- Saved searches
- Use saved searches to filter your results more quickly
- gudarikon/image-to-code
- Name already in use
- Sign In Required
- Launching GitHub Desktop
- Launching GitHub Desktop
- Launching Xcode
- Launching Visual Studio Code
- Latest commit
- Git stats
- Files
- README.md
- About
- Image to G Code
- 2. Integrating image-to-gcode with the AXIS user interface
- 3. Using image-to-gcode
- 4. Option Reference
- 4.1. Units
- 4.2. Invert Image
- 4.3. Normalize Image
- 4.4. Expand Image Border
- 4.5. Tolerance (units)
- 4.6. Pixel Size (units)
- 4.7. Plunge Feed Rate (units per minute)
- 4.8. Feed Rate (units per minute)
- 4.9. Spindle Speed (RPM)
- 4.10. Scan Pattern
- 4.11. Scan Direction
- 4.12. Depth (units)
- 4.13. Step Over (pixels)
- 4.14. Tool Diameter
- 4.15. Safety Height
- 4.16. Tool Type
- 4.17. Lace bounding
- 4.18. Contact angle
- 4.19. Roughing offset and depth per pass
Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
This repository contains code image dataset generator and NLP model for recognizing code from image
gudarikon/image-to-code
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
This is a repository with a source code of image to code generation. The repository contains code image dataset generator, OCR model, NLP model for recognizing code from text and telegram bot script.

Code to image dataset generator
A dataset generator is separate tool from the whole pipeline. It was created specifically for this project to generate dataset which contains code and its screenshots.
- An IntelliJ IDE for any language:
- IntelliJ IDEA
- PyCharm
- GoLand
- PhpStorm
- etc.
- A 1920×1080 resolution screen
Image generator works in two modes: code blocks screenshots and functions screenshots.
- Remove breadcrumbs: Right lick on the bottom panel showing current classes, methods, etc. (In this screenshot it shows OCRProcessor>process_image() )
 Choose Breadcrumbs in the opened menu, pick Don’t Show Later breadcrumbs are restored in theEditor | General | Breadcrumbsmenu
Choose Breadcrumbs in the opened menu, pick Don’t Show Later breadcrumbs are restored in theEditor | General | Breadcrumbsmenu - Open terminal window — click Run in the bottom panel, then move opened window to the bottom:
- Remove gutter icons: right click in gutter | Configure Gutter Icons. | Show gutter icons
- Open filetree and move it to the maximal left position.
- Set language to English.
- Compact View of inspections (top right corner):
- Remove ligatures in Editor | Font | Enable ligatures
 Choose Breadcrumbs in the opened menu, pick Don’t Show Later breadcrumbs are restored in theEditor | General | Breadcrumbsmenu
Choose Breadcrumbs in the opened menu, pick Don’t Show Later breadcrumbs are restored in theEditor | General | Breadcrumbsmenu

Using code blocks screenshots
- Open IntelliJ project
- Set repo_path in config.json to project path
- Run code_to_image/main_code_blocks.py
Using functions screenshots
- Create empty IntelliJ project
- Run dataset_parser.py , with repo_path in config.json set to empty project, code_search_functions_path to jsonl dataset from code search net
- Run code_to_image/main_functions.py
Config is stored in config.json. Here you can specify data folders and change path to repository that is opened in intellij IDE. If you manually moved Run panel or filetree panel, change visible_lines and visible_symbols to -1 and move it as you did in preparation steps.
If you want to stop the program, move your mouse during screenshots. The program will exit after current file is finished. All traversed files are saved.
This part contains info about OCR processors used to extract text from the images. Available solutions could be found in src/image_to_text/processors/
New solutions could be easily added using src/image_to_text/processors/ocr_processor.py base class. Don’t forget to add custom processor to src/image_to_text/processors.__init__ for convenient access via strings in src/image_to_text/img_to_text.py
First of all one should install Tesseract on the machine.
Install Google Tesseract OCR _ (additional info how to install the engine on Linux, Mac OSX and Windows). You must be able to invoke the tesseract command as tesseract. If this isn’t the case, for example because tesseract isn’t in your PATH, you will have to change the «tesseract_cmd» variable pytesseract.pytesseract.tesseract_cmd . Under Debian/Ubuntu you can use the package tesseract-ocr. For Mac OS users. please install homebrew package tesseract.
Once Tesseract is installed the path to tesseract.exe file should be added to the local .env file. See .env.example template.
More advanced OCR for image processing. Supports text boxes which allow to add line spacing to the parsed text.
All the processors classes contain **kwargs essential for the proper operation. Thus, .json formatted config templates are provided in resources/configs/
For this task we settled on CodeT5
The model provides easy fine-tune interface (even for refine task), using which we created different models that can fix buggy code. We trained it in Google Colab in our forked repository — MassterMax/CodeT5 (in CodeT5/TuningT5.ipynb file). For refine task fine-tuning we use our dataset (nearly 600 examples of source code and OCR predicted text), with codet5_small model.
Also, to improve quality, we calculate most common OCR mistakes and tried to augment dataset with them:
| Source code symbol | Symbol after OCR | Conditional error rate |
|---|---|---|
| O (capital letter) | 0 (zero) | 14.32% |
| O (capital letter) | o | 10.01% |
| S | s | 09.34% |
| C | c | 09.30% |
| 0 (zero) | o | 08.23% |
| g | q | 06.28% |
| > | 1 | 05.99% |
| | (vertical bar) | I (capital letter) | 04.44% |
| « | u | 03.77% |
| s | S | 03.48% |
We add CodeT5/run_data_preprocessing.py file that extends our source dataset with augmentations and creates datasets in model format. After that, the training pipeline starts with:
python3 run_exp.py --model_tag codet5_small --task refine --sub_task small
We now are trying to improve NLP model and searching for other solutions.
For launching the whole pipeline you can run the following:
~$ /cd image-to-code /image-to-code$ PYTHONPATH=./ python3 \ src/telegram_handler/pipeline_manager.py \ /path/to/image.png We are deploying the bot via GitHub action .github/workflows/deploy_action.yml and run.sh files, you can reuse them in your project.
Image To Code Bot is ready to receive images to return OCR text and parsed code from them.
Currently the bot supports two operations:
- /start — the bot will greet you
- — the bot will answer with two blocks — OCR text result and code result (after applied T5Code tuned refine model). Note that the bot will reply only for one non-document image per request
The default license for this repository is Apache 2.0.
About
This repository contains code image dataset generator and NLP model for recognizing code from image
Image to G Code
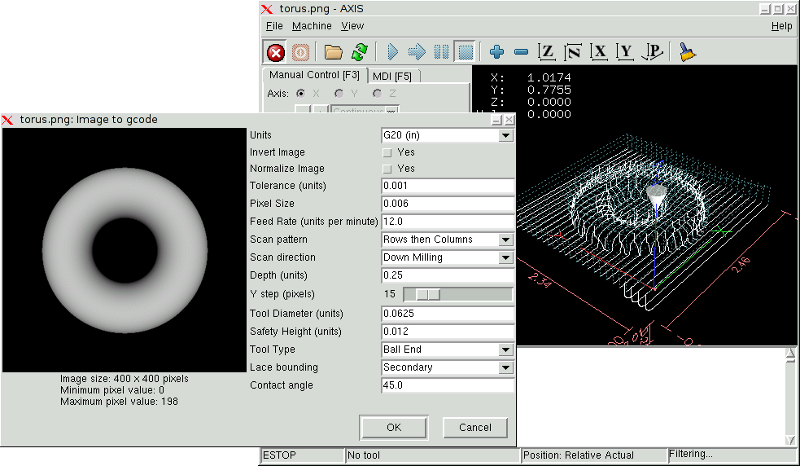
A depth map is a greyscale image where the brightness of each pixel corresponds to the depth (or height) of the object at each point.
2. Integrating image-to-gcode with the AXIS user interface
Add the following lines to the [FILTER] section of your .ini file to make AXIS automatically invoke image-to-gcode when you open a .png, .gif, or .jpg image
PROGRAM_EXTENSION = .png,.gif,.jpg Grayscale Depth Image png = image-to-gcode gif = image-to-gcode jpg = image-to-gcode
The standard sim/axis.ini configuration file is already configured this way.
3. Using image-to-gcode
Start image-to-gcode either by opening an image file in AXIS, or by invoking image-to-gcode from the terminal, as follows:
image-to-gcode torus.png > torus.ngc
Verify all the settings in the right-hand column, then press OK to create the gcode. Depending on the image size and options chosen, this may take from a few seconds to a few minutes. If you are loading the image in AXIS, the gcode will automatically be loaded and previewed once image-to-gcode completes. In AXIS, hitting reload will show the image-to-gcode option screen again, allowing you to tweak them.
4. Option Reference
4.1. Units
Specifies whether to use G20 (inches) or G21 (mm) in the generated g-code and as the units for each option labeled (units).
4.2. Invert Image
If “no”, the black pixel is the lowest point and the white pixel is the highest point. If “yes”, the black pixel is the highest point and the white pixel is the lowest point.
4.3. Normalize Image
If yes, the darkest pixel is remapped to black, the lightest pixel is remapped to white.
4.4. Expand Image Border
If None, the input image is used as-is, and details which are at the very edges of the image may be cut off. If White or Black, then a border of pixels equal to the tool diameter is added on all sides, and details which are at the very edges of the images will not be cut off.
4.5. Tolerance (units)
When a series of points are within tolerance of being a straight line, they are output as a straight line. Increasing tolerance can lead to better contouring performance in LinuxCNC, but can also remove or blur small details in the image.
4.6. Pixel Size (units)
One pixel in the input image will be this many units—usually this number is much smaller than 1.0. For instance, to mill a 2.5×2.5-inch object from a 400×400 image file, use a pixel size of .00625, because 2.5 / 400 = .00625.
4.7. Plunge Feed Rate (units per minute)
The feed rate for the initial plunge movement.
4.8. Feed Rate (units per minute)
The feed rate for other parts of the path.
4.9. Spindle Speed (RPM)
The spindle speed S code that should be put into the gcode file.
4.10. Scan Pattern
Possible scan patterns are:
4.11. Scan Direction
Possible scan directions are:
- Positive: Start milling at a low X or Y axis value, and move towards a high X or Y axis value
- Negative: Start milling at a high X or Y axis value, and move towards a low X or Y axis value
- Alternating: Start on the same end of the X or Y axis travel that the last move ended on. This reduces the amount of traverse movements
- Up Milling: Start milling at low points, moving towards high points
- Down Milling: Start milling at high points, moving towards low points
4.12. Depth (units)
The top of material is always at Z=0. The deepest cut into the material is Z=-depth.
4.13. Step Over (pixels)
The distance between adjacent rows or columns. To find the number of pixels for a given units distance, compute distance/pixel size and round to the nearest whole number. For example, if pixel size=.006 and the desired step over distance=.015, then use a Step Over of 2 or 3 pixels, because .015/.006=2.5‘.’
4.14. Tool Diameter
The diameter of the cutting part of the tool.
4.15. Safety Height
The height to move to for traverse movements. image-to-gcode always assumes the top of material is at Z=0.
4.16. Tool Type
The shape of the cutting part of the tool. Possible tool shapes are:
4.17. Lace bounding
This controls whether areas that are relatively flat along a row or column are skipped. This option only makes sense when both rows and columns are being milled. Possible bounding options are:
- None: Rows and columns are both fully milled.
- Secondary: When milling in the second direction, areas that do not strongly slope in that direction are skipped.
- Full: When milling in the first direction, areas that strongly slope in the second direction are skipped. When milling in the second direction, areas that do not strongly slope in that direction are skipped.
4.18. Contact angle
When Lace bounding is not None, slopes greater than Contact angle are considered to be strong slopes, and slopes less than that angle are considered to be weak slopes.
4.19. Roughing offset and depth per pass
Image-to-gcode can optionally perform rouging passes. The depth of successive roughing passes is given by Roughing depth per pass. For instance, entering 0.2 will perform the first roughing pass with a depth of 0.2, the second roughing pass with a depth of 0.4, and so on until the full Depth of the image is reached. No part of any roughing pass will cut closer than Roughing Offset to the final part. The following figure shows a tall vertical feature being milled. In this image, Roughing depth per pass is 0.2 inches and roughing offset is 0.1 inches.