» results?
as a simple portable solution? Your original solution is spawning a new process printf for every individual file found, and that’s very expensive (as you’ve just found).
Note that this will overcount if you have filenames with newlines embedded, but if you have that then I suspect your problems run a little deeper.
I don;t think that warrants a downvote given that the filename/newline limitation is pretty rare and noted above. Slower ? Perhaps. Given you’re querying a filesystem I suspect the speed difference is small. Across my 10,000 files I measure 3ms difference
The performance difference between ‘find
Try this instead (require find ‘s -printf support):
find -type f -printf '.' | wc -c It will be more reliable and faster than counting the lines.
Note that I use the find ‘s printf , not an external command.
$ time find -type f -printf '.' | wc -c 8 real 0m0.004s user 0m0.000s sys 0m0.007s $ time find -type f | wc -l 8 real 0m0.006s user 0m0.003s sys 0m0.000s So my solution is faster =) (the important part is the real line)
With such a small benchmark, the timings are probably dominated by other factors than the thing you want to measure. An experiment with a big tree would be more useful. But this gets my vote for actually doing what the OP asked for.
POSIX compliant and newline-proof:
find /path -exec printf %c <> + | wc -c And, from my tests in / , not even two times slower than the other solutions, which are either not newline-proof or not portable.
Note the + instead of \; . That is crucial for performance, as \; spawns one printf command per file name, whereas + gives as much file names as it can to a single printf command. (And in the possible case where there are too many arguments, Find intelligently spawns new Printfs on demand to cope with it, so it would be as if
Find count of files matching a pattern in a directory in linux
I am new to linux. I have a directory in linux with approx 250,000 files I need to find count of number of files matching a pattern. I tried using following command :
ls -1 20061101-20131101_kh5x7tte9n_2010_* | wc -l -bash: /bin/ls: Argument list too long 0 7 Answers 7
It might be better to use find for this:
find . -name "pattern_*" -printf '.' | wc -m find . -maxdepth 1 -name "20061101-20131101_kh5x7tte9n_2010_*" -printf '.' | wc -m find will return a list of files matching the criteria. -maxdepth 1 will make the search to be done just in the path, no subdirectories (thanks Petesh!). -printf ‘.’ will print a dot for every match, so that names with new lines won’t make wc -m break.
Then wc -m will indicate the number of characters which will match the number of files.
Performance comparation of two possible options:
Let’s create 10 000 files with this pattern:
$ for i in ; do touch 20061101-20131101_kh5x7tte9n_201_$i; done And then compare the time it takes to get the result with ls -1 . or find . :
$ time find . -maxdepth 1 -name "20061101-20131101_kh5x7tte9n_201_*" | wc -m 10000 real 0m0.034s user 0m0.017s sys 0m0.021s $ time ls -1 | grep 20061101-20131101_kh5x7tte9n_201 | wc -m 10000 real 0m0.254s user 0m0.245s sys 0m0.020s find is x5 times faster! But if we use ls -1f (thanks Petesh again!), then ls is even faster than find :
$ time ls -1f | grep 20061101-20131101_kh5x7tte9n_201 | wc -m 10000 real 0m0.023s user 0m0.020s sys 0m0.012s Find the number of files in a directory
Is there any method in Linux to calculate the number of files in a directory (that is, immediate children) in O(1) (independently of the number of files) without having to list the directory first? If not O(1), is there a reasonably efficient way? I’m searching for an alternative to ls | wc -l .
ls | wc -l will cause ls to do an opendir(), readdir() and probably a stat() on all the files. This will generally be at least O(n).
Yeah correct, my fault. I was thinking of O(1) and O(n) to be same, although I should know it better.
8 Answers 8
readdir is not as expensive as you may think. The knack is avoid stat’ing each file, and (optionally) sorting the output of ls.
avoids aliases in your shell, doesn’t sort the output, and lists 1 file-per-line (not strictly necessary when piping the output into wc).
The original question can be rephrased as «does the data structure of a directory store a count of the number of entries?», to which the answer is no. There isn’t a more efficient way of counting files than readdir(2)/getdents(2).
One can get the number of subdirectories of a given directory without traversing the whole list by stat’ing (stat(1) or stat(2)) the given directory and observing the number of links to that directory. A given directory with N child directories will have a link count of N+2, one link for the «..» entry of each subdirectory, plus two for the «.» and «..» entries of the given directory.
However one cannot get the number of all files (whether regular files or subdirectories) without traversing the whole list — that is correct.
The «/bin/ls -1U» command will not get all entries however. It will get only those directory entries that do not start with the dot (.) character. For example, it would not count the «.profile» file found in many login $HOME directories.
One can use either the «/bin/ls -f» command or the «/bin/ls -Ua» command to avoid the sort and get all entries.
Perhaps unfortunately for your purposes, either the «/bin/ls -f» command or the «/bin/ls -Ua» command will also count the «.» and «..» entries that are in each directory. You will have to subtract 2 from the count to avoid counting these two entries, such as in the following:
expr `/bin/ls -f | wc -l` - 2 # Those are back ticks, not single quotes. The —format=single-column (-1) option is not necessary on the «/bin/ls -Ua» command when piping the «ls» output, as in to «wc» in this case. The «ls» command will automatically write its output in a single column if the output is not a terminal.
How To Count Files And Directories in Linux
Being able to count files in a directory on Linux, or directories themselves, is a useful admin task to know how to carry out. It may be that you are troubleshooting disk space issues or it could be that you are investigating a problem with log file rotation. There are many reasons why you may want to count files in a directory or to count the number of directories.
This article looks at some of the ways, and tools, you can use to count files in a directory on Linux. Note that many of the techniques here also will work to count files on VMware ESXi.
We will start by looking at the most common way to count files on Linux, the wc command.
Count Files in Current Directory using WC
The wc command is available on all Linux distributions, so is usually the go to command for counting files and directories. As the man page states, wc is used to print newline, word, and byte counts for each file. We can get wc to take it’s input from the ls command, which is used to list the contents of a directory. For example, I have a directory with 26 files, I can use the ls command to list them:
$ ls filea.txt filed.txt fileg.txt filej.txt filem.txt filep.txt files.txt filev.txt filey.txt fileb.txt filee.txt fileh.txt filek.txt filen.txt fileq.txt filet.txt filew.txt filez.txt filec.txt filef.txt filei.txt filel.txt fileo.txt filer.txt fileu.txt filex.txtWe can count the number of files in the directory by passing the output, or pipe it, to the wc command:
As you can see, it has returned 26 as the number of files. This is because wc using the -l option has counted the number of lines in the output of the ls command.
Note: It’s important that certain switches are not used with the ls command to list the number of files. Adding, for example, the -lah or -ls options will increase the number of lines in the output of the command, which will result in a misleading value for the file count.
You can get a count of files in other directories by adding the full path to the ls command. For example:
$ ls /home/cloud_user/files | wc -l 26How to Count Hidden Files
While this works well, it will not show hidden files, as ls by default will not display them in it’s output. Hidden files and directories on Linux are prefixed with a dot. For example:
-rw------- 1 cloud_user cloud_user 3.6K Jan 11 10:35 .ICEauthority -rw------- 1 cloud_user cloud_user 4.3K Jan 11 10:35 .Xauthority -rw------- 1 cloud_user cloud_user 407 Jan 11 12:47 .bash_history -rw-r--r-- 1 cloud_user cloud_user 220 Oct 17 2018 .bash_logout -rw-r--r-- 1 cloud_user cloud_user 3.7K Oct 17 2018 .bashrcIf we want to include hidden items in the count of files in the directory we can use the -A option with the ls command:
That’s how you can count hidden files on Linux.
Counting Files in Real Time
If you have a program or script that is creating files or logs, you may want to monitor the number of files in a directory in real time, so that you can see how quickly files are being added or removed. One way to do this is to use the commands we have looked at so far, along with the watch command. For example:
The watch command will continuously run the la -A | wc -l command (every 2 seconds by default), displaying the output each time it refreshes. As such you can monitor the file count:
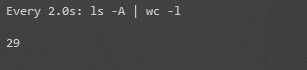
Let’s now move on to looking at how we can count files and directories using a different tool, called find .
Count Linux Files and Directories using Find
Like wc , the find command should already be present on your Linux build. As the name suggests, find is used to find files or folders, but it can also output a count of the files or directories it finds if we use it with wc . Unlike with the ls command, find is able to count files recursively, so that we can get a count from any sub-directories the directory may contain.
To count all files in the current directory and any directories it contains, we can use the -type f option with the find command, which will list all files it finds. As before, we want to pipe the output to the wc command:
To count files in another directory, simply replace the ‘.’ with the full path. For example:
$ sudo find /etc -type f | wc -l 882This shows us that there are 882 files in the /etc directory. Note that I used sudo this time to ensure I had enough permissions to read the contents of /etc without receiving any errors.
How to Count Directories using Find
To count directories, rather than files, use the -type d option with the find command:
# find /etc -type d | wc -l 254As you can see, there are 254 directories in the /etc directory. If you wish to count files and directories you can combine the two types in the find command:
# find /etc -type f,d | wc -l 1136We have 1136 files/directories in total, which is the sum of the earlier commands (882+254). Good news!
OK, so far we have looked at how to count files using Linux command line tools. The combinations of ls and wc and find and wc will have you covered for most of your Linux file counting needs.
However, you might want create a script to count Linux files, either to create a task that is easily repeatable, or to give you more control over the output. I write the occasional article on Python, so let’s have a quick look at how to count files using Python.
How to Count Linux Files using Python
To interact with the Linux file system using Python we can use the os module. A simple script to count the files in a directory using Python could look like this:
import os path, dirs, files = next(os.walk("/home/cloud_user/files")) file_count = len(files) dir_count = len(dirs) print "There are", file_count ,"files in this directory." print "There are", dir_count , "directories."First we are importing os, then using it to count the files and directories in the /home/cloud_user/files directory, and saving the length of the output to a variable for each. Finally, the print command is used to create the output from the script. The result is:
# python filecount.py There are 30 files in this directory. There are 3 directories.Hopefully that should give you an idea of how you can create a python script to count files on Linux!
Conclusion
In this tutorial you have learnt how to count files and directories using the ls , wc and find commands, which are available on all Linux systems.
We have also taken a look at how you can use the watch command to monitor file counts in real time.
Finally, we had a quick look at how you can use Python to create a script that will count files and directories.