- Convert files between UTF-8 and ISO-8859 on Linux
- 2 Answers 2
- How to Convert Files to UTF-8 Encoding in Linux
- Convert Files from UTF-8 to ASCII Encoding
- Convert Multiple Files to UTF-8 Encoding
- Linux bash: Convert filenames recursively from ISO-8859-1 (or other) to UTF-8 and vice versa
- Convert filenames from ISO → UTF-8
- Convert filenames from UTF-8 → ISO
- Details explained
- How to Convert Files to UTF-8 in Linux
- How to Convert Files to UTF-8 in Linux
- 1. Check its present encoding
- 2. Convert Files to UTF-8
- 3. Convert Multiple Files to UTF-8
Convert files between UTF-8 and ISO-8859 on Linux
Every time that I get confronted with Unicode, nothing works. I’m on Linux, and I got these files from Windows:
$file * file1: UTF-8 Unicode text file2: ISO-8859 text file3: ISO-8859 text Nothing was working until I found out that the files have different encodings. I want to make my life easy and have them all in the same format:
iconv -f UTF-8 -t ISO-8859 file1 > test iconv: conversion to `ISO-8859' is not supported Try `iconv --help' or `iconv --usage' for more information. I tried to convert to ISO because that’s only 1 conversion + when I open those ISO files in gedit, the German letter «ü» is displayed just fine. Okay, next try:
iconv -f ISO-8859 -t UTF-8 file2 > test iconv: conversion from `ISO-8859' is not supported Try `iconv --help' or `iconv --usage' for more information. That’s because «ISO-8859» isn’t an encoding. Did you maybe mean ISO-8859-1 or ISO-8859-15? Or one of the other 14?
Also there might be problem with your utf-8 source file. It can contain character, that can’t be represented in ISO-8859. Converting to utf-8 will be much safer.
2 Answers 2
ISO-8859-x (Latin-1) encoding only contains very limited characters, you should always try to encode to UTF-8 to make life easier.
And utf-8 (Unicode) is a superset of ISO 8859 so it will be not surprised you could not convert UTF-8 to ISO 8859
It seems command file just give a very limited info of the file encoding
You could try to guess the from encoding either ISO-8859-1 or ISO-8859-15 or the other from 2~14 as suggested in the comment by @hobbs
And you could get a supported encoding of iconv by iconv -l
If life treats you not easy with guessing the real file encoding, this silly script might help you out 😀
@user3182532 ISO 8859 is the name of a standard with 16 parts that specify 16 different encodings (with some commonalities but various differences). file is telling you that it doesn’t know which one it is. This is the general problem with 8-bit encodings —- it’s easy enough to tell that you have an 8-bit encoding, but figuring out which one without prior knowledge is pure guesswork. Try them and see which one comes out right. 8859-15 is a good first guess.
«utf-8 (Unicode) is a superset of ISO 8859» . I think this is not true. Could you please cite or explain, because in my experience, a file saved as iso-8859-1 interpreted as if it were utf-8 will definitely come out wrong.
@Stewart the set of characters encoded by Unicode is a superset of the set of characters in each of the ISO-8859 charsets. The characters are encoded differently, though.
@PaŭloEbermann @amnotstrong There is a lot of confusion going around here. UTF-8 is not Unicode, UTF-8 is an encoding of Unicode. The way UTF-8 encodes Unicode codepoints means that it is a superset of ASCII however. All valid ASCII characters are identically coded in UTF-8, e.g. A is encoded as decimal 65 in both ASCII and UTF-8. It is also encoded as 65 in all ISO8859 charsets because they are also supersets of ASCII. But UTF-8 is not a superset of any ISO8859 charsets. It is possible to convert from any ISO8859 charset to UTF-8 because UTF-8 encodes all of Unicode.
I guess the word «superset» is a bit too stretched here. Unicode is a set of characters, each with a number (called code point). UTF-8 (and the other UTFs) are an encoding of the unicode characters as bytes. ASCII and ISO-8859-x are character sets (each with different characters) and encodings of these characters into bytes. Unicode is a superset of all these character sets, but the encoding in UTF-8 is different than the encoding in ISO-8859-x. ASCII (as a character set) is a subset of the ISO-8859-x, and also of Unicode, and ASCII (as an encoding) is a «subencoding» of ISO-8859-x and UTF-8).
How to Convert Files to UTF-8 Encoding in Linux
In this guide, we will describe what character encoding and cover a few examples of converting files from one character encoding to another using a command line tool. Then finally, we will look at how to convert several files from any character set (charset) to UTF-8 encoding in Linux.
As you may probably have in mind already, a computer does not understand or store letters, numbers or anything else that we as humans can perceive except bits. A bit has only two possible values, that is either a 0 or 1 , true or false , yes or no . Every other thing such as letters, numbers, images must be represented in bits for a computer to process.
In simple terms, character encoding is a way of informing a computer how to interpret raw zeroes and ones into actual characters, where a character is represented by set of numbers. When we type text in a file, the words and sentences we form are cooked-up from different characters, and characters are organized into a charset.
There are various encoding schemes out there such as ASCII, ANSI, Unicode among others. Below is an example of ASCII encoding.
Character bits A 01000001 B 01000010
In Linux, the iconv command line tool is used to convert text from one form of encoding to another.
You can check the encoding of a file using the file command, by using the -i or —mime flag which enables printing of mime type string as in the examples below:
$ file -i Car.java $ file -i CarDriver.java

The syntax for using iconv is as follows:
$ iconv option $ iconv options -f from-encoding -t to-encoding inputfile(s) -o outputfile
Where -f or —from-code means input encoding and -t or —to-encoding specifies output encoding.
To list all known coded character sets, run the command below:
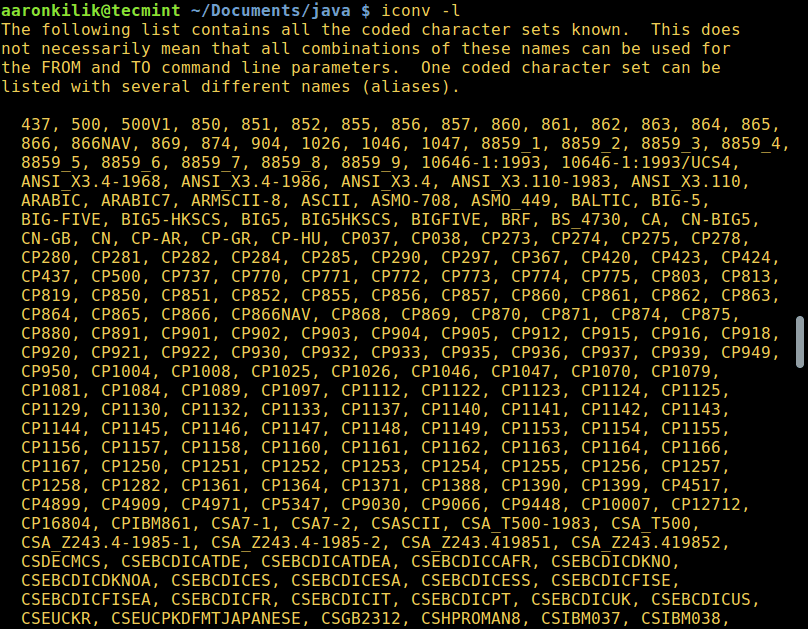
Convert Files from UTF-8 to ASCII Encoding
Next, we will learn how to convert from one encoding scheme to another. The command below converts from ISO-8859-1 to UTF-8 encoding.
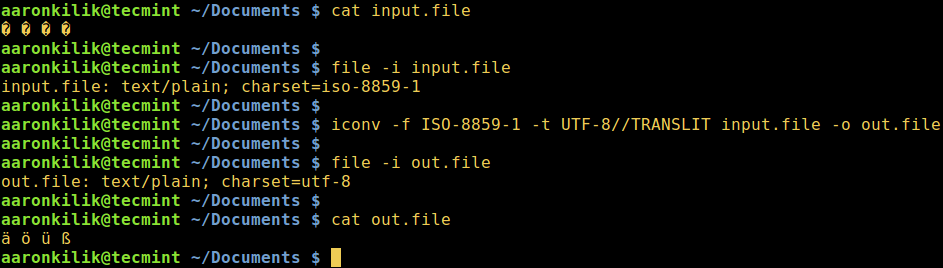
Consider a file named input.file which contains the characters:
Let us start by checking the encoding of the characters in the file and then view the file contents. Closely, we can convert all the characters to ASCII encoding.
After running the iconv command, we then check the contents of the output file and the new encoding of the characters as below.
$ file -i input.file $ cat input.file $ iconv -f ISO-8859-1 -t UTF-8//TRANSLIT input.file -o out.file $ cat out.file $ file -i out.file
Note: In case the string //IGNORE is added to to-encoding, characters that can’t be converted and an error is displayed after conversion.
Again, supposing the string //TRANSLIT is added to to-encoding as in the example above (ASCII//TRANSLIT), characters being converted are transliterated as needed and if possible. Which implies in the event that a character can’t be represented in the target character set, it can be approximated through one or more similar looking characters.
Consequently, any character that can’t be transliterated and is not in target character set is replaced with a question mark (?) in the output.
Convert Multiple Files to UTF-8 Encoding
Coming back to our main topic, to convert multiple or all files in a directory to UTF-8 encoding, you can write a small shell script called encoding.sh as follows:
#!/bin/bash #enter input encoding here FROM_ENCODING="value_here" #output encoding(UTF-8) TO_ENCODING="UTF-8" #convert CONVERT=" iconv -f $FROM_ENCODING -t $TO_ENCODING" #loop to convert multiple files for file in *.txt; do $CONVERT "$file" -o "$.utf8.converted" done exit 0
Save the file, then make the script executable. Run it from the directory where your files ( *.txt ) are located.
$ chmod +x encoding.sh $ ./encoding.sh
Important: You can as well use this script for general conversion of multiple files from one given encoding to another, simply play around with the values of the FROM_ENCODING and TO_ENCODING variable, not forgetting the output file name «$.utf8.converted» .
For more information, look through the iconv man page.
To sum up this guide, understanding encoding and how to convert from one character encoding scheme to another is necessary knowledge for every computer user more so for programmers when it comes to dealing with text.
Lastly, you can get in touch with us by using the comment section below for any questions or feedback.
Linux bash: Convert filenames recursively from ISO-8859-1 (or other) to UTF-8 and vice versa
![]()
Information
This article explains the basic usage to convert ISO to UTF-8 charsets. If you are searching for a sophisticated script check out this page also:
Convert filenames from ISO → UTF-8
convmv -f iso-8859-1 -t utf8 -r ./*
[ this command just shows you what it would do. To actually apply the conversion add the parameter —notest ]
Convert filenames from UTF-8 → ISO
convmv -f utf8 -t iso-8859-1 -r ./*
[ this command just shows you what it would do. To actually apply the conversion add the parameter ‐‐notest ]
Details explained
- convmv: A tool you might need to download and install first. (in Debian enter this on your console: aptitude install convmv)
- parameter «-f» : convert from charset XYZ (see man convmv)
- parameter «-t»: convert to charset XYZ (see man convmv)
- parameter «-r»: convert recursively (all files in all subdirectories)
- parameter «./*»: start conversion in the current directory. You may enter a target directory here like /home/myroot/myfiles
- parameter «‐‐notest»: apply this to actually start the conversion. Without it the command will just show what it would do
How to Convert Files to UTF-8 in Linux

Every file has a character encoding that tells the computer operating system, or any program that uses it, about the file. When we store data in a file, the program that you are using to store data, encodes all the information in a specific format. This format is used by all other programs that read this file. Sometimes you may need to convert files to UTF-8 format, which is universally recognized by most applications. In this article, we will learn how to convert files to UTF-8 in Linux.
How to Convert Files to UTF-8 in Linux
There are many tools that allow you to convert files from one character encoding to another. We will use iconv for our purpose.
1. Check its present encoding
Open terminal and run the file command to check its present coding. Let us say you have sample.txt file.
2. Convert Files to UTF-8
iconv is already installed on most Linux systems by default. Here is the command to convert character encoding of file using iconv command.
$ iconv -f fro_encoding -t to_encoding sample.txt -o out.txt
In the above command you need to specify the present encoding of file in place of from_encoding and the new encoding of file in place of to_encoding.
Here is the command to convert sample.txt from ISO-8859 to UTF-8 format.
$ iconv -f ISO-8859-1 -t UTF-8//TRANSLIT sampl.txte -o out.txt
Next, you can check its new character encoding with the file command.
3. Convert Multiple Files to UTF-8
If you want to convert multiple files in a folder to UTF-8 using iconv, then use a for loop to run the iconv individually on each file. We will create a shell script for it.
Add the following lines to it.
#!/bin/bash #enter input encoding here FROM_ENCODING=$1 #output encoding(UTF-8) TO_ENCODING="UTF-8" #convert CONVERT=" iconv -f $FROM_ENCODING -t $TO_ENCODING" #loop to convert multiple files for file in $2; do $CONVERT "$file" -o "$.utf8.converted" done exit 0
Run the above script with the following command. The first argument is the present encoding of files in your folder and the second argument is the folder location containing files.
$ ./encoding.sh ISO-8859-1 /home/data
The above script will convert all .txt files in the specified folder into UTF-8 and create a separate copy of each file with the extension .utf8.converted.
In this article, we have learnt how to convert files to UTF-8 format. You can use the above steps to convert one or more files.