Урок 39
Виды моделей данных
— что представляет собой модель данных;
— в чем особенность иерархической модели данных;
— в чем особенность сетевой модели данных;
— в чем особенность реляционной модели данных;
— как устанавливаются связи в реляционной модели.
Сетевая модель данных
Сетевая модель, как и иерархическая, отражает взаимосвязь информационных объектов. Она базируется на тех же основных понятиях: узел, уровень, связь. Основным ее отличием является то, что каждый элемент одного уровня в сетевой модели может быть связан с любым количеством элементов другого уровня. Свойства сетевой модели:
♦ Каждый узел имеет имя (идентификатор).
♦ Узлы одного уровня образуют один класс объектов.
♦ Каждый узел одного уровня может быть связан с произвольным количеством узлов другого уровня.
В качестве примера можно рассмотреть базу данных, в которой хранятся сведения об увлечениях подростков (рис. 4.8). В модели представлены два уровня (класса): увлечения и подростки. Связи показывают увлечения конкретных подростков. С одной стороны, каждый подросток может иметь несколько увлечений. С другой стороны, одно увлечение может быть у многих подростков. Связи такого типа называются «многие-ко-многим», для них введено условное обозначение М:М.
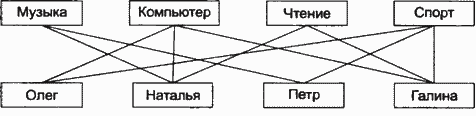
Рис. 4.8. Пример сетевой модели
Реляционная модель данных
Таблица является одним из наиболее удобных и привычных человеку способов представления данных. Это свойство и определило основу реляционной модели данных, на которую сориентировано большинство современных СУБД — систем управления базами данных.
Реляционная модель данных представляет собой совокупность таблиц с установленными между ними связями. Название «реляционная» происходит от английского слова relation — отношение. Этот термин указывает, что модель отражает отношения составляющих ее частей.
В реляционной модели каждая таблица описывает один класс объектов.
Рассмотрим таблицу, содержащую сведения об учениках школы: номер личного дела, фамилия, имя, отчество, дата рождения (табл. 4.2). В ней описывается класс объектов Ученики.
Каждый столбец в такой таблице называется полем. Верхняя строка содержит названия параметров объекта и отображает структуру записи.
Каждая последующая строка является записью.
С такой формой хранения данных мы знакомились уже в начале этого раздела. Реляционная модель данных имеет следующие свойства.
Таблица 4.2. Ученики

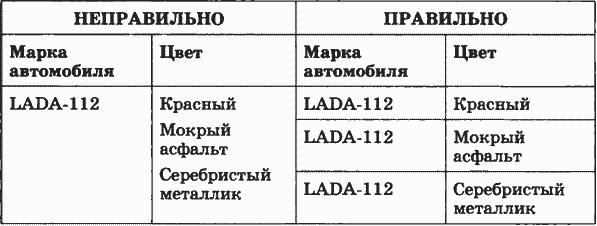
1. Каждый элемент таблицы — один элемент данных. Элементом таблицы является ячейка. Данное свойство означает, что в одной ячейке реляционной таблицы не может указываться более одного значения параметра. Ниже показано правильное и неправильное представление данных.
2. Все элементы одного столбца (поля) имеют одинаковый тип (числовой, символьный и т. п.), формат и смысл. Данное свойство указывает, что в одном столбце таблицы не могут содержаться данные разных типов, например, и текст, и числа. Кроме того, данные одного типа (например, дата) должны иметь одинаковый формат, то есть нельзя в одном столбце записать дату сначала так: 8 сентября 2003 года, а потом так: 23.11.2001. И наконец, все данные одного столбца должны иметь одинаковый смысл. Иначе говоря, если в столбце установлен тип «Дата», то она должна для всех записей означать одно и то же, например дату рождения.
3. Каждый столбец (поле) имеет уникальное имя. Это свойство означает, что в таблице не может быть столбца, не имеющего имени, и не может быть двух столбцов с одинаковыми именами. В разных таблицах одной модели одинаковые имена столбцов допустимы, но нежелательны.
4. Одинаковые строки в таблице отсутствуют. Это означает, что каждая строка описывает конкретный объект. Если, например, в базе данных описываются автомобили, то в реальной жизни вполне допустимо, что два автомобиля имеют одинаковые характеристики: и марку, и цвет, и объем двигателя и пр. Чтобы различить автомобили-близнецы вводят специальный параметр — заводской номер двигателя. Таким образом, в таблице может оказаться несколько похожих записей, которые будут отличаться только заводским номером двигателя.
5. Порядок следования строк в таблице может быть произвольным. Это означает, что информация об объекте одного класса не зависит от информации о другом объекте этого же класса.
6. Каждая таблица должна иметь ключ. Ключ (ключевой элемент) — это поле или совокупность полей, которые единственным образом определяют каждую строку (запись) в таблице. Таким образом, все строки таблицы являются уникальными, то есть не может быть строк с одинаковыми ключами. Например, в табл. 4.2 в качестве ключевого поля можно выбрать поле Номер личного дела, а другие поля в качестве ключа выбрать нельзя, потому что значения в них могут повторяться.
7. Таблицы, входящие в модель данных, могут характеризоваться разным количеством полей и записей. Каждая таблица описывает определенный класс объектов, который может характеризоваться своим набором параметров, и, соответственно, таблицы могут иметь разную структуру, а также количество записей.
Рассмотрим приведенную выше табл. 4.2, в которой хранятся сведения об учениках школы. Эта модель данных является реляционной, так как она удовлетворяет всем перечисленным свойствам реляционных таблиц. В каждой ячейке таблицы записано только одно значение какого-либо признака (свойство 1). Информация в каждом столбце имеет одинаковый тип, формат записи и смысл (свойство 2). Заголовки столбцов имеют разные имена (свойство 3). Одинаковые строки отсутствуют (свойство 4). Сведения об одном ученике никак не зависит от сведений о других учениках, следовательно, строки можно расположить в любом порядке (свойство 5). Поле Номер личного дела можно выбрать в качестве ключа (свойство 6).
Над данной моделью базы удобно производить следующие действия:
— сортировку данных (например, по алфавиту);
— выборку данных по группам (например, по датам рождения или по фамилиям);
— поиск записей (например, по фамилиям) и т. д.
Контрольные вопросы и задания
1. Что такое модель данных и для чего она нужна?
2. Приведите определение информационной модели и сопоставьте его с определением модели данных. Найдите у них общие и различающиеся характеристики.
3. Какие вы знаете формы представления информационной модели? Сравните их и сделайте вывод о том, когда лучше использовать ту или иную форму представления.
4. Приведите примеры моделей данных для разных предметных областей.
5. Что представляет собой иерархическая модель данных в общем виде?
6. Что такое узел иерархической модели данных?
7. В чем состоят свойства иерархической модели данных?
8. Приведите примеры иерархических моделей данных.
9. Что представляет собой сетевая модель данных в общем виде?
10. В чем состоят свойства сетевой модели данных?
11. Приведите примеры сетевых моделей данных.
12. Что представляет собой реляционная модель данных в общем виде?
13. Как вы понимаете связь между информационными объектами 1:1? Приведите примеры такого типа связей.
14. Как вы понимаете связь между информационными объектами 1:М? Приведите примеры этого типа связей.
15. Как вы понимаете связь между информационными объектами М:М? Приведите примеры данного типа связей.
16. В чем состоят свойства реляционной модели данных?
17. Приведите примеры реляционных моделей данных.
18. Как графически отображается реляционная модель данных?
19. Приведите примеры преобразования иерархической модели в реляционную.
20. Приведите примеры преобразования сетевой модели в реляционную.
3)Сетевые информационные модели
Сетевые информационные модели применяются для отражения систем со сложной структурой, в которых связи между элементами имеют произвольный характер.
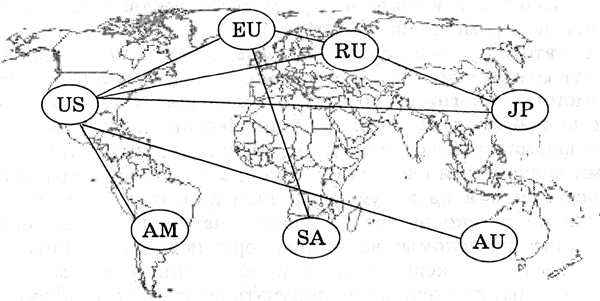
Например, различные региональные части глобальной компьютерной сети Интернет (американская, европейская, российская, австралийская и так далее) связаны между собой высокоскоростными линиями связи. При этом одни части (например, американская) имеют прямые связи со всеми региональными частями Интернета, а другие могут обмениваться информацией между собой только через американскую часть (например, российская и австралийская).
Построим граф, который отражает структуру глобальной сети Интернет (рис. 2.7). Вершинами графа являются региональные сети. Связи между вершинами носят двусторонний характер и поэтому изображаются ненаправленными линиями (ребрами), а сам граф поэтому называется неориентированным.
Представленная сетевая информационная модель является статической моделью. С помощью сетевой динамической модели можно, например, описать процесс передачи мяча между игроками в коллективной игре (футболе, баскетболе и так далее).
1) Алгоритм — набор инструкций, описывающих порядок действий исполнителя для достижения результата решения задачи за конечное время. В старой трактовке вместо слова «порядок» использовалось слово «последовательность», но по мере развития параллельности в работе компьютеров слово «последовательность» стали заменять более общим словом «порядок». Это связано с тем, что работа каких-то инструкций алгоритма может быть зависима от других инструкций или результатов их работы. Таким образом, некоторые инструкции должны выполняться строго после завершения работы инструкций, от которых они зависят. Независимые инструкции или инструкции, ставшие независимыми из-за завершения работы инструкций, от которых они зависят, могут выполняться в произвольном порядке, параллельно или одновременно, если это позволяют используемые процессор и операционная система.
Линейный (последовательный) алгоритм — описание действий, которые выполняются однократно в заданном порядке.
Линейными являются алгоритмы отпирания дверей, заваривания чая, приготовления одного бутерброда. Линейный алгоритм применяется при вычислении арифметического выражения, если в нем используются только действия сложения и вычитания.
Циклический алгоритм — описание действий, которые должны по вторяться указанное число раз или пока не выполнено заданное условие. Перечень повторяющихся действий называется телом цикла.
Многие процессы в окружающем мире основаны на многократном повторении одной и той же последовательности действий. Каждый год наступают весна, лето, осень и зима. Жизнь растений в течение года проходит одни и те же циклы. Подсчитывая число полных поворотов минутной или часовой стрелки, человек измеряет время.
Условие — выражение, находящееся между словом «если» и словом «то» и принимающее значение «истина» или «ложь».
Разветвляющийся алгоритм — алгоритм, в котором в зависимости от условия выполняется либо одна, либо другая последовательность действий.
Примеры разветвляющих алгоритмов: если пошел дождь, то надо открыть зонт; если болит горло, то прогулку следует отменить; если билет в кино стоит не больше десяти рублей, то купить билет и занять свое место в зале, иначе (если стоимость билета больше 10 руб.) вернуться домой.
В общем случае схема разветвляющего алгоритма будет выглядеть так: «если условие, то. иначе. ». Такое представление алгоритма получило название полной формы. Неполная форма, в которой действия пропускаются: «если условие, то. ».
Вспомогательный алгоритм — алгоритм, который можно использовать в других алгоритмах, указав только его имя. Например: вы в детстве учились суммировать единицы, затем десятки, чтобы суммировать двузначные числа содержащие единицы вы не учились новому методу суммирования, а воспользовались старыми методами.