- Как работает метрика Load Average в Linux
- Основы Load Average в Linux
- Метрика Load Average в Linux
- Проверка Load Average в Linux
- 1: Команда uptime
- 2: Команда top
- 3: Утилита glances
- Подводим итоги
- Sysadminium
- Утилита top
- Общая информация о системе
- Информация по каждому процессу
- Опции команды top
- Количество итераций
- Процессы определённого пользователя
- Горячие клавиши top
- Режим цветности
- Больше информации о команде (поле COMMAND)
- Сортировка процессов
- Завершение процессов
- Добавление полей
- Итог
Как работает метрика Load Average в Linux
Load Average (cредняя нагрузка) — это метрика, которую используют пользователи Linux для отслеживания системных ресурсов. Она также помогает мониторить, как задействованы ресурсы системы.
Load Average является одной из самых основных метрик использования ресурсов, но она не принесет никакой пользы, если вы не понимаете, о чем она говорит. В этом мануале мы рассмотрим, что такое Load Average в Linux и как ее читать. Кроме того, мы обсудим несколько простых методов для мониторинга Load Average вашей системы.
Основы Load Average в Linux
Чтобы понять, что такое Load Average, нам нужно знать, что именно мы определяем как нагрузку. В системе Linux это показатель загруженности CPU в любой момент времени.
Она показывает количество процессов, которые выполняются или ожидают выполнения процессором в данный момент.
В состоянии бездействия нагрузка системы равна 0. Она увеличивается на 1 с каждым процессом, который выполняется или находится в списке ожидания.
Сама по себе нагрузка не дает пользователю никакой полезной информации. Она может измениться за доли секунды. Это происходит потому, что количество процессов, использующих процессорное время или находящихся в списке ожидания, не остается постоянным. Вот почему мы используем Load Average для мониторинга использования ресурсов.
Метрика Load Average в Linux
Как следует из названия, Load Average отображает среднюю нагрузку на CPU за определенный период времени. Эти значения представляют собой количество процессов, ожидающих выполнения на CPU или использующих его в данный период.
Большинство пользователей знакомы с процентами нагрузки в Windows, но в Linux Load Average представляется тремя десятичными значениями.

Посмотрите на скриншот выше, где показаны значения “load average: 0.03, 0.03, 0.01”.
Рассмотрим эти значения по порядку:
- Первое показывает среднюю нагрузку на CPU за последнюю минуту
- Второе дает нам среднюю нагрузку за последний 5-минутный интервал
- Третье значение показывает среднюю загрузку за последние 15 минут
Это помогает пользователю понять, как процессы в системе нагружают CPU с течением времени.
Значение 1 может означать примерно 100% использования ресурсов в однопроцессорной системе, но такие системы сегодня практически не встречаются. Если за последние 10 лет вы хотя бы раз обновляли свою систему, она должна работать на многоядерном процессоре.
Для двухъядерного процессора значение 1 означает, что одно ядро свободно на 100 %. То есть это примерно 50% использования CPU. Соответственно, для четырехъядерного процессора это 25% использования.
Load Average в Linux учитывает ожидающие и выполняемые процессы. Кроме того, это среднее значение, а не текущее.
Для приблизительного представления об использовании ресурсов можно разделить значение Load Average на количество ядер вашего процессора. Это не точное значение загрузки CPU, но это может быть полезно для мониторинга ресурсов.
Проверка Load Average в Linux
Теперь мы рассмотрим несколько способов проверки значения Load Average. Её можно посмотреть тремя способами.
1: Команда uptime
uptime — один из наиболее распространенных методов проверки Load Average в системе. Чтобы выполнить команду uptime, просто откройте терминал и введите следующее:
На скриншоте выше показано, что вы увидете при выполнении команды uptime. Здесь отображается время работы системы, количество активных пользователей и Load Average.
Как видите, Load Average за последнюю минуту равна 0.03. Значения за последние 5 и 15 минут составляют 0.03 и 0.01 соответственно .
2: Команда top
Ещё один способ мониторинга Load Average — выполнить команду top. Для этого откройте терминал и введите следующую команду:
Команда откроет интерфейс top в терминале. В отличие от uptime, эта команда выводит подробное описание об использовании ресурсов вашей системы.
На следующем скриншоте показано, что вы увидите при выполнении команды top.
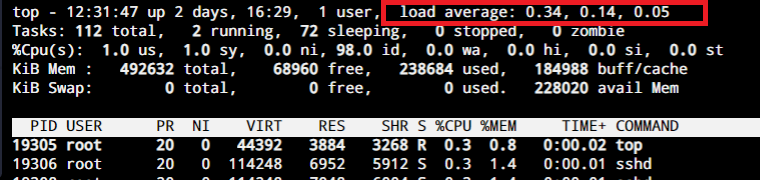
Как видно из самой верхней строки, Load Average за последнюю минуту составляет 0.34. За последние 5 минут и 15 минут значения равны 0.14 и 0.05 соответственно.
3: Утилита glances
glances — это утилита мониторинга системы, которая работает аналогично команде top. Она дает подробный обзор использования системных ресурсов. Чтобы использовать утилиту glances, необходимо установить её пакет с помощью этой команды:
sudo apt-get install glances
После завершения установки введите в терминале следующее:
Команда откроет интерфейс glances в терминале. В отличие от команды top, здесь отображается количество доступных процессорных ядер, а также Load Average системы.
На следующем скриншоте показано, что вы увидите, при выполнении команды glances.
Как видно из выделенной области, Load Average за последнюю минуту равна 0.14. За последние 5 минут и 15 минут значения равны 0.12 и 0.05 соответственно.
Подводим итоги
Load Average в Linux — это важная метрика, позволяющая легко мониторить использование системных ресурсов. Контроль Load Average гарантирует, что ваша система не столкнется со сбоями или медленными сессиями.
Sysadminium
В этой статье будет показана утилита top, с помощью которой можно наблюдать за активностью процессов в реальном времени.
Утилита top
Утилита top — это консольный диспетчер задач. Он показывает общую информацию о системе и информацию о каждом процессе. Работа этой утилиты выглядит следующим образом:
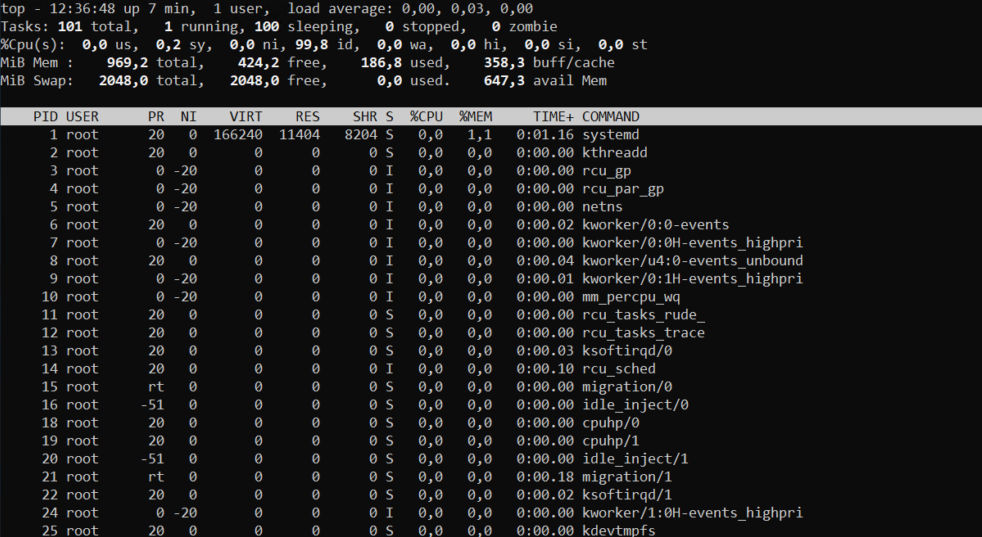
Вы можете почитать официальный мануал по использованию top здесь, или выполните команду man top .
Это не привычная нам утилита командной строки. Это — интерактивная утилита, то есть она постоянно обновляет данные и с ней можно взаимодействовать с помощью горячих клавиш.
Вывод данной утилиты можно разбить на две части:
- сверху — шапка. Здесь вы можете посмотреть на общую информацию о системе;
- ниже — информация по каждому процессу.
Общая информация о системе
Как видно, шапка состоит из пяти строк.
На первой и второй строке показана общая информация о системе:
![]()
На первой строке показаны следующие поля:
- текущее время;
- как долго работает система после последней загрузки;
- сколько в системе активных пользователей;
- средняя загрузка системы (load average) — три величины, усредненные за последние 1 и 5 и 15 минут. Чем ниже, тем лучше. Если превышает количество ядер на сервере, то значит сервер перегружен.
- количество процессов;
- количество работающих в данный момент процессов;
- количество спящих процессов;
- количество остановленных процессов;
- количество зомби процессов.
На третьей строке показана информация о потреблении ЦПУ:
![]()
- us — потребление cpu пользовательскими процессами (top и apache2);
- sy — потребление cpu системными процессами;
- ni — потребление cpu пользовательскими процессами, c измененным приоритетом (командой nice или renice);
- id — простаивание cpu;
- wa — процент времени, в течение которого процессор простаивал, ожидая завершения операции ввода-вывода. Если слишком высокое (более 10), значит за вашим процессором не поспевает диск, и нужно бы поменять его на более быстрый;
- hi — процент времени работы аппаратных прерываний. Периферийные устройства могут прерывать работу процессора, чтобы передать какие-то данные;
- si – процент времени работы программных прерываний. Некоторые приложения могут прерывать работу процессора, чтобы передать какие-то данные;
- st — процент времени, когда реальный процессор не был доступен виртуальной машине. Будет расти если виртуальной машине выделить больше ядер, чем имеет гипервизор. Этот показатель имеет значение только в системах виртуализации.
Ниже видим информацию по потреблению оперативной памяти (Mem) и подкачки (Swap):
![]()
- total — общее количество памяти;
- free — количество свободной памяти;
- used — количество используемой памяти;
- buff / cache — память выделенная под буфер и дисковый кэш;
- avail Mem — память которая может быть выделена для запуска новых процессов.
Информация по каждому процессу
Ниже показана информация по каждому процессу. Информация разбита на следующие колонки:

- PID — номер процесса;
- USER — имя пользователя под которым работает процесс;
- PR — приоритет процесса;
- NI — любезность процесса, чем она выше, тем ниже приоритет;
- VIR — общее количество памяти, которое способен адресовать процесс в данный момент времени. Включает в себя RES, SHR, прикреплённые файлы (например — файлы библиотек). Также включает в себя память, которая была выделена, но не использована;
- RES — количество физической памяти, которую использует процесс;
- SHR — количество разделяемой памяти, которую использует процесс. Разделяемая память потенциально может быть разделена с другими процессами;
- S — состояние процесса (я их уже описывал здесь):
- S (sleeping) — спящий;
- R (running) — в работе;
- Z (zombie) — зомби;
- D (uninterruptible sleep) — ожидает дискового ввода/вывода, и не принимает никакие сигналы;
- T (stopped by job control signal) — остановлен специальным сигналом;
- t (stopped by debugger during trace) — остановлен в процессе дебага;
- I (Idle) — бездействующий поток ядра.
- %CPU — использование cpu в процентах;
- %MEM — RES в процентах от общего количества памяти;
- TIME+ — сколько времени с этим процессом работал ЦПУ, с точностью до сотых долей секунды;
- COMMAND — с помощью какой команды запустили процесс.
Опции команды top
Теперь пробежимся по основным опциям, с которыми можно запускать top.
Количество итераций
Опция -n укажет через сколько повторений нужно завершить работу top. По умолчанию чтобы выйти из top нужно нажать клавишу q. Следующая команда выйдет из top через 10 повторений:
Процессы определённого пользователя
Можно заставить top отображать процессы определенного пользователя с помощью опции -u:

Горячие клавиши top
Режим цветности
Если во время работы top нажать клавишу z, это переключит режим цветности (белое на чёрном или черное на белом):

Больше информации о команде (поле COMMAND)
Если во время работы top нажать клавишу с, это заставит выводить больше информации о команде:

Сортировка процессов
По умолчанию процессы отсортированы по колонке %CPU. Те что потребляют больше всего находятся сверху.
Чтобы выделить столбец, по которому сейчас идет сортировка, нажмите клавишу x.
Клавишами «» или «>«, можно выбрать столбец, по которому нужно сортировать процессы.
А если нажать клавишу R, то сортировка пойдет в обратном порядке.
Клавиша M отсортирует процессы по потреблению памяти (%MEM).
Завершение процессов
Из top можно завершить процесс, для этого нужно нажать клавишу k, далее ввести pid процесса, который хотим завершить и нажать Enter.
По умолчанию процессу посылается сигнал 15 (sigterm). Но завершать чужие процессы можно только запустив top под пользователем root, или с помощью команды sudo.
Сигналы, которые можно посылать процессам, я разберу чуть позже в этом курсе.
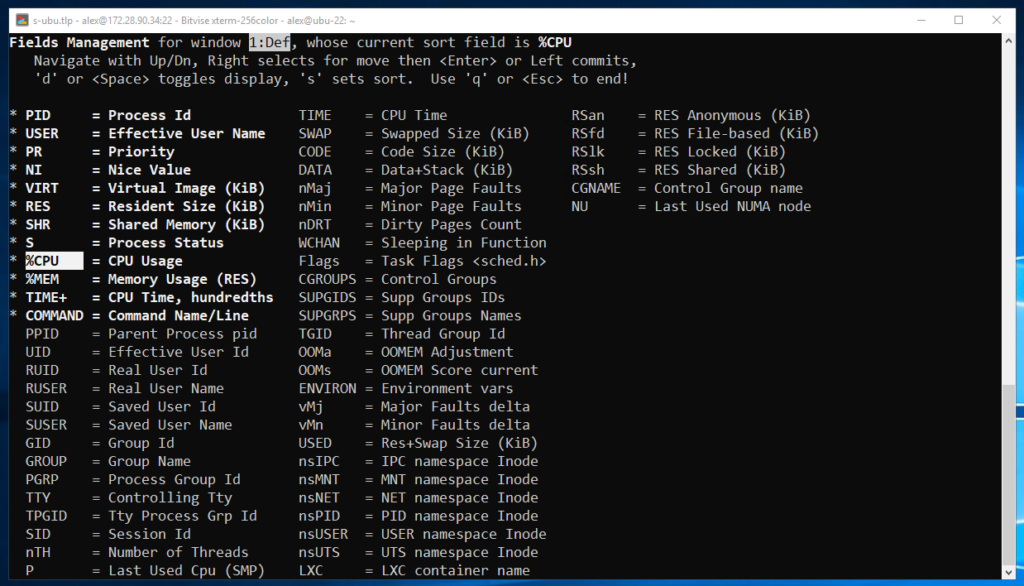
Добавление полей
По умолчанию отображаются далеко не все поля. Чтобы добавить поля нажмите клавишу F. Затем, с помощью клавиш вверх и вниз, вы можете перемещаться по полям. Чтобы добавить выбранное поле нажмите клавишу d или пробел. А чтобы выбрать поле для сортировки выделите его и нажмите s. Ну и чтобы вернуться в режим просмотра, нажмите q.
Итог
Мы разобрали утилиту top для мониторинга за потреблением ресурсов Linux.
Узнали следующие опции top:
- -n — завершить top после нескольких итераций;
- -u — показывать процессы определенного пользователя.
Узнали горячие клавиши top:
- z — изменить цветность;
- c — более полная команда запуска;
- — сортировать по предыдущему столбцу;
- > — сортировать по следующему столбцу;
- R — обратить сортировку;
- M — сортировать по rss;
- x — выделить колонку по которой ведётся сортировка;
- k — завершить процесс;
- F — настроить поля и сортировку.