- How to perform grep operation on all files in a directory?
- 5 Answers 5
- Руководство по команде grep в Linux
- Про Linux за 5 минут | Что это или как финский студент перевернул мир?
- Для чего мы пользуемся grep-ом?
- Поиск строк
- Поиск по нескольким параметрам
- Разница между grep, egrep fgrep, pgrep, zgrep
- Разница между find и grep
- Рекурсивный поиск
- Найти пробелы и табуляцию
- Использование регулярных выражений
- Поиск в gz файлах без разархивирования
- Выбрать e-mail из файла
- Выбрать IP адрес
- Оператор ИЛИ
- Игнорировать регистр
- Поиск с учётом регистра
- Найти точное соответствие
- Исключить шаблон
- Найти и заменить
- Вывод номера строки
- Показать строки до и после
- Сортировка результата
How to perform grep operation on all files in a directory?
Working with xenserver, and I want to perform a command on each file that is in a directory, grepping some stuff out of the output of the command and appending it in a file. I’m clear on the command I want to use and how to grep out string(s) as needed. But what I’m not clear on is how do I have it perform this command on each file, going to the next, until no more files are found.
5 Answers 5
In Linux, I normally use this command to recursively grep for a particular text within a directory:
- r = recursive i.e, search subdirectories within the current directory
- n = to print the line numbers to stdout
- i = case insensitive search
grep $PATTERN * would be sufficient. By default, grep would skip all subdirectories. However, if you want to grep through them, grep -r $PATTERN * is the case.
@Tomáš Zato, just supply all your file patterns instead of *: grep $PATTERN *.cpp *.h . If you need more specific rules for what files should be grepped, use find command (check Rob’s answer).
@Chris it’s possible you don’t have *.scss files in current directory but somewhere deeper in subdirs so grep does not look in all the files you wanted. You should use —include option to tell grep to look recursively for files that matches specific patterns: grep -r x —include ‘*.scss’ . (note the quotes, they prevent the pattern from being expanded by the shell). Or just use find (see Rob’s answer).
You want grep -s so you don’t get a warning for each subdirectory that grep skips. You should probably double-quote «$PATTERN» here.
Руководство по команде grep в Linux
![]()
То, что система Linux предоставляет пользователю большое многообразие разного функционала уже не секрет. На одном из прошлых материалов мы рассмотрели, как и где можно использовать команду find. В этой же статье мы на примерах разберём команду grep, мощный инструмент системных администраторов.
Про Linux за 5 минут | Что это или как финский студент перевернул мир?


Для чего мы пользуемся grep-ом?
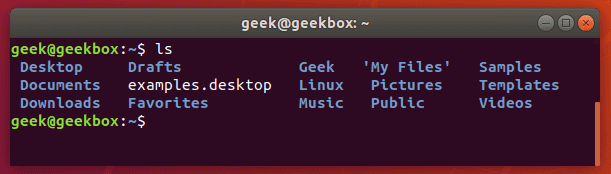
Grep это утилита командной строки Linux, который даёт пользователям возможность вести поиск строки. С его помощью можно даже искать конкретные слова в файле. Также можно передать вывод любой команды в grep, что сильно упрощает работу во время поиска и траблшутинга. Возьмём команду ls. Сама по себе она выводит список всех файлов и папок. Но если нужно найти конкретную папку или один файл среди сотни других, то мы можем передать вывод команды ls в grep через вертикальную черту (|), а уже grep-у параметром передать нужное слово.
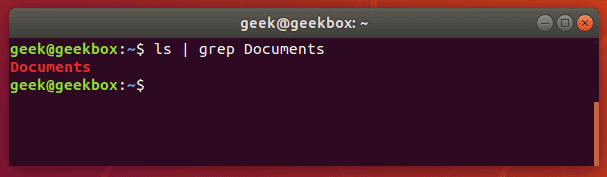 Если команда grep ничего не вернула, значит искомого файла/папки не существует в данной директории.
Если команда grep ничего не вернула, значит искомого файла/папки не существует в данной директории. 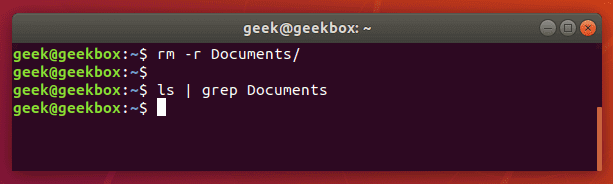
Поиск строк
Если же нужно найти не одно слово, а словосочетание или целое предложение, то параметр команды grep должно быть выделено кавычками. Grep поддерживает как одинарные, так и двойные кавычки.
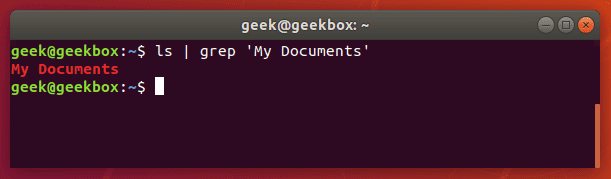
Несмотря на то, что команда grep чаще используется как своего рода фильтр для других команд, но её также можно использовать отдельно как на примере ниже.
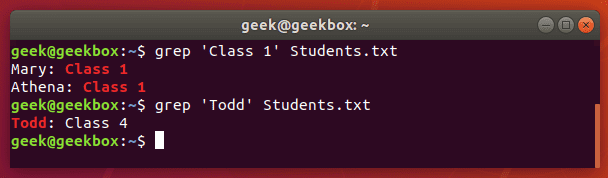
В этом примере мы вели поиск указанных в кавычках слов в файле Students.txt и команда grep успешно справилась со своей задачей.
Поиск по нескольким параметрам
Команде grep можно передавать не один параметр, а несколько. Для этого перед каждым аргументом пишется ключ e. Эту команду система понимает, как «или-или» и выводит все вхождения указанных слов. Заметьте, что кавычками выделена только строка, которая содержит пробел.
$ grep -e 'Class 1' -e Todd Students.txt

Разница между grep, egrep fgrep, pgrep, zgrep
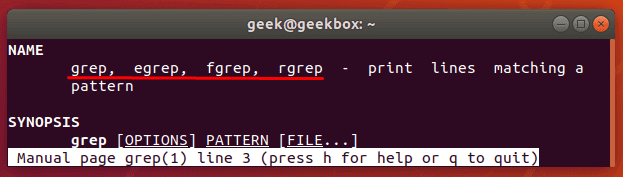
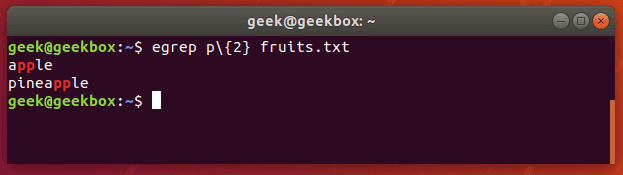
Исторически разные версии Linux-а включали разновидности команды grep. Хотя в современных версия систем базовая команда grep поддерживает все возможности, которыми обладают egrep fgrep, pgrep, zgrep, но все же их тоже стоит рассмотреть. Как видно из вывода man grep (мануал по команде grep), все эти версии всего лишь разные названия основной команды. Например, egrep это тоже самое, что и grep E (помните, командная строка Linux регистрозависимая и команды grep e и grep E интерпретируются по разному). Этой команде в качестве шаблона передается расширенное регулярное выражение. Существует очень много разных ситуаций, где можно воспользоваться этой командой. Например, две команды ниже эквивалентны и выводят все строки, в которых есть две подряд идущих буквы «p».
$ egrep p fruits.txt $ grep -E p fruits.txt
 Fgrep это команда grep F, которая обрабатывает переданный шаблон как список фиксированных данных строкового типа. Эта команда полезна, когда в шаблоне используются зарезервированные для регулярных выражений символы, которые при обычно grep пришлось бы экранировать.
Fgrep это команда grep F, которая обрабатывает переданный шаблон как список фиксированных данных строкового типа. Эта команда полезна, когда в шаблоне используются зарезервированные для регулярных выражений символы, которые при обычно grep пришлось бы экранировать. 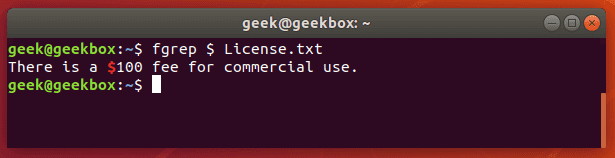 Команда pgrep используется для поиска конкретного процесса, запущенного в системе и возвращает идентификатор указанного процесса (PID). Команда ниже выводит PID процесса sshd. Почти такого же результата можно достичь если запустить команду ps e | grep sshd.
Команда pgrep используется для поиска конкретного процесса, запущенного в системе и возвращает идентификатор указанного процесса (PID). Команда ниже выводит PID процесса sshd. Почти такого же результата можно достичь если запустить команду ps e | grep sshd.
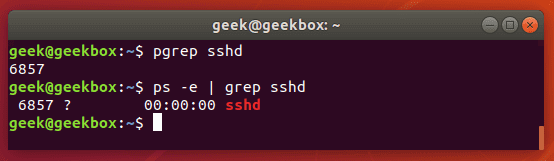
Команда zgrep используется для поиска указанного шаблона в заархивированных файлах, что очень удобно так как не приходится сначала разархивировать файл, а потом уже вести поиск.
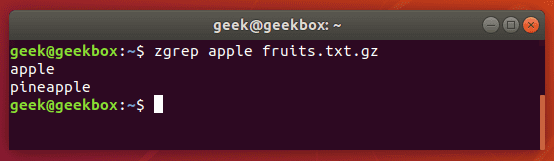 Zgrep также работает с tar архивами, но ограничивается лишь выводом информации о том, нашла ли она соответствие или нет. Это замечание мы сделали потому, что чаще всего gzip-ом архивируются tar файлы.
Zgrep также работает с tar архивами, но ограничивается лишь выводом информации о том, нашла ли она соответствие или нет. Это замечание мы сделали потому, что чаще всего gzip-ом архивируются tar файлы. 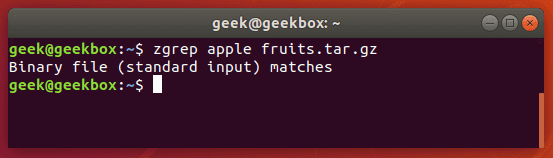
Разница между find и grep
Те, кто только начинает пользоваться командной строкой Linux должны понимать, что find и grep это две разные команды, которые имеют совсем разные функции, даже если оба используются для «поиска» чего-либо. При поиске файлов grep-ом удобно пользоваться для фильтрации вывода команды find, как и было показано в начале материала. Но если нужно найти какой-то файл в системе по его названию или части названия (при этом используется маска *), то лучше всего обратиться к find. Она выведёт точно расположение искомого файла.
$ find /path/to/search -name name-of-file
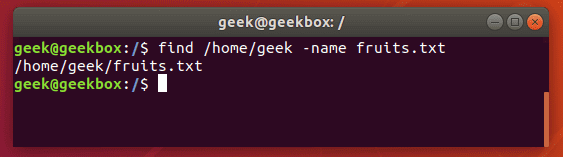
Рекурсивный поиск
Чтобы вести поиск по указанному шаблону среди всех файлов во всех папках и подпапках, команду grep нужно запустить с ключом r. Команда выведет все файлы, где найдено совпадение с указанным шаблоном, а также путь к ним. По умолчанию поиск ведется по текущей директории и поддиректориях.
$ grep -r pattern /directory/to/search

Найти пробелы и табуляцию
Как и было отмечено ранее, если в шаблоне поиска содержится пробел, то мы должны выделять строку кавычками. Это мы можем использовать для поиска пробелов и знаков табуляции в файле. О том как вставить табуляцию чуть позже.
 Есть несколько путей вставки табуляции, но некоторые дистрибутивы могут не поддерживать их. Как известно, в командной строке Linux клавиша TAB сама по себе дополняет введённую команду. Но если комбинировать клавиши ctrl+v, а затем нажать TAB, то система воспримет это как знак табуляции. $ grep » » sample.txt
Есть несколько путей вставки табуляции, но некоторые дистрибутивы могут не поддерживать их. Как известно, в командной строке Linux клавиша TAB сама по себе дополняет введённую команду. Но если комбинировать клавиши ctrl+v, а затем нажать TAB, то система воспримет это как знак табуляции. $ grep » » sample.txt 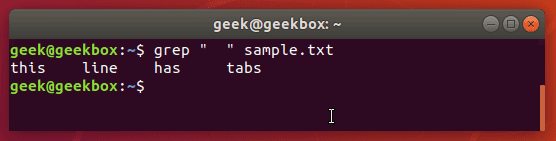 Эта фишка очень помогает при поиске среди конфигурационных файлов системы, так как значения от параметров отделяются табуляцией.
Эта фишка очень помогает при поиске среди конфигурационных файлов системы, так как значения от параметров отделяются табуляцией.
Использование регулярных выражений
Регулярные выражения сильно расширяют возможности команды grep, что позволяет нам вести более гибкий поиск. Далее мы рассмотрим несколько вариантов использования регулярных выражений. [квадратные скобки] они используются чтобы проверить на соответствие одному из указанных символов.
$ grep "Class [123]" Students.txt
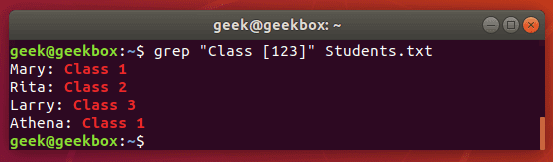
[-] знак дефиса означает диапазон значений. Это могут быть как буквы, так и цифры.
$ grep "Class 2" Students.txt
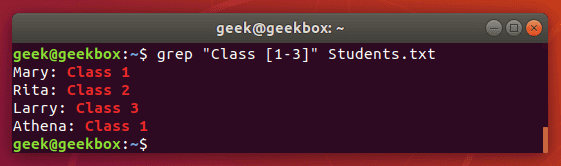
Вторая команда вывела то же, что и первая, но здесь мы обошлись знаком диапазона. ^ каретка используется для поиска строк, которые начинаются с указанного шаблона. Команда ниже выведет все строки, которые начинаются с буквы «А».
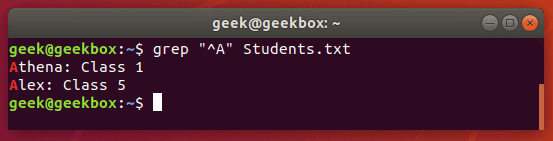
[^] но между квадратными скобками смысл каретки меняется. Здесь он исключает из поиска следующие за ней символы или диапазон символов.
$ grep "Class [^1-2]" Students.txt
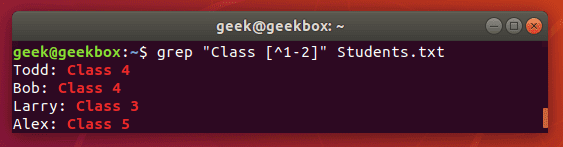
$ знак доллара означает конец строки. Команда выведет только те строки, в конце которых встречает указанный шаблон.
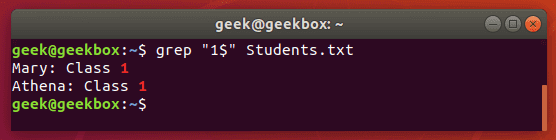
.точка обозначает один любой символ. Чтобы указать несколько любых символов, можно написать символ точку нужное количество раз.
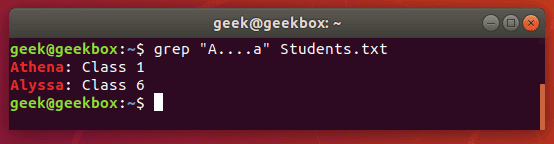 Или же можно использовать квантификаторы.
Или же можно использовать квантификаторы.
| Квантификатор | Число повторений | Пример | Подходящие строки |
| Ровно n раз | Хаха | Хаааха | |
| От m до n включительно | Хаха | Хаа, Хааа, Хааааха | |
| Не менее m | Хаха | Хааха, Хаааха, Хааааха и т. д. | |
| Не более n | Хаха | Хха, Хаха, Хааха, Хаааха |
| Квантификатор | Аналог | Значение |
| ? | Ноль или одно вхождение | |
| * | Ноль или более | |
| + | Одно или более |
Поиск в gz файлах без разархивирования
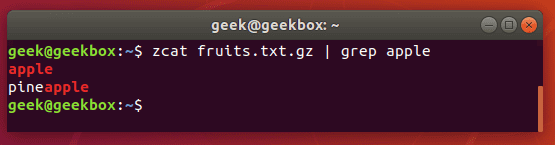
Как и было сказано выше, мы можем искать файлы внутри архива командой zgrep. Есть аналогичная команда, которая отличается тем, что вывод передается grep для фильтрации.
$ zcat file.gz | grep word-to-search
Выбрать e-mail из файла
Иногда приходится искать e-mail адреса из какого-либо файла. Делать это вручную достаточно затратно в плане времени. И тут нам на помощь приходит команда grep с регулярным выражением необычной на первый взгляд формы.
$ grep -o '[[:alnum:]+.\_-]*@[[:alnum:]+.\_-]*' emails.txt
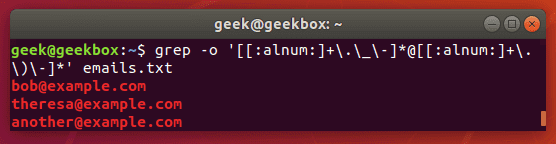
Ключ o указывает на то, что нам нужно выбрать только e-mail адреса, а не все предложение, в котором встречается e-mail. Как мы уже убедились, Linux предоставляет большое число возможностей для выполнения одной задачи. Так же и в этом случае. Мы могли бы воспользоваться командой egrep с разными регулярными выражениями. Но указанная выше команда наиболее проста для вывода только адресов электронной почты, игнорируя при этом всё остальное.
Выбрать IP адрес
Выбор IP адресов немного сложнее, так как мы не можем просто взять строку из цифр, разделённых точкой. Вернее, можем, но это не будет валидным IP адресом. А вот команда ниже выведет нам список правильных IP адресов.
$ grep -E -o "(254|217|[01]?42?).(251|248|[01]?85?).(253|246|[01]?88?).(253|227|[01]?48?)" /var/log/auth.log
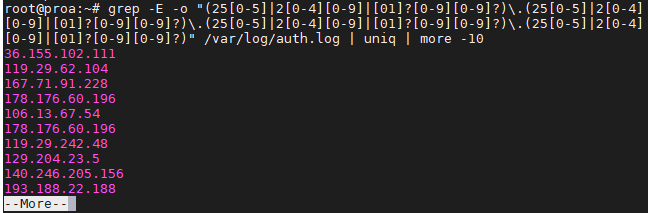
На скриншоте ниже мы вывели список IP, с которых была попытка подключения по SSH.
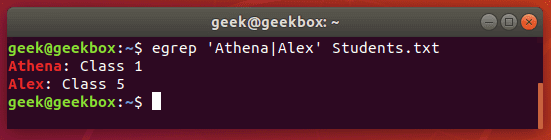
Оператор ИЛИ
Существует очень много разных вариантов использования условного оператора ИЛИ (OR) с командой grep. Но мы покажем самое простое и запоминающееся выражение.
$ grep -E 'string1|string2' filename $ egrep 'string1|string2' filename
Игнорировать регистр
По умолчанию, grep чувствительна к регистру, что немного мешает поиску, так как мы должны точно указать регистр букв при поиске. Эта проблема решается путем добавления ключа i к команде поиска.
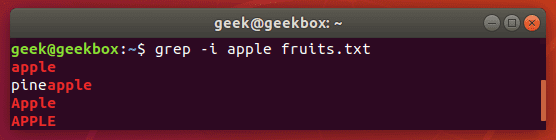
Как видно из скриншота, мы вывели слова независимо от того какими буквами они набраны.
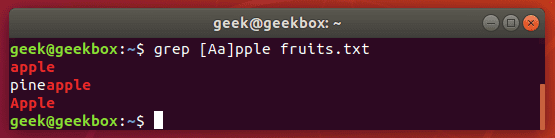
Поиск с учётом регистра
Что если нам нужно найти строку, где первая буква может быть, как заглавной, так и строчной? Grep с ключом i тут не поможет. Самый простой способ реализовать это показана ниже.
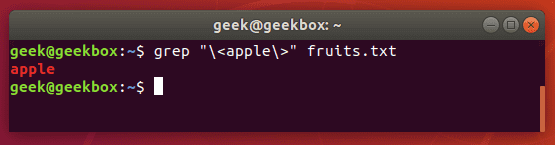
Найти точное соответствие
В запросах выше нам возвращались все строки, в которых содержалось слово apple. Чтобы избежать такого можно прописать команду ниже.
Правда есть еще метод с ключом w. Но это сработает только в том случае, если вы уверены, что после искомого слова нет никакого текста.
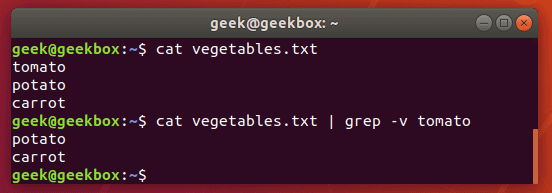
Исключить шаблон
$ grep -v string-to-exclude filename
Найти и заменить
Для поиска и замены одного текста другим командой grep, нужно запустить её, а вывод передать команде sed. Команда ниже заменить все вхождения строки «string1», на «string2» во всех файлах в текущей директории.
$ grep -rl 'string1' ./ | xargs sed -i 's/string1/string2/g'
Вывод номера строки
Чтобы показать номер строки, где была найдена искомая строка, команду grep следует запускать с ключом n.

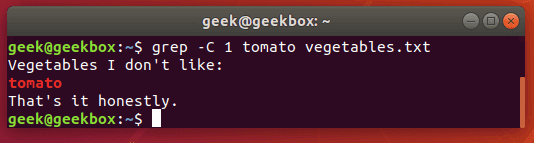
Показать строки до и после
Если нужно узнать в каком контексте употреблялась искомая фраза, можно вывести предложения предшествующее и следующее за указанной строкой. Для этого нужно запустить команду grep с ключом c и передать число строк для отображения.
Сортировка результата
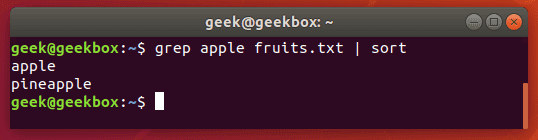
Чтобы отсортировать вывод команды grep по какому-либо порядку, за ней следует прописать команду sort через вертикальную чёрточку (|). По умолчанию sort отсортирует результат по алфавиту. Вот и всё. Надеемся материал окажется полезным для вас.