- How do I change the encoding to UTF-8 in Linux?
- How do I know if a text file is UTF-8?
- How to convert files to UTF-8 encoding in Linux?
- Linux change encoding of a text file
- How can I programmatically change file encoding linux?
- How to change encoding in many files?
- Linux — Java/File encoding
- Can file encoding change when FTP is used?
- How to change character encoding of a text file on Linux
- Step One: Detect Character Encoding of a File
- Step Two: Find Out Supported Text Encodings
- Step Three: Convert Text Encoding
- Support Xmodulo
How do I change the encoding to UTF-8 in Linux?
UTF-8 is an encoding system for Unicode. The first 256 characters in the Unicode library — which include the characters we saw in ASCII — are represented as one byte. Characters that appear later in the Unicode library are encoded as two-byte, three-byte, and eventually four-byte binary units.
How do I convert to UTF-8 in Python?
“convert file encoding to utf-8 python” Code Answer
- with open(ff_name, ‘rb’) as source_file:
- with open(target_file_name, ‘w+b’) as dest_file:
- contents = source_file. read()
- dest_file. write(contents. decode(‘utf-16’). encode(‘utf-8’))
How do I know if a text file is UTF-8?
Open the file in Notepad. Click ‘Save As…’. In the ‘Encoding:’ combo box you will see the current file format. Yes, I opened the file in notepad and selected the UTF-8 format and saved it.
How do I save an SRT file as UTF-8?
With your subtitle file open in the correct character encoding, now go to the menu File → Save as… and change the character encoding option (again, at the bottom of the window) to UTF-8 and save the file (possibly with a new name, for safety).
How to convert ISO 8859-2 to UTF-8?
How to convert files to UTF-8 encoding in Linux?
How to convert a file to ASCII encoding?
How many charsets are there in ISO 8859?

Linux change encoding of a text file
If you need to convert to your current terminal encoding you can do it like that: Or exactly what you wanted: Solution 3: I found this method worked well for me, especially where I had multiple file encodings and multiple file extensions. Ordinarily, the FTP software will not change the character encoding of the transferred file unless the source/target operating systems use a very different character encoding with which to represent text files.
How can I programmatically change file encoding linux?
iconv will take care of that, use it like this:
iconv -f ISO88591 -t UTF8 in.txt out.txt where 88591 is the encoding for latin1 , one of the most common 8-bit encodings, which might (or not) be your input encoding.
If you don’t know the input charset, you can detect it with the standard file command or the python based chardet . For instance:
iconv -f $(file -bi myfile.txt | sed -e 's/.*[ ]charset=//') -t UTF8 in.txt out.txt You may want to do something more robust than this one liner, like don’t process files when encoding is unknown.
From here, to iterate over multiple files, you can do something like
find . -iname *.txt -exec iconv -f ISO88591 -t UTF8 <> <> \; I didn’t check this, so you might want to google iconv and find, read about them here on SO, or simply read their man pages.
iconv is the tool for the job.
iconv -f original_charset -t utf-8 originalfile > newfile How to change encoding of a text file without openning, iconv can be used to convert text files from one encoding to another. Most linux distros should have it—usually as part of glibc; if not, then as a separate installable package.. So, if they’re, say, Latin-1 (ISO-8859-1), you can do something like this: $ iconv -f ISO-8859-1 -t UTF-8 foo.txt >foo-utf8.txt Usage example$ iconv -f ISO-8859-1 -t UTF-8 foo.txt >foo-utf8.txtFeedback
How to change encoding in many files?
find . -type f -print -exec iconv -f iso8859-2 -t utf-8 -o <>.converted <> \; -exec mv <>.converted <> \; It will use temp file with ‘.converted’ suffix (extension) and then will move it to original name, so be careful if you have files with ‘.converted’ suffixes (I don’t think you have).
Also this script is not safe for filenames containing spaces, so for more safety you should double-quote: «<>» instead of <> and «<>.converted» instead of <>.converted
read about enconv.
If you need to convert to your current terminal encoding you can do it like that:
find . -exec enconv -L czech <>\; Or exactly what you wanted:
find . -exec enconv -L czech -x utf8 <>\; I found this method worked well for me, especially where I had multiple file encodings and multiple file extensions.
Create a vim script called script.vim:
set bomb set fileencoding=utf-8 wq Then run the script on the file extensions you wish to target:
find . -type f \( -iname "*.html" -o -iname "*.htm" -o -iname "*.php" -o -iname "*.css" -o -iname "*.less" -o -iname "*.js" \) -exec vim -S script.vim <> \; How can I programmatically change file encoding linux?, iconv will take care of that, use it like this: iconv -f ISO88591 -t UTF8 in.txt out.txt. where 88591 is the encoding for latin1, one of the most common 8-bit encodings, which might (or not) be your input encoding. If you don’t know the input charset, you can detect it with the standard file command or the …
Linux — Java/File encoding
java -Dfile.encoding=UTF-8 *.jar
to run a java project in specific encoding no matter what default encoding the current system use.
if you intend to change all files in a project to a specific encoding in eclipse
right click on your project in project explorer -> Properties(or Alt+Enter) -> Resource -> look on the right, you can see Text File Encoding , Then you can choose UTF-8 as needed.
Remember to check all your packages (right click and check Text File Encoding part) that they all inherited from container.
Using Linux command line to convert file character, How can one change the file encoding from linux (Fedora 20) command line? I have a huge CSV file 7GB and I don’t wish to open it. to find out the current encoding; file -bi /path/to/file.csv. the result should look something like «text/plain; charset=us-ascii» now for the conversion:
Can file encoding change when FTP is used?
You are probably seeing a difference in line-endings. When transferring a file in ASCII/Text mode (as opposed to «Binary mode») then most FTP clients will convert/normalise line-endings to the OS being transferred to.
On Classic Mac OS (9.x and earlier) the line-ending char is simply \r (ASCII 13), on Mac OS X this changed to \n (ASCII 10), on Linux it is \n (ASCII 10). And Windows is \r\n or ASCII 13+10. (Thanks @8bittree for the Mac correction.)
So, when downloading from one OS to another all line-endings are silently converted. The conversion is reversed when uploaded. (However, as noted in @Joshua’s answer this can result in corruption, depending on the file’s character encoding and specific characters contained in the file.) If there is a mishmash of line-endings then it’s possible the FTP software is normalising/fixing the line-endings. This would explain why downloading and then uploading the file results in a «different» file to what was originally on the server (ie. it is «fixed»). Or it is reverting a previously miss-converted file? However, the EOL-conversion may not be so intelligent and you can just end up with either double spaced lines or missing line breaks altogether (ie. mildly corrupted).
By default, most FTP clients are set to «Auto» transfer mode and have a list of known file types to transfer in ASCII/Text mode. Other file types are transferred in «Binary» mode. If you are transferring between the same OS, or you wish to transfer with no conversion, then you should use «Binary» mode only.
Ordinarily, the FTP software will not change the character encoding of the transferred file unless the source/target operating systems use a very different character encoding with which to represent text files. As @KeithDavies noted in comments, one such example is when downloading from a mainframe, that uses EBCDIC, to a local Windows machine. EBCDIC is not supported natively by Windows, so a conversion is required to convert this to ASCII. Again, transferring in «Binary mode» avoids any such conversion. (Thanks to @KeithDavies for the note regarding character encoding.)
The answer to the above was that if diff was used with the -w flag it ignores whitespace.
Yes, line-endings (whitespace) are ignored in the comparison.
If I download one of the files I’m comparing, and re-upload (overwrite) it through an FTP client, the output changes.
If there was a mixture of line-endings in the original file then downloading and re-uploading in ASCII mode could well «fix» the inconsistent line-endings. So, the files are now «the same».
Yes. Don’t transfer UTF-16 files in ASCII mode; use binary mode to avoid data corruption here.
FTP’s transformation of \r\n to \n will corrupt the remainder of the file if it happens to contain the single character ഊ or the sequence ㄍਰ or many others of the same class.
Please note that this is not an intelligent transformation, and the reverse transformation also exists and covers quite a few more cases.
Yes , ftp does some encoding changes. Data is transferred from a storage device in the sending Host to a storage device in the receiving Host. Often it is necessary to perform certain transformations on the data because data storage representations in the two systems are different. For example, NVT-ASCII has different data storage representations in different systems. PDP-10’s generally store NVT-ASCII as five 7-bit ASCII characters, left-justified in a 36-bit word. 360’s store NVT-ASCII as 8-bit EBCDIC codes. Multics stores NVT-ASCII as four 9-bit characters in a 36-bit word. It may be desirable to convert characters into the standard NVT-ASCII representation when transmitting text between dissimilar systems. The sending and receiving sites would have to perform the necessary transformations between the standard representation and their internal representations.(please refer Data representation and storage section of RFC 765 for further detail).
Linux — How to change encoding in many files?, It will use temp file with ‘.converted’ suffix (extension) and then will move it to original name, so be careful if you have files with ‘.converted’ suffixes (I don’t think you have). Also this script is not safe for filenames containing spaces, so for more safety you should double-quote: «<>» instead of <> and «<>.converted» …
How to change character encoding of a text file on Linux
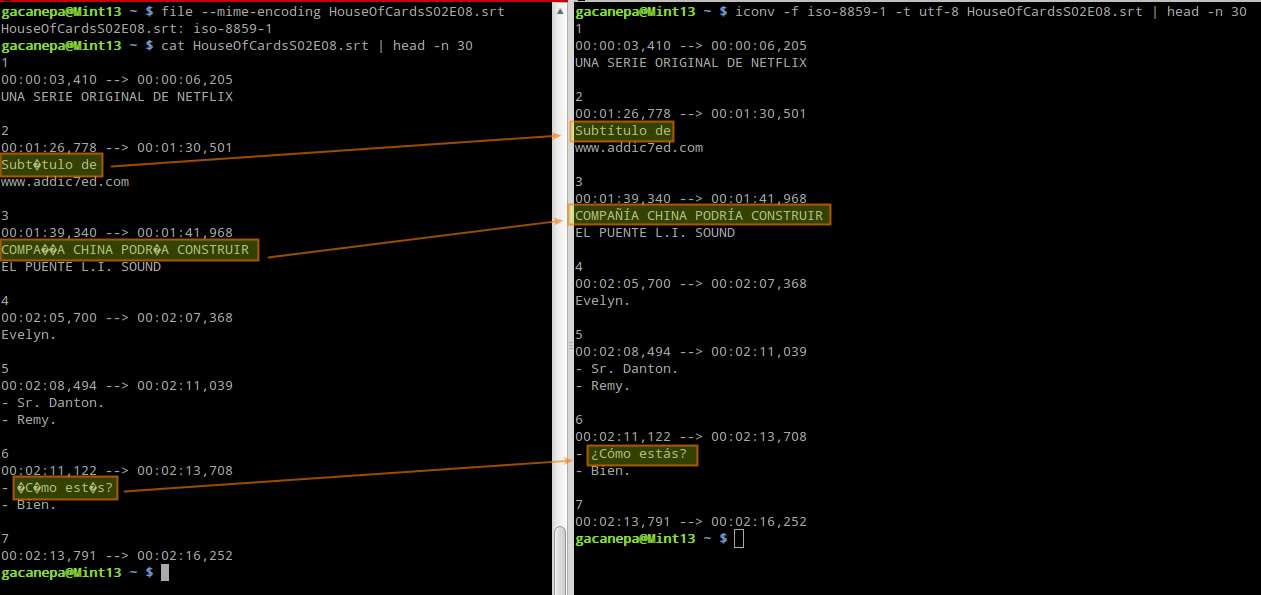
Question: I have an «iso-8859-1»-encoded subtitle file which shows broken characters on my Linux system, and I would like to change its text encoding to «utf-8» character set. In Linux, what is a good tool to convert character encoding in a text file?
As you already know, computers can only handle binary numbers at the lowest level — not characters. When a text file is saved, each character in that file is mapped to bits, and it is those «bits» that are actually stored on disk. When an application later opens that text file, each of those binary numbers are read and mapped back to the original characters that are understood by us human. This «save and open» process is best performed when all applications that need access to a text file «understand» its encoding, meaning the way binary numbers are mapped to characters, and thus can ensure a «round trip» of understandable data.
If different applications do not use the same encoding while dealing with a text file, non-readable characters will be shown wherever special characters are found in the original file. By special characters we mean those that are not part of the English alphabet, such as accented characters (e.g., ñ, á, ü).
The questions then become: 1) how can I know which character encoding a certain text file is using?, and 2) how can I convert it to some other encoding of my choosing?
Step One: Detect Character Encoding of a File
In order to find out the character encoding of a file, we will use a commad-line tool called file . Since the file command is a standard UNIX program, we can expect to find it in all modern Linux distros.
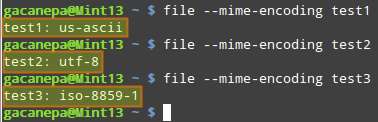
Run the following command:
$ file --mime-encoding filename
Step Two: Find Out Supported Text Encodings
The next step is to check what kinds of text encodings are supported on your Linux system. For this, we will use a tool called iconv with the -l flag (lowercase L), which will list all the currently supported encodings.
The iconv utility is part of the the GNU libc libraries, so it is available in all Linux distributions out-of-the-box.
Step Three: Convert Text Encoding
Once we have selected a target encoding among those supported on our Linux system, let’s run the following command to perform the conversion:
$ iconv -f old_encoding -t new_encoding filename
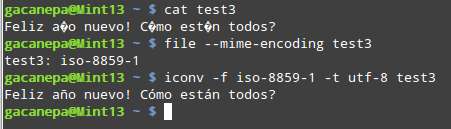
For example, to convert iso-8859-1 to utf-8 :
$ iconv -f iso-8859-1 -t utf-8 input.txt
Knowing how to use these tools together as we have demonstrated, you can for example fix a broken subtitle file:
Support Xmodulo
This website is made possible by minimal ads and your gracious donation via PayPal or credit card
Please note that this article is published by Xmodulo.com under a Creative Commons Attribution-ShareAlike 3.0 Unported License. If you would like to use the whole or any part of this article, you need to cite this web page at Xmodulo.com as the original source.