join Command in Linux
The join command in UNIX is a command line utility for joining lines of two files on a common field.
Suppose you have two files and there is a need to combine these two files in a way that the output makes even more sense.For example, there could be a file containing names and the other containing ID’s and the requirement is to combine both files in such a way that the names and corresponding ID’s appear in the same line. join command is the tool for it. join command is used to join the two files based on a key field present in both the files. The input file can be separated by white space or any delimiter.
Syntax:
$join [OPTION] FILE1 FILE2
Example : Let us assume there are two files file1.txt and file2.txt and we want to combine the contents of these two files.
// displaying the contents of first file // $cat file1.txt 1 AAYUSH 2 APAAR 3 HEMANT 4 KARTIK // displaying contents of second file // $cat file2.txt 1 101 2 102 3 103 4 104
Now, in order to combine two files the files must have some common field. In this case, we have the numbering 1, 2. as the common field in both the files.
NOTE : When using join command, both the input files should be sorted on the KEY on which we are going to join the files.
//..using join command. // $join file1.txt file2.txt 1 AAYUSH 101 2 APAAR 102 3 HEMANT 103 4 KARTIK 104 // by default join command takes the first column as the key to join as in the above case //
So, the output contains the key followed by all the matching columns from the first file file1.txt, followed by all the columns of second file file2.txt.
Now, if we wanted to create a new file with the joined contents, we could use the following command:
$join file1.txt file2.txt > newjoinfile.txt //..this will direct the output of joined files into a new file newjoinfile.txt containing the same output as the example above..//
Options for join command:
1. -a FILENUM : Also, print unpairable lines from file FILENUM, where FILENUM is 1 or 2, corresponding to FILE1 or FILE2.
2. -e EMPTY : Replace missing input fields with EMPTY.
3. -i — -ignore-case : Ignore differences in case when comparing fields.
4. -j FIELD : Equivalent to «-1 FIELD -2 FIELD».
5. -o FORMAT : Obey FORMAT while constructing output line.
6. -t CHAR : Use CHAR as input and output field separator.
7. -v FILENUM : Like -a FILENUM, but suppress joined output lines.
8. -1 FIELD : Join on this FIELD of file 1.
9. -2 FIELD : Join on this FIELD of file 2.
10. — -check-order : Check that the input is correctly sorted, even if all input lines are pairable.
11. — -nocheck-order : Do not check that the input is correctly sorted.
12. — -help : Display a help message and exit.
13. — -version : Display version information and exit.
Using join with options
1. using -a FILENUM option : Now, sometimes it is possible that one of the files contain extra fields so what join command does in that case is that by default, it only prints pairable lines. For example, even if file file1.txt contains an extra field provided that the contents of file2.txt are same then the output produced by join command would be same:
//displaying the contents of file1.txt// $cat file1.txt 1 AAYUSH 2 APAAR 3 HEMANT 4 KARTIK 5 DEEPAK //displaying contents of file2.txt// $cat file2.txt 1 101 2 102 3 103 4 104 //using join command// $join file1.txt file2.txt 1 AAYUSH 101 2 APAAR 102 3 HEMANT 103 4 KARTIK 104 // although file1.txt has extra field the output is not affected cause the 5 column in file1.txt was unpairable with any in file2.txt//
What if such unpairable lines are important and must be visible after joining the files. In such cases we can use -a option with join command which will help in displaying such unpairable lines. This option requires the user to pass a file number so that the tool knows which file you are talking about.
//using join with -a option// //1 is used with -a to display the contents of first file passed// $join file1.txt file2.txt -a 1 1 AAYUSH 101 2 APAAR 102 3 HEMANT 103 4 KARTIK 104 5 DEEPAK //5 column of first file is also displayed with help of -a option although it is unpairable//
2. using -v option : Now, in case you only want to print unpairable lines i.e suppress the paired lines in output then -v option is used with join command.
This option works exactly the way -a works(in terms of 1 used with -v in example below).
//using -v option with join// $join file1.txt file2.txt -v 1 5 DEEPAK //the output only prints unpairable lines found in first file passed//
3. using -1, -2 and -j option : As we already know that join combines lines of files on a common field, which is first field by default.However, it is not necessary that the common key in the both files always be the first column.join command provides options if the common key is other than the first column.
Now, if you want the second field of either file or both the files to be the common field for join, you can do this by using the -1 and -2 command line options. The -1 and -2 here represents he first and second file and these options requires a numeric argument that refers to the joining field for the corresponding file. This will be easily understandable with the example below:
//displaying contents of first file// $cat file1.txt AAYUSH 1 APAAR 2 HEMANT 3 KARTIK 4 //displaying contents of second file// $cat file2.txt 101 1 102 2 103 3 104 4 //now using join command // $join -1 2 -2 2 file1.txt file2.txt 1 AAYUSH 101 2 APAAR 102 3 HEMANT 103 4 KARTIK 104 //here -1 2 refers to the use of 2 column of first file as the common field and -2 2 refers to the use of 2 column of second file as the common field for joining//
So, this is how we can use different columns other than the first as the common field for joining.
In case, we have the position of common field same in both the files(other than first) then we can simply replace the part -1[field] -2[field] in the command with -j[field]. So, in the above case the command could be:
//using -j option with join// $join -j2 file1.txt file2.txt 1 AAYUSH 101 2 APAAR 102 3 HEMANT 103 4 KARTIK 104
4. using -i option : Now, other thing about join command is that by default, it is case sensitive. For example, consider the following examples:
//displaying contents of file1.txt// $cat file1.txt A AAYUSH B APAAR C HEMANT D KARTIK //displaying contents of file2.txt// $cat file2.txt a 101 b 102 c 103 d 104
Now, if you try joining these two files, using the default (first) common field, nothing will happen. That’s because the case of field elements in both files is different. To make join ignore this case issue, use the -i command line option.
//using -i option with join// $join -i file1.txt file2.txt A AAYUSH 101 B APAAR 102 C HEMANT 103 D KARTIK 104
5. using — -nocheck-order option : By default, the join command checks whether or not the supplied input is sorted, and reports if not. In order to remove this error/warning then we have to use — -nocheck-order command like:
//syntax of join with --nocheck-order option// $join --nocheck-order file1 file2
6. using -t option : Most of the times, files contain some delimiter to separate the columns. Let us update the files with comma delimiter.
$cat file1.txt 1, AAYUSH 2, APAAR 3, HEMANT 4, KARTIK 5, DEEPAK //displaying contents of file2.txt// $cat file2.txt 1, 101 2, 102 3, 103 4, 104
Now, -t option is the one we use to specify the delimiterin such cases.
Since comma is the delimiter we will specify it along with -t.
//using join with -t option// $join -t, file1.txt file2.txt 1, AAYUSH, 101 2, APAAR, 102 3, HEMANT, 103 4, KARTIK, 104
How to Join or Merge Text Files in Linux
The Linux cat command is one of the most versatile tools that can use to create files, view them, and even combine them in the Linux command line.
In this article, we take a detour and explore how you can join two text files in Linux using the cat command, (short for “concatenate”) is one of the most commonly used commands in Linux as well as other UNIX-like operating systems, used to concatenate files and print on the standard output.
It is not only used to view files but can also be used to create files together with the redirection character.
View Contents of File in Linux
Suppose you have three text files: sample1.txt, sample2.txt, and sample.3.txt.
To view the contents of these files without opening them, you can use the cat command as shown (remember to replace sample1.txt , sample2.txt and domains3.txt with the names of the files you wish to combine):
$ cat sample1.txt sample2.txt sample3.txt
This provides the following output, with each line in the output corresponding to the files in order of appearance.
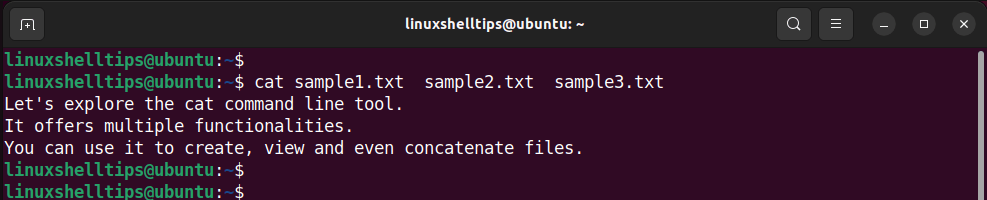
Join Contents of Three Files in Linux
To join the three files into one text file, we will use the output redirection operator (>) to redirect output from all the files to a new file. In this example, we have redirected content from all three files to sample4.txt.
$ cat sample1.txt sample2.txt sample3.txt > sample4.txt The new file now contains content from all the text files, which you can verify by running the following command.
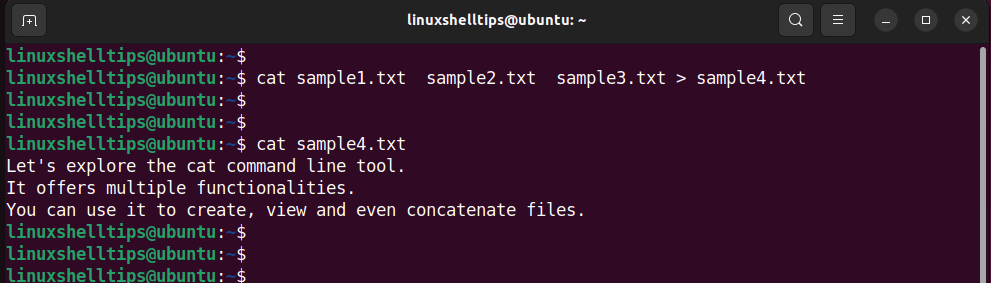
CAUTION: The sample4.txt file is overwritten if it already exists. Therefore proceed with caution when using the redirection operator.
A better option is to append the content of the files to an already existing file. This prevents the deletion of pre-existing content. To achieve this, use the double redirection operator (>>) followed by the file name of the file you want to append the content.
The previous command can be modified as follows:
$ cat sample1.txt sample2.txt sample3.txt >> sample4.txt This ensures that the existing file is not overwritten. Instead content from the other files is simply added or appended to it.
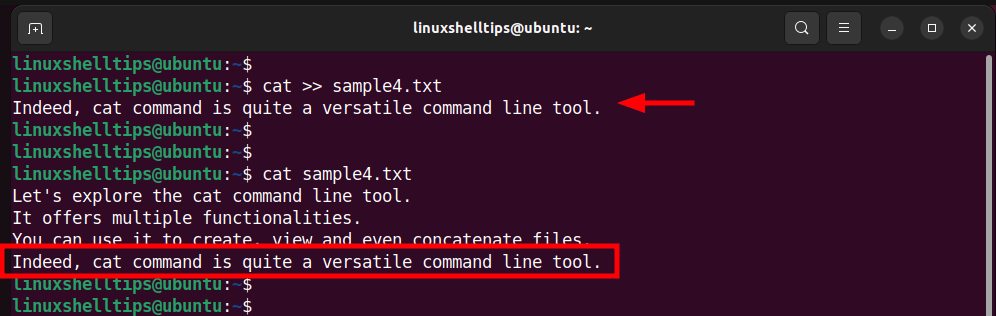
Append File Contents to New File in Linux
Alternatively, to append content to the file, simply type the cat command followed by the double redirection operator and then the name of the file. Upon pressing ENTER, type in the content you want to add. Then hit ENTER again and press ctrl + d to save the changes made.
Merge Contents of Files Using Sed Command
Alternatively, you can also use the popular sed (a streamer editor) to join or merge the content of two or more files on the command-line, by using its r flag, which instructs sed to read the file provided as an argument. If there are many files, it reads all of them and displays their content as a combined output.
$ sed r sample1.txt sample1.txt sample3.txt $ sed r sample1.txt sample1.txt sample3.txt > sample4.txt $ cat sample4.txt That was a short guide on how you can join two or more text files on Linux. Any additional ideas you might have up your sleeve? Do let us know in the comment section.
Join two files on Linux
thanks, no it’s a big file. I made it easy for understanding. but if I can do this example that will work too.
5 Answers 5
A simple awk is suffice for this:
awk 'FNR==NR ' t1 t2 1 1.2 2 2.2 1 1.2 join requires that both files to be sorted. If you sort them first, you’ll get all your output
$ sort t1 > t1.sorted $ sort t2 > t2.sorted $ join -j1 -o 1.1,1.2 t1.sorted t2.sorted 1 1.2 1 1.2 2 2.2 $ join -j1 -o 1.1,1.2 t1 t2 1 1.2 2 2.2 This assumes that the order of your inputs don’t need to be preserved; if they do, you will need a custom script like other answers have provided.
If I understand you want to match the first column of t1 with the values in t2 . So t1 is a dictionnary and t2 the wanted keys.
$ cat t2 | xargs -n1 -I<> grep -P "^\Q<>\E\s+" t1 xargs will execute the command grep for each one entry -n1 of t2 . The -I<> allows me to put the value where I want to.
Then I execute grep which match the wanted value from the dictionary using a regular expression.
^ # Any line that begin with \Q # Quote the value (in case we have special chars inside it) <> # The corresponding value matched by xargs \E # End of quoting \s+ # Followed by one or more spaces (alternatively we can use `\b`) .* # Followed by anything (optional) t1 # Inside the file `t1` Alternatively you can play with Perl 🙂
cat t2 | perl -e '$_ = qx; \ $t1 = $2 while(/^(\w+)\s+(.*)/gm); \ print "$t1\n" for (split "\n", do>)' t1