Анализ логов Linux
https://t.me/i_odmin
В ваших журналах есть много информации, хотя это не всегда так просто сделать так, как вы хотели бы ее извлечь.
В этом разделе мы рассмотрим некоторые примеры базового анализа, который вы можете сделать с вашими журналами сразу (просто найти то, что там).
Мы также рассмотрим более продвинутый анализ, который может потребовать определенных усилий для правильной настройки, но сэкономит ваше время на заднем плане.
Примеры расширенного анализа, которые вы можете выполнить при анализе данных, включают в себя создание сводных счетчиков, фильтрацию значений полей и т. д.
Сначала мы покажем вам, как сделать это самостоятельно в командной строке, используя несколько различных инструментов, а затем я покажу вам, как инструмент управления журналом может автоматизировать большую часть монотонной работы и сделать это намного более упорядоченным.
Поиск с помощью Grep
Поиск текста – это самый простой способ найти то, что вы ищете.
Наиболее распространенным инструментом для поиска текста является grep.
Этот инструмент командной строки, доступный для большинства дистрибутивов Linux, позволяет выполнять поиск в журналах с помощью регулярных выражений.
Регулярное выражение представляет собой шаблон, написанный на специальном языке, который может идентифицировать соответствующий текст.
Самый простой шаблон – это ввести строку, которую вы ищете, окруженную кавычками
Регулярные выражения
Ниже приведен пример поиска журналов проверки подлинности для «user hoover» в системе Ubuntu:
$ grep “user hoover” /var/log/auth.log
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
pam_unix(sshd:session): session opened for user hoover by (uid=0)
pam_unix(sshd:session): session closed for user hoover
Трудно построить правильные выражения, которые должны быть точны.
Например, если бы мы искали такое число, как порт «4792», оно также могло бы соответствовать отметкам времени, URL-адресам и другим нежелательным данным.
В приведенном ниже примере для Ubuntu он соответствовал журналу Apache, который нам не нужен.
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
74.91.21.46 – – [31/Mar/2015:19:44:32 +0000] “GET /scripts/samples/search?q=4972HTTP/1.0” 404 545 “-“ “–”
Поиск окружения
Другим полезным советом является то, что вы можете выполнять поиск по окружению с помощью grep.
Он покажет вам, что произошло за несколько строк до или после.
Он может помочь вам отладить то, что приводит к определенной ошибке или проблеме.
Флаг B дает вам строки раньше, и A дает вам строки после.
Например, мы можем увидеть, когда кто-то не смог войти в систему как администратор, он также не выполнил обратное сопоставление, что означает, что у них может не быть допустимого имени домена. Это очень подозрительно!
$ grep –B 3 –A 2 ‘Invalid user’ /var/log/auth.log
Apr 28 17:06:20 ip–172–31–11–241 sshd[12545]: reverse mapping checking getaddrinfo for 216–19–2–8.commspeed.net [216.19.2.8] failed – POSSIBLE BREAK–IN ATTEMPT!
Apr 28 17:06:20 ip–172–31–11–241 sshd[12545]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
Apr 28 17:06:20 ip–172–31–11–241 sshd[12547]:Invalid useradmin from 216.19.2.8
Apr 28 17:06:20 ip–172–31–11–241 sshd[12547]: input_userauth_request: invalid user admin [preauth]
Apr 28 17:06:20 ip–172–31–11–241 sshd[12547]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
Tail
Вы также можете связать grep с tail, чтобы получить последние несколько строк файла, или следить за журналами и выводить их в режиме реального времени.
Это полезно, если вы делаете интерактивные изменения, такие как запуск сервера или тестирование изменения кода.
$ tail –f /var/log/auth.log | grep ‘Invalid user’
Apr 30 19:49:48 ip–172–31–11–241 sshd[6512]: Invalid user ubnt from 219.140.64.136
Apr 30 19:49:49 ip–172–31–11–241 sshd[6514]: Invalid user admin from 219.140.64.136
Полное введение в grep и регулярные выражения выходит за рамки настоящего руководства.
Системы управления журналом имеют более высокую производительность и более мощные возможности поиска.
Они часто индексируют свои данные и распараллеливают запросы, поэтому вы можете быстро искать гигабайты или терабайты журналов за считанные секунды.
Напротив, это займет минуты или в крайнем случае часы с grep.
Системы управления журналом также используют языки запросов, такие как Lucene, которые предлагают более простой синтаксис для поиска по номерам, полям и т. д.
Парсинг логов с Cut, AWK и Grok
Инструменты командной строки
Linux предлагает несколько инструментов командной строки для синтаксического анализа и анализа текста.
Они великолепны, если вы хотите быстро разобрать небольшой объем данных, но может потребоваться много времени для обработки больших объемов.
Cut
Команда cut позволяет вам анализировать поля из разделенных журналов.
Разделители являются символами, такими как знаками или запятыми, которые разбивают поля или пары ключевых значений.
Предположим, мы хотим проанализировать пользователя из этого журнала:
pam_unix(su:auth): authentication failure; logname=hoover uid=1000 euid=0 tty=/dev/pts/0 ruser=hoover rhost= user=root
Мы можем использовать команду cut так, чтобы получить текст после восьмого знака равенства.
Этот пример относится к системе Ubuntu:
$ grep “authentication failure” /var/log/auth.log | cut –d ‘=’ –f 8
AWK
В качестве альтернативы вы можете использовать awk, который предлагает более мощные функции для анализа полей.
Он предлагает язык скриптов, поэтому вы можете отфильтровывать почти все, что не имеет значения.
Например, допустим, у нас есть следующая строка журнала в системе Ubuntu, и мы хотим извлечь имя пользователя, которому не удалось войти в систему:
Mar 24 08:28:18 ip–172–31–11–241 sshd[32701]: input_userauth_request: invalid user guest [preauth]
Вот как вы можете использовать команду awk.
Сначала поставьте регулярное выражение /sshd.*invalid user /, чтобы совместить недопустимые строки пользователя sshd.
Затем выведете девятое поле, используя разделитель по умолчанию, используя .
Это выводит имена пользователей.
$ awk ‘/sshd.*invalid user/ < print $9 >’ /var/log/auth.log
Системы управления журналами
Системы управления журналами упрощают синтаксический анализ и позволяют пользователям быстро анализировать большие коллекции лог файлов.
Они могут автоматически анализировать стандартные форматы журналов, такие как обычные журналы Linux или журналы веб-сервера.
Это экономит много времени, потому что вам не нужно думать о написании собственной логики синтаксического анализа при устранении неполадок системы.
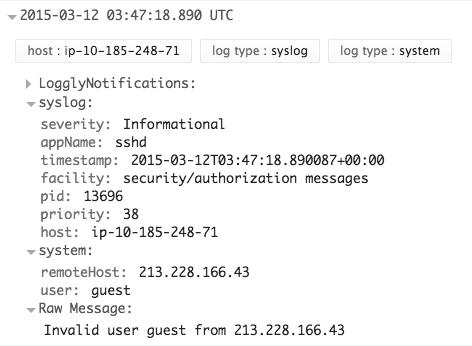
Здесь вы можете увидеть пример сообщения журнала из sshd, который парсит каждое из полей remoteHost и user.
Это скриншот от Loggly, облачной службы управления журналами.
Вы также можете выполнять индивидуальный синтаксический анализ для нестандартных форматов.
Общим инструментом для использования является Grok, который использует библиотеку обычных регулярных выражений для синтаксического анализа исходного текста в структурированный JSON.
Ниже приведен пример конфигурации Grok для анализа файлов журнала ядра внутри Logstash:
Фильтрация с помощью Rsyslog и AWK
Фильтрация позволяет выполнять поиск по определенному значению поля, а не выполнять полный текстовый поиск.
Это делает ваш анализ журнала более точным, потому что он будет игнорировать нежелательные совпадения с другими частями сообщений журнала.
Чтобы выполнить поиск по значению поля, сначала необходимо проанализировать свои журналы или, по крайней мере, найти способ поиска на основе структуры событий.
Как фильтровать одно приложение
Часто вы просто хотите увидеть журналы только из одного приложения.
Это легко, если ваше приложение всегда регистрируется в одном файле.
Это сложнее, если вам нужно отфильтровать одно приложение среди многих в агрегированном или централизованном журнале.
Вот несколько способов сделать это:
ИСПОЛЬЗУЙТЕ RSYSLOG DAEMON ДЛЯ ПАРАМЕТРОВ И ФИЛЬТРОВ.
:programname, isequal, “sshd” /var/log/sshd–messages
2. Используйте инструменты командной строки, такие как awk, для извлечения значений определенного поля, например, имени пользователя sshd. Этот пример из системы Ubuntu.
$ awk ‘/sshd.*invalid user/ < print $9 >’ /var/log/auth.log
3. Используйте систему управления журналом, которая автоматически анализирует ваши журналы и затем фильтрует нужное имя приложения.
Вот скриншот, показывающий поля syslog в службе управления журналами под названием Loggly.
Мы фильтруем на appName «sshd», как показано значком диаграммы Venn.
Как фильтровать по ошибкам
Одна из самых распространенных вещей, которые люди хотят видеть в своих журналах, – это ошибки.
К сожалению, конфигурация syslog по умолчанию не выводит серьезность ошибок напрямую, что затрудняет их фильтрацию.
Есть два способа решить эту проблему. Во-первых, вы можете изменить конфигурацию rsyslog для вывода серьезности в файле журнала, чтобы упростить чтение и поиск.
В вашей конфигурации rsyslog вы можете добавить шаблон с pri-текстом, например:
В этом примере вы получите результат в следующем формате. Вы можете видеть, что серьезность этого сообщения ошибочна.
<authpriv.err> : Mar 11 18:18:00,hoover–VirtualBox,su[5026]:, pam_authenticate: Authentication failure
Вы можете использовать awk или grep для поиска только сообщений об ошибках.
В этом примере для Ubuntu мы включаем некоторый окружающий синтаксис, например . и >, которые соответствуют только этому полю.
<AUTHPRIV.ERR> : MAR 11 18:18:00,HOOVER-VIRTUALBOX,SU[5026]:, PAM_AUTHENTICATE: AUTHENTICATION FAILURE