- How do I write a bash script to restart a process if it dies?
- 10 Answers 10
- Автоматический перезапуск сервиса Linux
- Автоматический перезапуск сервиса в systemd
- Автоматический перезапуск сервиса с помощью скрипта
- Использование простого Bash-скрипта для перезапуска программ на сервере
- Bash-скрипт
- Установка Cron
- Читайте также
- Как выполнить автоматический перезапуск сервиса Linux
- Автоматический перезапуск в Systemd
- Автоматический перезапуск скриптом
How do I write a bash script to restart a process if it dies?
How do I write a bash script that will check if it’s running, and if not, start it. Roughly the following pseudo code (or maybe it should do something like ps | grep ?):
# keepalivescript.sh if processidfile exists: if processid is running: exit, all ok run checkqueue.py write processid to processidfile # crontab */5 * * * * /path/to/keepalivescript.sh Just to add this for 2017. Use supervisord. crontab is not mean to do this kind of task. A bash script is terrible on emitting the real error. stackoverflow.com/questions/9301494/…
How about using inittab and respawn instead of other non-system solutions? See superuser.com/a/507835/116705
10 Answers 10
Avoid PID-files, crons, or anything else that tries to evaluate processes that aren’t their children.
There is a very good reason why in UNIX, you can ONLY wait on your children. Any method (ps parsing, pgrep, storing a PID, . ) that tries to work around that is flawed and has gaping holes in it. Just say no.
Instead you need the process that monitors your process to be the process’ parent. What does this mean? It means only the process that starts your process can reliably wait for it to end. In bash, this is absolutely trivial.
until myserver; do echo "Server 'myserver' crashed with exit code $?. Respawning.." >&2 sleep 1 done The above piece of bash code runs myserver in an until loop. The first line starts myserver and waits for it to end. When it ends, until checks its exit status. If the exit status is 0 , it means it ended gracefully (which means you asked it to shut down somehow, and it did so successfully). In that case we don’t want to restart it (we just asked it to shut down!). If the exit status is not 0 , until will run the loop body, which emits an error message on STDERR and restarts the loop (back to line 1) after 1 second.
Why do we wait a second? Because if something’s wrong with the startup sequence of myserver and it crashes immediately, you’ll have a very intensive loop of constant restarting and crashing on your hands. The sleep 1 takes away the strain from that.
Now all you need to do is start this bash script (asynchronously, probably), and it will monitor myserver and restart it as necessary. If you want to start the monitor on boot (making the server «survive» reboots), you can schedule it in your user’s cron(1) with an @reboot rule. Open your cron rules with crontab :
Then add a rule to start your monitor script:
@reboot /usr/local/bin/myservermonitor Alternatively; look at inittab(5) and /etc/inittab. You can add a line in there to have myserver start at a certain init level and be respawned automatically.
Let me add some information on why not to use PID files. While they are very popular; they are also very flawed and there’s no reason why you wouldn’t just do it the correct way.
- PID recycling (killing the wrong process):
- /etc/init.d/foo start : start foo , write foo ‘s PID to /var/run/foo.pid
- A while later: foo dies somehow.
- A while later: any random process that starts (call it bar ) takes a random PID, imagine it taking foo ‘s old PID.
- You notice foo ‘s gone: /etc/init.d/foo/restart reads /var/run/foo.pid , checks to see if it’s still alive, finds bar , thinks it’s foo , kills it, starts a new foo .
- PID files go stale. You need over-complicated (or should I say, non-trivial) logic to check whether the PID file is stale, and any such logic is again vulnerable to 1. .
- What if you don’t even have write access or are in a read-only environment?
- It’s pointless overcomplication; see how simple my example above is. No need to complicate that, at all.
By the way; even worse than PID files is parsing ps ! Don’t ever do this.
- ps is very unportable. While you find it on almost every UNIX system; its arguments vary greatly if you want non-standard output. And standard output is ONLY for human consumption, not for scripted parsing!
- Parsing ps leads to a LOT of false positives. Take the ps aux | grep PID example, and now imagine someone starting a process with a number somewhere as argument that happens to be the same as the PID you stared your daemon with! Imagine two people starting an X session and you grepping for X to kill yours. It’s just all kinds of bad.
If you don’t want to manage the process yourself; there are some perfectly good systems out there that will act as monitor for your processes. Look into runit, for example.
Автоматический перезапуск сервиса Linux
Иногда сервисы ни с того ни с сего падают и приходиться их вручную восстанавливать. Если для пользователя домашнего компьютера это не критично, потому что если сервис падает во время разработки, то это даже хорошо, можно сразу увидеть что есть проблема. Но на серверах и VPS сервисы должны работать постоянно для обеспечения доступа к веб-сайту или приложению.
В этой инструкции я покажу как настроить автоматический перезапуск сервиса Linux несколькими способами: с помощью скрипта мониторинга периодически запускаемого через cron и в systemd.
Автоматический перезапуск сервиса в systemd
По умолчанию, если ваш сервис будет убит или завершится некорректно, systemd не будет с ним ничего делать. Но можно настроить сервис так, чтобы при падении или даже остановке он автоматически перезапускался. Для этого используется директива Restart, которую надо добавить в секцию Service. Этот параметр может иметь такие значения:
- on-failure — только если произошла ошибка;
- on-success — только если процесс сервиса завершился без ошибок;
- on-abnormal — только если сервис не отвечает;
- always — перезапускать всегда, когда сервис был остановлен;
Например, рассмотрим настройку автоматического перезапуска сервиса Apache:
sudo systemctl edit apache2 [Service]
Restart=on-failure
RestartSec=5s
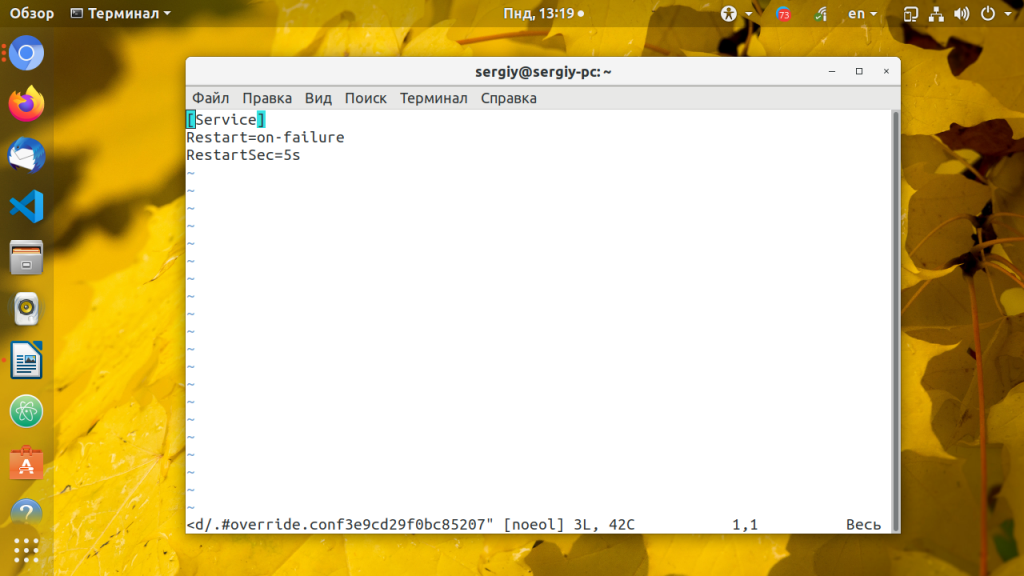
Директива RestartSec указывает сколько ждать перед перезапуском сервиса. Когда завершите сохраните изменения и выполните команду daemon-reload, чтобы перечитать конфигурацию:
sudo systemctl daemon-reload
Затем чтобы проверить что всё работает посмотрите состояние процесса, завершите процесс сигналом kill:
sudo systemctl status apache2 kill -KILL 32091
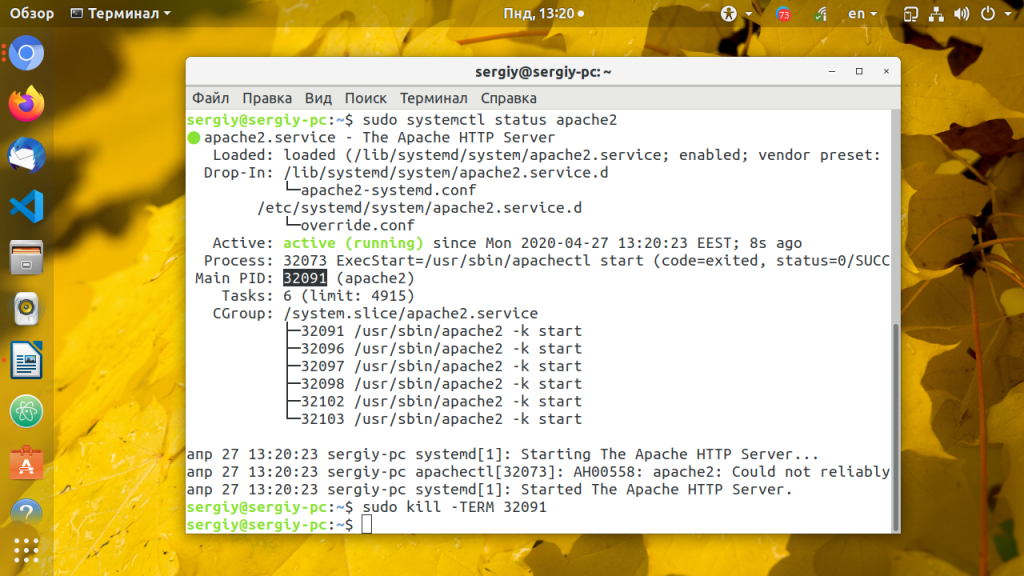
И снова посмотрите состояние. Процесс будет запущен. Система инициализации автоматически перезапустит его как только он завершится с кодом возврата ошибки. Если вы хотите чтобы процесс перезапускался всегда, необходимо использовать директиву Restart: always. Однако с ней надо быть осторожным, она вовсе не даст вам завершить процесс, даже если будет необходимо. Для того, чтобы процесс, который постоянно падает не перезапускался, можно добавить лимит на количество перезапусков в секцию Service:
sudo systemctl edit apache2 [Service]
StartLimitIntervalSec=500
StartLimitBurst=5
Restart=on-failure
RestartSec=5s
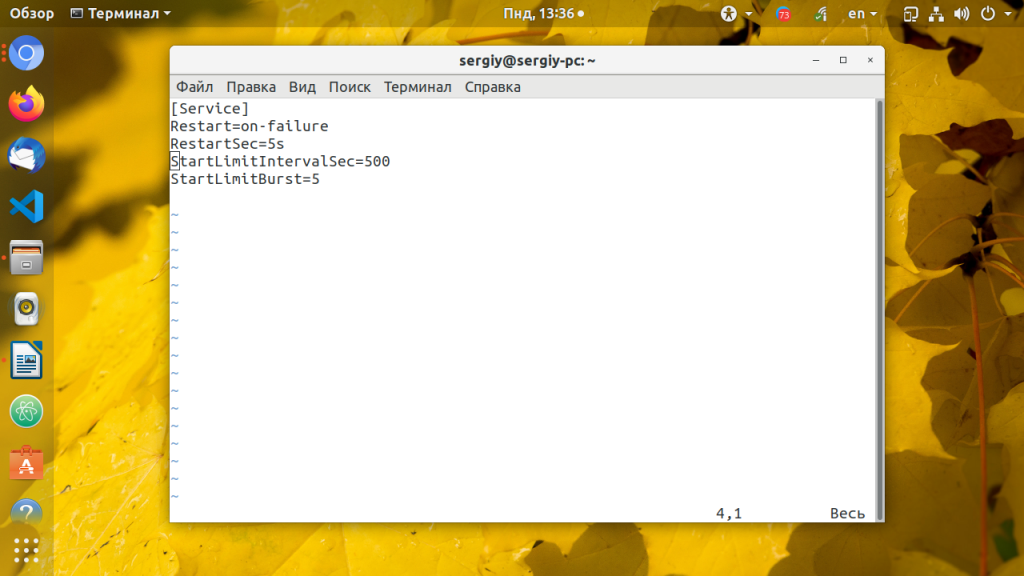
Директивы StartLimitBurst и StartLimitIntervalSec указывают, что надо попытаться перезапустить сервис пять раз, и если он все эти пять раз упадёт, то больше его не трогать. Вторая директива ограничивает время перезапусков сервиса до 500 секунд.
Автоматический перезапуск сервиса с помощью скрипта
Это самый простой и самый надежный способ работающий абсолютно во всех дистрибутивах Linux и не требующий установки дополнительных утилит. Для того же Apache скрипт выглядит следующим образом:
sudo vi /usr/local/bin/apache-monitor.sh #!/bin/bash
ps -A | grep apache2 || systemctl start apache2
Сохраните файл, сделайте его исполняемым:
chmod ugo+x /usr/local/bin/apache-monitor.sh
Теперь добавьте запись в cron для периодического запуска скрипта:
На этом все, автоматический перезапуск сервисов штука может и немного сложная, но необходимая в серьезных системах.
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.
Использование простого Bash-скрипта для перезапуска программ на сервере
Чтобы обеспечить как можно более долгое функционирование императивных программ (даже после сбоя или перезагрузки сервера), можно создать простой bash-скрипт, который будет проверять, работают ли программы, и запустит их в случае необходимости. Чтобы скрипт работал на регулярной основе, можно использовать cron для составления графика запуска скрипта, что гарантирует перезапуск программы в случае ее падения.
Bash-скрипт
Итак, первый шаг – создание самого скрипта. Существует целый ряд программ, таких как Upstart, Supervisor и Monit, которые могут запускать и мониторить приложения на виртуальных частных серверах; bash-скрипт выполняет только запуск программ. Ниже приведен пример сценария, который запускает Apache, в случае если приложение выключено.
nano launch.sh
#!/bin/sh
ps auxw | grep apache2 | grep -v grep > /dev/null
if [ $? != 0 ] then
/etc/init.d/apache2 start > /dev/null
fi
После сохранения скрипта нужно дать ему права на выполнение, чтобы иметь возможность запускать его.
Apache можно заменить любым необходимым приложением. При необходимости установить скрипт для нескольких приложений, нужно создать новый скрипт для каждого приложения и поместить скрипты в отдельную строку cron-файла.
Установка Cron
После создания скрипта нужно установить график его запуска. Утилита cron позволяет установить интервалы выполнения скрипта. Для начала откройте cron-файл:
Cron предоставляет подробную информацию работе системы расписаний в начале файла.
Определив необходимую частоту запуска скрипта, внесите ее в соответствующую строку. Самый короткий интервал запуска скрипта в cron – 1 минута. Чтобы установить данный интервал, используйте следующий шаблон:
Для запуска скрипта каждые 5 минут используйте шаблон:
Читайте также
Установка простого скрипта обеспечит запуск программы после ее падения по любой причине. Это дает гарантию того, что максимальное время, на протяжении которого программа будет отключена – это интервал времени, указанный в конфигурациях cron.
Если серверу нужна программа, работающая более тщательно, можно установить одну из нескольких программ мониторинга сервера (Supervisor, Upstart, or Monit)
Как выполнить автоматический перезапуск сервиса Linux
Часто происходит спонтанное падение сервиса. Пользователю приходится заниматься их ручным восстановлением. Проблемы как таковой нет, если это происходит на домашнем компьютере. Даже больше – это хорошо, ведь появляется реальная возможность определить состояние сервиса, выявить неисправности и устранить их. Но совсем другая ситуация, когда дело касается серверов и VPS сервисов, которые должны работать постоянно для обеспечения доступа к веб-сайту или приложению. В этой статье рассмотрим способ настройки автоматического перезапуска сервиса Linux несколькими способами: с помощью скрипта мониторинга периодически запускаемого через cron и в systemd.
Автоматический перезапуск в Systemd
По умолчанию выставлено, что в случае падения сервиса Systemd ничего с ним не будет делать. Но пользователь всегда может выстроить настройки таким образом, чтобы в случае падения или остановки сервис автоматически перезапускался. Для этого используется директива Restart, которую надо добавить в секцию Service. Дальше рассмотрим пример настройки автоматического перезапуска сервиса Apache:
$ sudo systemctl edit apache2
[Service]
Restart=on-failure
RestartSec=5s
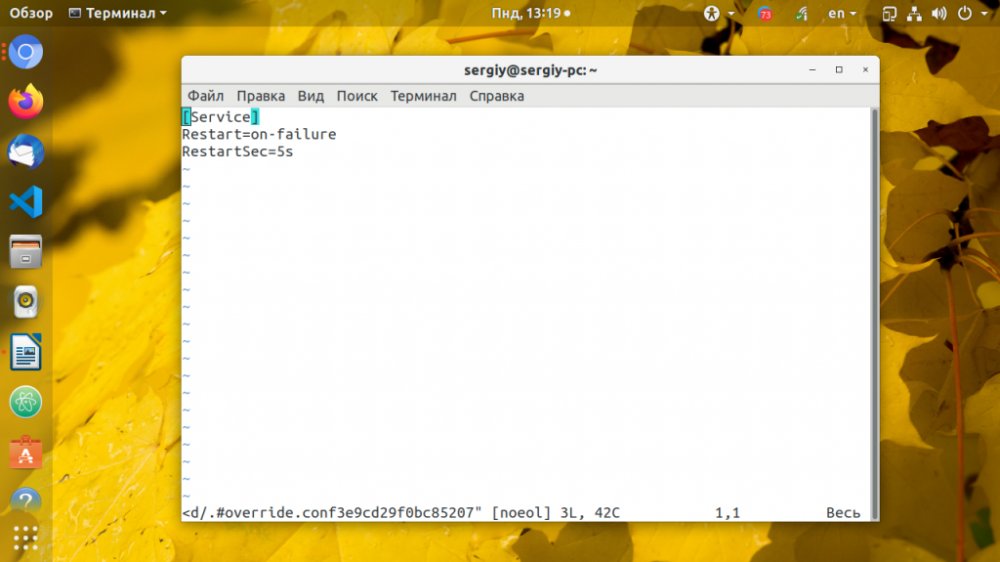
Здесь RestartSec указывает, сколько ждать перед перезапуском сервиса. Когда завершите работу, сохраните изменения и выполните команду daemon-reload, чтобы перечитать конфигурацию:
Дальше, чтобы проверить все ли работает исправно, посмотрите состояние процесса, завершите процесс сигналом kill:
$ sudo systemctl status apache2
$ kill -KILL 32091
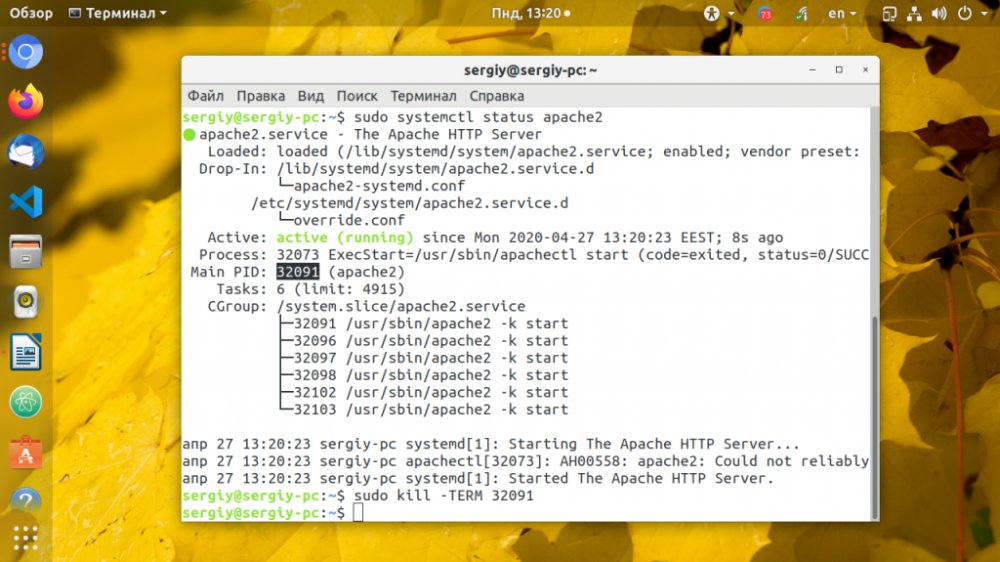
Еще раз посмотрите состояние, процесс должен быть запущен. Для установки запуска инициализации каждый раз, используйте специальную директиву Restart: always. Но пользоваться ею необходимо крайне осторожно, ведь она не позволит завершить процесс, даже если в этом возникнет необходимость. Если процесс постоянно падает, чтобы он перезапускался, можно добавить лимит на количество перезапусков в секцию Service:
$ sudo systemctl edit apache2
[Service]
StartLimitIntervalSec=500
StartLimitBurst=5
Restart=on-failure
RestartSec=5s
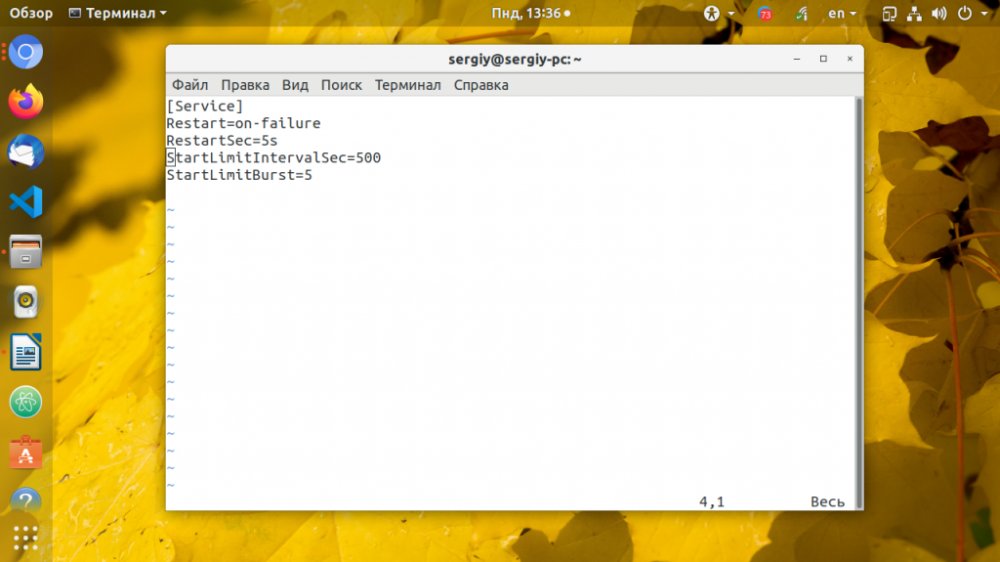
Здесь StartLimitBurst и StartLimitIntervalSec указывают на важность перезапуска сервиса пять раз, и если он все эти пять раз упадёт, то оставить его и не трогать. Вторая директива ограничивает время перезапусков сервиса до 500 секунд.
Автоматический перезапуск скриптом
Пожалуй, самый надежный и безотказный способ, работающий во всех версиях Linux. В том же Apache легко выстроить автоматический перезапуск при помощи скрипта. Для этого необходимо ввести команду:
$ sudo vi /usr/local/bin/apache-monitor.sh
#!/bin/bash
ps -A | grep apache2 || systemctl start apache2
Файл нужно сохранить и обязательно сделать его исполняемым:
chmod ugo+x /usr/local/bin/apache-monitor.sh
Не забудьте добавить запись в cron для периодического запуска скрипта:
$ sudo crontab -e
*/5 * * * * /usr/local/bin/apache-monitor.sh
На этом все. Да, настроить автоматический перезапуск сервиса не так просто, как может показаться на первый взгляд. Но это важная способность, поэтому ей необходимо уделить внимание – оно того определенно стоит.