- Concatenating multiple text files into a single file in Bash
- 12 Answers 12
- Linux and Unix join command tutorial with examples
- What is the join command in UNIX? ¶
- How to join two files ¶
- How to join two files on different fields ¶
- How to sort before joining ¶
- How to specify a field separator for joining ¶
- How to specify the output format ¶
- Further reading ¶
- Tags
- See Also
- Объединение файлов командой cat
Concatenating multiple text files into a single file in Bash
What is the quickest and most pragmatic way to combine all *.txt file in a directory into one large text file? Currently I’m using windows with cygwin so I have access to BASH. Windows shell command would be nice too but I doubt there is one.
12 Answers 12
This appends the output to all.txt
you may run into a problem where it cats all.txt into all.txt. I have this problem with grep sometimes, not sure if cat has the same behavior.
@rmeador yes, that is true, if all.txt already exists you will have this problem. This problem is solved by providing the output file with a different extension, or moving all.txt to a different folder.
Just remember, for all the solutions given so far, the shell decides the order in which the files are concatenated. For Bash, IIRC, that’s alphabetical order. If the order is important, you should either name the files appropriately (01file.txt, 02file.txt, etc. ) or specify each file in the order you want it concatenated.
$ cat file1 file2 file3 file4 file5 file6 > out.txt The Windows shell command type can do this:
Type type command also writes file names to stderr, which are not captured by the > redirect operator (but will show up on the console).
Just be aware that if you put the output file in the same directory as the original file it will cause a duplication because it will also combine the new output file twice.
You can use Windows shell copy to concatenate files.
To append files, specify a single file for destination, but multiple files for source (using wildcards or file1+file2+file3 format).
This as the IMHO cleanest solution with basically no side effects that beginners could trip over unfortunately does not get appreciated enough 🙁
Worked pretty well, except at the very end of my file I got a weird SUB special unicode character. Deleting it is pretty easy programmatically but not sure why that happened.
Be careful, because none of these methods work with a large number of files. Personally, I used this line:
for i in $(ls | grep ".txt");do cat $i >> output.txt;done EDIT: As someone said in the comments, you can replace $(ls | grep «.txt») with $(ls *.txt)
EDIT: thanks to @gnourf_gnourf expertise, the use of glob is the correct way to iterate over files in a directory. Consequently, blasphemous expressions like $(ls | grep «.txt») must be replaced by *.txt (see the article here).
Good Solution
for i in *.txt;do cat $i >> output.txt;done Mandatory ParsingLs link, together with a downvote (and you deserve more than one downvote, because ls | grep is a seriously bad antipattern).
Got an upvote from me because it allows for arbitrary testing/ operations by file name prior to output and it’s quick and easy and good for practice. (In my case I wanted: for i in *; do echo -e «\n$i:\n»; cat $1; done )
find . -type f -name '*.txt' -exec cat <> + >> output.txt Since OP says the files are in the same directory, you may need to add -maxdepth 1 to the find command.
This should be the correct answer. It will work properly in a shell script. Here is a similar method if you want output sorted: sort -u —output=»$OUTPUT_FILE» —files0-from=- < <(find "$DIRECTORY_NAME" -maxdepth 1 -type f -name '*.txt' -print0)
This is a very flexible approach relying on all the strengths of the find . My favourite! Surely cat *.txt > all.txt does the job within the same directory (as pointed out above). To me, however, becoming comfortably fluent in using find has been a very good habit. Today they’re all in one folder, tomorrow they have multiple file-endings across nested directory hierarchies. Don’t overcomplicate, but also, do make friends with find . 🙂
Linux and Unix join command tutorial with examples
Tutorial on using join, a UNIX and Linux command to join lines of two files on a common field. Examples of joining two files, sorting before joining, specifying a field separator and specifying the output format.

- August 10, 2016
- Updated May 24, 2023
What is the join command in UNIX? ¶
The join command in UNIX is a command line utility for joining lines of two files on a common field. It can be used to join two files by selecting fields within the line and joining the files on them. The result is written to standard output.
How to join two files ¶
To join two files using the join command files must have identical join fields. The default join field is the first field delimited by blanks. For the following example there are two files foodtypes.txt and foods.txt .
cat foodtypes.txt 1 Protein 2 Carbohydrate 3 Fat cat foods.txt 1 Cheese 2 Potato 3 Butter These files share a join field as the first field and can be joined.
join foodtypes foods.txt 1 Protein Cheese 2 Carbohydrate Potato 3 Fat Butter How to join two files on different fields ¶
To join files using different fields the -1 and -2 options can be passed to join . In the following example there are two files wine.txt and reviews.txt .
cat wine.txt Red Beaunes France White Reisling Germany Red Riocha Spain cat reviews.txt Beaunes Great! Reisling Terrible! Riocha Meh These files can be joined by specifying the fields that should be used to join the files. Common to both files is the name of the wine. In wine.txt this is the second field. In reviews.txt this is the first field. The files can be joined using -1 and -2 by specifying these fields.
join -1 2 -2 1 wine.txt reviews.txt Beaunes Red France Great! Reisling White Germany Terrible! Riocha Red Spain Meh How to sort before joining ¶
Join expects that files will be sorted before joining. For this example suppose there are two files from the previous example are not sorted.
cat wine.txt White Reisling Germany Red Riocha Spain Red Beaunes France cat reviews.txt Riocha Meh Beaunes Great! Reisling Terrible! Running join on these files results in an error becuase the files are not sorted.
join -1 2 -2 1 wine.txt reviews.txt join: wine.txt:3: is not sorted: Red Beaunes France join: reviews.txt:2: is not sorted: Beaunes Great! Riocha Red Spain Meh Beaunes Red France Great! The sort command can sort the files before passing to join.
join -1 2 -2 1 (sort -k 2 wine.txt) (sort reviews.txt) Beaunes Red France Great! Reisling White Germany Terrible! Riocha Red Spain Meh How to specify a field separator for joining ¶
To specify a field separator for joining using the join command use the -t option. An example is a CSV file where the separator is , . In the following example there are two files names.csv and deposits.csv .
cat names.csv 1,John Smith,London 2,Arthur Dent, Newcastle 3,Sophie Smith,London cat transactions.csv £1234,Deposit,John Smith £4534,Withdrawal,Arthur Dent £4675,Deposit,Sophie Smith Using the -t option the comma can set as the delimiter.
join -1 2 -2 3 -t , names.csv transactions.csv John Smith,1,London,£1234,Deposit Arthur Dent,2, Newcastle,£4534,Withdrawal Sophie Smith,3,London,£4675,Deposit How to specify the output format ¶
To specify the output format of join use the -o option. This allows the order of fields that will be shown in the output to be defined, or for only certain fields to be shown.
In the previous example the output was as follows.
John Smith,1,London,£1234,Deposit To specify the order the list of fields are passed to -o . For this example this is -o 1.1,1.2,1.3,2.2,2.1 . This formats the output in the order desired.
join -1 2 -2 3 -t , -o 1.1,1.2,1.3,2.2,2.1 names.csv transactions.csv 1,John Smith,London,Deposit,£1234 2,Arthur Dent, Newcastle,Withdrawal,£4534 3,Sophie Smith,London,Deposit,£4675 Further reading ¶
Tags
Can you help make this article better? You can edit it here and send me a pull request.
See Also
- Linux and Unix comm command tutorial with examples
Aug 10, 2016
Tutorial on using comm, a UNIX and Linux command for comparing two sorted files line by line. Examples of showing specific comparisons and ignoring case sensitivity. - Linux and Unix shuf command tutorial with examples
Aug 9, 2016
Tutorial on using shuf, a UNIX and Linux command for generating random permutations. Examples of shuffling the lines in a file, picking a random line and shuffling standard input. - Linux and Unix fold command tutorial with examples
Aug 8, 2016
Tutorial on using fold, a UNIX and Linux command for folding long lines for finite widths. Examples of limiting column width, limiting by bytes and wrapping on spaces.
Объединение файлов командой cat
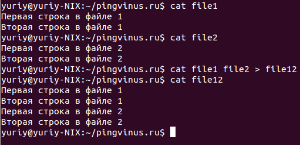
Команду cat в большинстве случаев используют только для просмотра файлов. На самом деле одно из ее предназначений это конкатенация (объединение) файлов. А название команды происходит от слова catenate (сцепить), то есть присоединение одного после другого.
Под объединением файлов понимается их соединение. Например, если мы имеем два текстовых файла и в одном из них записана строка:
My text file 1
А в другом:
My text file 2
То после объединения мы получим файл с двумя строками:
My text file 1
My text file 2
То есть происходит простое соединение файлов. К содержимому одного добавляется содержимое другого. Это касается не только текстовых файлов, но и всех остальных (бинарных, например).
Чтобы объединить два файла командой cat нужно просто указать в качестве аргументов названия этих файлов и направить результат выполнения в новый файл. Например, мы хотим объединить два файла file1 и file2, а результат записать в новый файл file12. Тогда мы должны выполнить следующую команду:
Вы можете объединить неограниченное количество файлов. Например, чтобы объединить четыре файла и записать результат в файл myfile, выполните команду:
cat file1 file2 file3 file4 > myfile