How to find all files containing specific text in Linux
This tutorial will teach you how to recursively search for files containing a specific string on Linux using the command line. This tutorial uses the ‘grep’ command to search for strings in files. Alternatively, you may use the find command to look for files with specific content.
A basic syntax for searching text with grep command:
The grep command offers other useful options for finding specific text in file systems.
- -r, —recursive : Search files recursively
- -R, —dereference-recursive : Search files recursively and follow symlinks
- —include=FILE_PATTERN : search only files that match FILE_PATTERN
- —exclude=FILE_PATTERN : skip files and directories matching FILE_PATTERN
- —exclude-from=FILE : skip files matching any file pattern from FILE
- —exclude-dir=PATTERN : directories that match PATTERN will be skipped.
- -L, —files-without-match : Print file names containing no match
- -l, —files-with-matches : Print string containing file names only
- -i, —ignore-case : ignore case of search string
- -e, —regexp=PATTERN : Use a pattern to search or specify multiple search strings
- -w, —word-regexp : force to match whole words
There are several ways to use the grep command to search text. Let’s discuss a few examples of searching a text/string in the file system.
The below example command will search the string “Error” in all files in /var/log directory and its sub-directories.

The -e switch can also be utilized to find multiple strings. This is comparable to the egrep program. The example below will look for “Error” and “Warning” in all the files in the /var/log directory and its subdirectories.
grep -rlw -e "Error" -e "Warning" /var/log 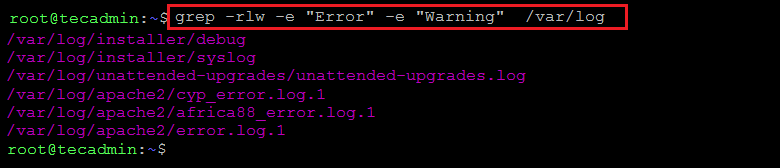
You can search strings in files that match the file name criteria. The following command searches for “Error” in files with the .log extension in the /var/log directory and its sub-directories.
grep -rlw --include="*.log" -e "Error" /var/log You can use the —exclude option in find to exclude some files that match certain file name criteria. For example, you can exclude files with the .txt extension.
grep -rlw --exclude="*.txt" -e "tecadmin" /var/log You can also skip searching certain directories. For instance, don’t search for string files in any folder with apache2 in its name.
grep -rlw --exclude-dir="*apache2*" -e "tecadmin" /var/log Conclusion
You have learned how to search for specific text in files on the Linux file system in this tutorial.
How to find a text file which contains a specific word inside (not in its name)
I want to find a text file in my hard disk which contains a specific word. Prior to Ubuntu 12.4 I used to start in the dash an application, I think it was called «Search for file. «, whose icon was a magnifying glass.I can’t find that simple application any more.
7 Answers 7
You can use the grep command from terminal:
This command will find all occurrences of «word» in all the files under the current directory (or subdrectories).
if grep is called from a shell script, then the search keyword may not print highlighted, but the —color=auto flag can solve that.
sudo apt-get install gnome-search-tool 
Open Search for files select Select More Options and
As suggested here, use mate-search-tool instead which seems to offer identical functionality. Install via sudo apt install mate-utils .
Here’s an overview of different methods that one can use for searching files for specific strings of text, with a few options added specifically to work only with text files, and ignore binary/application files.
One should note,however,that searching for word can get a little complex, because most line-matching tools will try to find a word anywhere on the line. If we’re talking about a word as string that could appear in the beginning or end of line, or alone on the line, or surrounded by spaces and/or punctuation — that’s when we’ll need regular expressions, and especially those that come from Perl. Here, for example, we can use -P in grep to make use of Perl regular expressions to surround it.
$ printf "A-well-a don't you know about the bird?\nWell, everybody knows that the bird is a word" | grep -noP '\bbird\b' 1:bird 2:bird Simple grep
- -r for recursive search down from current directory
- -I to ignore binary files
- -H to output filename where match is found
Suitable for searching only.
find + grep
$ find -type f -exec grep -IH 'word' <> \; - find does the recursive search part
- -I option is to ignore binary files
- -H to output filename where line is found
- good approach for combining with other commands within subshell, like:
$ find -type f -exec sh -c 'grep -IHq "word" "$1" && echo "Found in $1"' sh <> \; Perl
#!/usr/bin/env perl use File::Find; use strict; use warnings; sub find_word< return unless -f; if (open(my $fh, $File::Find::name))< while(my $line = ) < if ($line =~ /\bword\b/)< printf "%s\n", $File::Find::name; close($fh); return; >> > > # this assumes we're going down from current working directory find( < wanted =>\&find_word, no_chdir => 1 >,".") poor-mans recursive grep in recursive bash script
This is the «bash way». Not ideal, probably no good reason to use this when you have grep or perl installed.
#!/usr/bin/env bash shopt -s globstar #set -x grep_line() < # note that this is simple pattern matching # If we wanted to search for whole words, we could use # word|word\ |\ word|\ word\ ) # although when we consider punctuation characters as well - it gets more # complex case "$1" in *word*) printf "%s\n" "$2";; esac >readlines() < # line count variable can be used to output on which line match occured #line_count=1 while IFS= read -r line; do grep_line "$line" "$filename" #line_count=$(($line_count+1)) done < "$1" >is_text_file() < # alternatively, mimetype command could be used # with *\ text\/* as pattern in case statement case "$(file -b --mime-type "$1")" in text\/*) return 0;; *) return 1;; esac >main() < for filename in ./**/* do if [ -f "$filename" ] && is_text_file "$filename" then readlines "$filename" fi done >main "$@" Find files containing a given text
In bash I want to return file name (and the path to the file) for every file of type .php|.html|.js containing the case-insensitive string «document.cookie» | «setcookie» How would I do that?
6 Answers 6
egrep -ir --include=*. "(document.cookie|setcookie)" . The r flag means to search recursively (search subdirectories). The i flag means case insensitive.
If you just want file names add the l (lowercase L ) flag:
egrep -lir --include=*. "(document.cookie|setcookie)" . that didn’t seem to work for me(at least not on mac). just hangs. egrep -lir —include=* «repo» egrep: warning: recursive search of stdin
You forgot to add the path to search. The path is ‘.’ in the above example. In your case, the script is waiting for the input to search on stdin. Try: egrep -lir —include=* «repo» / (or any other path)
Try something like grep -r -n -i —include=»*.html *.php *.js» searchstrinhere .
the -i makes it case insensitlve
the . at the end means you want to start from your current directory, this could be substituted with any directory.
the -r means do this recursively, right down the directory tree
the -n prints the line number for matches.
the —include lets you add file names, extensions. Wildcards accepted
find them and grep for the string:
This will find all files of your 3 types in /starting/path and grep for the regular expression ‘(document\.cookie|setcookie)’ . Split over 2 lines with the backslash just for readability.
find /starting/path -type f -name "*.php" -o -name "*.html" -o -name "*.js" | \ xargs egrep -i '(document\.cookie|setcookie)' Thanks @Michael Berkowski This way fastest more than 5 or 8 times # egrep -ir —include=file.foo «(foo|bar)» /dir on ~500Gb weigth directory.
Sounds like a perfect job for grep or perhaps ack
Or this wonderful construction:
find . -type f \( -name *.php -o -name *.html -o -name *.js \) -exec grep "document.cookie\|setcookie" /dev/null <> \; @MichaelBerkowski : You can use it like this to deal with whitespace in filenames: find . -type f -print0 | xargs -0 -I <> grep «search_string» <> . Of course, the other options can be added as well.
find . -type f -name '*php' -o -name '*js' -o -name '*html' |\ xargs grep -liE 'document\.cookie|setcookie' Just to include one more alternative, you could also use this:
find «/starting/path» -type f -regextype posix-extended -regex «^.*\.(php|html|js)$» -exec grep -EH ‘(document\.cookie|setcookie)’ <> \;
- -regextype posix-extended tells find what kind of regex to expect
- -regex «^.*\.(php|html|js)$» tells find the regex itself filenames must match
- -exec grep -EH ‘(document\.cookie|setcookie)’ <> \; tells find to run the command (with its options and arguments) specified between the -exec option and the \; for each file it finds, where <> represents where the file path goes in this command. while
- E option tells grep to use extended regex (to support the parentheses) and.
- H option tells grep to print file paths before the matches.
And, given this, if you only want file paths, you may use:
find «/starting/path» -type f -regextype posix-extended -regex «^.*\.(php|html|js)$» -exec grep -EH ‘(document\.cookie|setcookie)’ <> \; | sed -r ‘s/(^.*):.*$/\1/’ | sort -u
- | [pipe] send the output of find to the next command after this (which is sed , then sort )
- r option tells sed to use extended regex.
- s/HI/BYE/ tells sed to replace every First occurrence (per line) of «HI» with «BYE» and.
- s/(^.*):.*$/\1/ tells it to replace the regex (^.*):.*$ (meaning a group [stuff enclosed by () ] including everything [ .* = one or more of any-character] from the beginning of the line [ ^ ] till’ the first ‘:’ followed by anything till’ the end of line [ $ ]) by the first group [ \1 ] of the replaced regex.
- u tells sort to remove duplicate entries (take sort -u as optional).
. FAR from being the most elegant way. As I said, my intention is to increase the range of possibilities (and also to give more complete explanations on some tools you could use).