- What is /dev/sda in Linux File System?
- Understanding Linux Files
- What is /dev in Linux
- What is /dev/sda in Linux
- Understanding /dev and its subdirs and files
- What does «all devices are files» mean?
- 2 Answers 2
- Related
- Hot Network Questions
- Subscribe to RSS
- What is a Superblock, Inode, Dentry and a File?
- 5 Answers 5
What is /dev/sda in Linux File System?
If you are transitioning from other operating system environments to Linux, the first puzzle you are most likely to face is understanding the Linux file system. To be more specific, you have to understand how Linux labels its hard disk drives (whether internal or external).
On a Windows operating system, this step is straightforward as all the disk drives connected to the operating system environment are identified by relatable labels like C: , D: , F: etc. In most cases, it is the disk drive labeled C: that hosts the installed copy of the Windows operating system.
Understanding Linux Files
A Linux operating system perceives each and every device-based connection linked to its OS environment as a file. Therefore, Directory Files, Ordinary Files, and Device Files are all categorized as file types.
- General/Ordinary Files – These are the document files that primarily contain data.
- Directory Files – These are files that contain both Ordinary files and Directories which are defined to host some Ordinary files if need be.
- Device Files – These files are a representation of hardware devices as device files on the system.
What is /dev in Linux
Before we get to /dev/sda ; which is the primary objective of this article, we must go through /dev . We have already stated that the Linux operating system perceives hardware devices connected to it as device files.
The hierarchy of the Linux operating system begins from the root file (/) .

It is the starting point of understanding the Linux operating system architecture. From the above screen capture, we have listed the content under this root (/) file directory. From this view and based on this article guide’s objective, we are more interested in what the directory dev has to offer.
/dev can be fully translated as root device since we are moving from the root (/) directory to this directory file within it. Viewing the content of this dev directory should reveal/list device files that translate to hardware components connected to our computer.
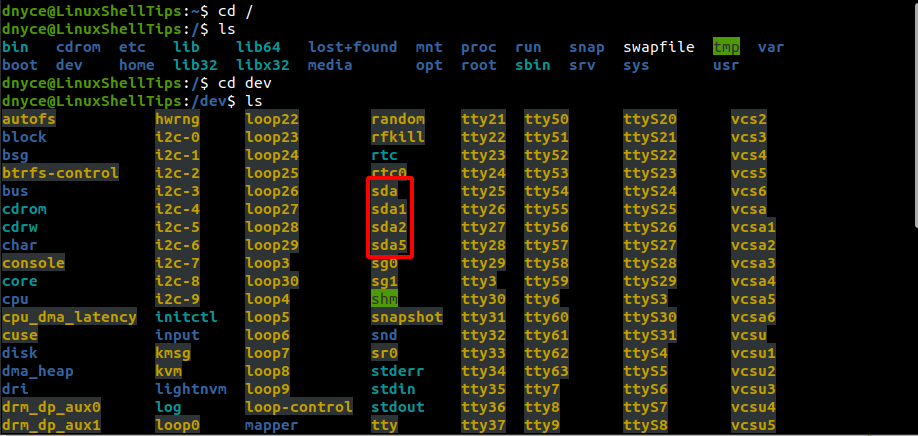
As you can see, there is more than enough information to chew inside this directory listing. We are however more interested in what the highlighted sda device file has to offer.
What is /dev/sda in Linux
From /dev/sda , the sd portion of sda can be translated to SCSI (Small Computer System Interface) disk.
Therefore, sda in full can be translated as the first SCSI hard disk. Under the /dev directory; from the screenshot above, we can note the device files sda, sda1, sda2, and sda5. The device files sda1, sda2, and sda5 exist as partitions of the first SCSI hard disk sda.
We can now fully refer to this device file as the root device’s first SCSI hard disk. To view some basic information about this device file, we can run the following fdisk command as a sudoer/root user.
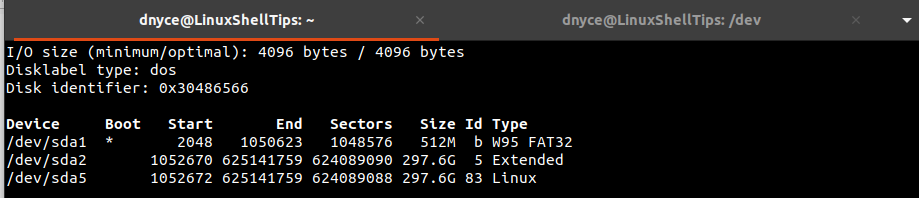
On my end, /dev/sda is partitioned into three device files. /dev/sda1 is the boot partition that makes the Linux OS easily restart, /dev/sda2 is the extended partition primarily used for user files storage, and /dev/sda5 is the Linux partition where your Linux OS installed files reside.
The concept of /dev/sda is now at our fingertips.
Understanding /dev and its subdirs and files
Almost all the files under /dev are device files. Whereas reading and writing to a regular file stores data on a disk or other filesystem, accessing a device file communicates with a driver in the kernel, which generally in turn communicates with a piece of hardware (a hardware device, hence the name).
There are two types of device files: block devices (indicated by b as the first character in the output of ls -l ), and character devices (indicated by c ). The distinction between block and character devices is not completely universal. Block devices are things like disks, which behave like large, fixed-size files: if you write a byte at a certain offset, and later read from the device at that offset, you get that byte back. Character devices are just about anything else, where writing a byte has some immediate effect (e.g. it’s emitted on a serial line) and reading a byte also has some immediate effect (e.g. it’s read from the serial port).
The meaning of a device file is determined by its number, not by its name (the name matters to applications, but not to the kernel). The number is actually two numbers: the major number indicates which driver is responsible for this device, and the minor number allows a driver to drive several devices¹. These numbers appear in the ls -l listing, where you would normally find the file size. E.g. brw-rw—- 1 root disk 8, 0 Jul 12 15:54 /dev/sda → this device is major 8, minor 0.
Some device files under /dev don’t correspond to hardware devices. One that exists on every unix system is /dev/null ; writing to it has no effect, and reading from it never returns any data. It’s often convenient in shell scripts, when you want to ignore the output from a command ( >/dev/null ) or run a command with no input ( ad infinitum) /dev/urandom (which returns random bytes ad infinitum).
A few device files have a meaning that depends on the process that accesses it. For example, /dev/stdin designates the standard input of the current process; opening from has approximately the same effect as opening the original file that was opened as the process’s standard input. Somewhat similarly, /dev/tty designates the terminal to which the process is connected. Under Linux, nowadays, /dev/stdin and friends are not implemented as character devices, but instead as symbolic links to a more general mechanism that allows every file descriptor to be referenced (as opposed to only 0, 1 and 2 under the traditional method); for example /dev/stdin is a symbolic link to /proc/self/fd/0 . See How does /dev/fd relate to /proc/self/fd/?.
You’ll find a number of symbolic links under /dev . This can occur for historical reasons: a device file was moved from one name to another, but some applications still use the old name. For example, /dev/scd0 is a symbolic link to /dev/sr0 under Linux; both designate the first CD device. Another reason for symbolic links is organization: under Linux, you’ll find your hard disks and partitions in several places: /dev/sda and /dev/sda1 and friends (each disk designated by an arbitrary letter, and partitions according to the partition layout), /dev/disk/by-id/* (disks designated by a unique serial number), /dev/disk/by-label/* (partitions with a filesystem, designated by a human-chosen label); and more. Symbolic links are also used when a generic device name could be one of several; for example /dev/dvd might be a symbolic link to /dev/sr0 , or it might be a link to /dev/sr1 if you have two CD readers and the second one is to be the default DVD reader.
Finally, there are a few other files that you might find under /dev , for traditional reasons. You won’t find the same on every system. On most unices, /dev/log is a socket that programs use to emit log messages. /dev/MAKEDEV is a script that creates entries in /dev . On modern Linux systems, entries in /dev/ are created automatically by udev, obsoleting MAKEDEV .
¹ This is actually no longer true under Linux, but this detail only matters to device driver writers.
What does «all devices are files» mean?
I heard someone say that in Linux «all devices are files.» What does that mean? My understanding of a file is that it is a logical location on disk to which bytes are written and from which bytes are read. A device to my knowledge is just any physical piece of hardware. somewhat unrelated to files. Can someone explain this statement to me?
2 Answers 2
Linux treats every device as if it were a file. That is, you interact with a device programmatically in exactly the same way you’d interact with a file:
- You specify the device via a path, usually under the /dev directory.
- You begin by «opening» the device, just as you’d open a file, which gives you a file descriptor.
- You can perform ioctl (input/output control) operations on the file descriptor.
- You can send and/or retrieve data by writing and/or reading the file descriptor.
- You «close» the device when you’re finished using it.
It means that the actual details of a device are abstracted away, such that an application can treat it as a file for IO purposes.
E.g. a serial port may be implemented in hardware in many different ways, but the operating system hides that so that an application can read and write to and from the device exactly as if it were reading and writing a file.
Related
Hot Network Questions
Subscribe to RSS
To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
Site design / logo © 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA . rev 2023.7.13.43531
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
What is a Superblock, Inode, Dentry and a File?
From the article Anatomy of the Linux file system by M. Tim Jones, I read that Linux views all the file systems from the perspective of a common set of objects and these objects are superblock, inode, dentry and file. Even though the rest of the paragraph explains the above, I was not that comfortable with that explanation. Could somebody explain to me these terms?
5 Answers 5
First and foremost, and I realize that it was not one of the terms from your question, you must understand metadata. Succinctly, and stolen from Wikipedia, metadata is data about data. That is to say that metadata contains information about a piece of data. For example, if I own a car then I have a set of information about the car but which is not part of the car itself. Information such as the registration number, make, model, year of manufacture, insurance information, and so on. All of that information is collectively referred to as the metadata. In Linux and UNIX file systems metadata exists at multiple levels of organization as you will see.
The superblock is essentially file system metadata and defines the file system type, size, status, and information about other metadata structures (metadata of metadata). The superblock is very critical to the file system and therefore is stored in multiple redundant copies for each file system. The superblock is a very «high level» metadata structure for the file system. For example, if the superblock of a partition, /var, becomes corrupt then the file system in question (/var) cannot be mounted by the operating system. Commonly in this event, you need to run fsck which will automatically select an alternate, backup copy of the superblock and attempt to recover the file system. The backup copies themselves are stored in block groups spread through the file system with the first stored at a 1 block offset from the start of the partition. This is important in the event that a manual recovery is necessary. You may view information about ext2/ext3/ext4 superblock backups with the command dumpe2fs /dev/foo | grep -i superblock which is useful in the event of a manual recovery attempt. Let us suppose that the dumpe2fs command outputs the line Backup superblock at 163840, Group descriptors at 163841-163841 . We can use this information, and additional knowledge about the file system structure, to attempt to use this superblock backup: /sbin/fsck.ext3 -b 163840 -B 1024 /dev/foo . Please note that I have assumed a block size of 1024 bytes for this example.
An inode exists in, or on, a file system and represents metadata about a file. For clarity, all objects in a Linux or UNIX system are files; actual files, directories, devices, and so on. Please note that, among the metadata contained in an inode, there is no file name as humans think of it, this will be important later. An inode contains essentially information about ownership (user, group), access mode (read, write, execute permissions), file type, and the data blocks with the file’s content.
A dentry is the glue that holds inodes and files together by relating inode numbers to file names. Dentries also play a role in directory caching which, ideally, keeps the most frequently used files on-hand for faster access. File system traversal is another aspect of the dentry as it maintains a relationship between directories and their files.
A file, in addition to being what humans typically think of when presented with the word, is really just a block of logically related arbitrary data. Comparatively very dull considering all of the work done (above) to keep track of them.
I fully realize that a few sentences do not provide a full explanation of any of these concepts so please feel free to ask for additional details when and where necessary.