- How to use ‘awk’ to print columns from a text file (in any order)
- awk column printing examples
- Using a field separator with awk
- Summary
- How to print a range of columns using the `awk` command
- Example 1: Print a range of columns from a command output
- Example 2: Print the range of columns from a file by using a for loop
- Example 3: Print the range of columns by defining starting and ending variables
- Example 4: Print a range of columns from a file with formatting
- Example 5: Print the range of columns from a file using a conditional statement
- Example 6: Print the range of columns from a file using the NF variable
- Example 7: Print the range of columns from a file using substr() and index()
- Example 8: Sequentially print a range of columns from a file using printf
- Conclusion
- About the author
- Fahmida Yesmin
- How to Use Awk to Print Fields and Columns in File
- Summary
- Printing column separated by comma using Awk command line
- 4 Answers 4
How to use ‘awk’ to print columns from a text file (in any order)
One of my favorite ways to use the Unix awk command is to print columns of information from text files, including printing columns in a different order than they are in in the text file. Here are some examples of how awk works in this use case.
awk column printing examples
Suppose you have a file named foo with these contents, three columns of data separated by blanks:
$ cat foo 1 2 3 a b c
Next, here are the awk examples:
$ awk '< print $1 >' foo 1 a $ awk '< print $2 >' foo 2 b $ awk '< print $3 >' foo 3 c $ awk '< print $1, $3 >' foo 1 3 a c $ awk '< print $3, $1 >' foo 3 1 c a
As you can see, with awk you can print any column you want, and you can easily rearrange the order of the columns when you print them out.
If you’re not familiar with awk , notice how it automatically loops over every line in the text file. This built-in ability to process every line in the input file is a great feature of awk .
While all of these examples show how awk works on a file, it can also read its input from a Unix pipeline, like this:
$ cat foo | awk '< print $3, $1 >' 3 1 c a
Using a field separator with awk
If you need to specify a field separator — such as when you want to parse a pipe-delimited or CSV file — use the -F option, like this:
Summary
As shown, awk is a great tool for printing columns and rearranging column output when working with text files.
How to print a range of columns using the `awk` command
![]()
The `awk` command is one of many commands that can be used to print a range of columns from tabular data in Linux. The `awk` command is can be used directly from the terminal by executing the `awk` script file. In this tutorial, we will show you how to print a range of columns from tabular data.
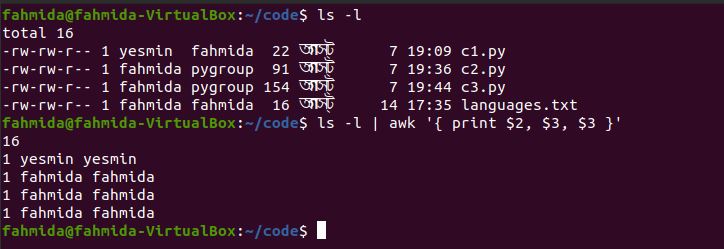
Example 1: Print a range of columns from a command output
The following command will print the second, third, and fourth columns from the command output, ‘ls -l‘. Here, the column numbers are stated explicitly, but a more efficient command for printing the same range of columns is shown in the next example.
The following output is produced by the command above.
Example 2: Print the range of columns from a file by using a for loop
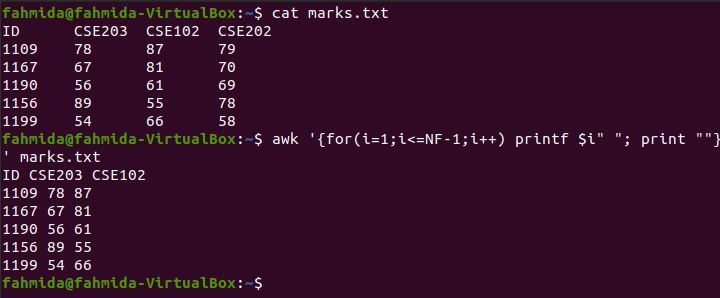
To follow along with this example and the other examples in this tutorial, create a text file named marks.txt with the following content:
The following `awk` command will print the first three columns of marks.txt. The for loop is used to print the column values, and the loop includes three steps. The NF variable indicates the total numbers of fields or columns of the file.
The following output will be produced by running the command. The output shows the student IDs and the marks for CSE203 and CSE102.
Example 3: Print the range of columns by defining starting and ending variables
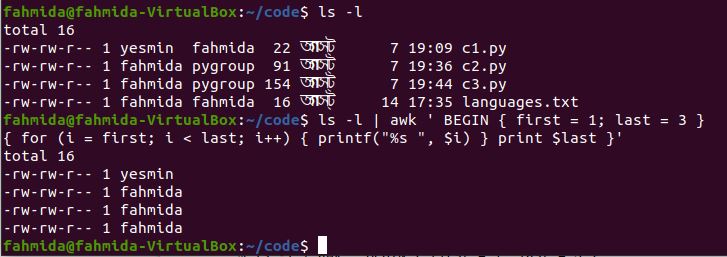
The following `awk` command will print the first three columns from the command output ‘ls -l’ by initializing the starting and ending variables. Here, the value of the starting variable is 1, and the value of the ending variable is 3. These variables are iterated over in a for loop to print the column values.
The following output will appear after running the command. The output shows the first three column values of the output, ‘ls -l’.
Example 4: Print a range of columns from a file with formatting
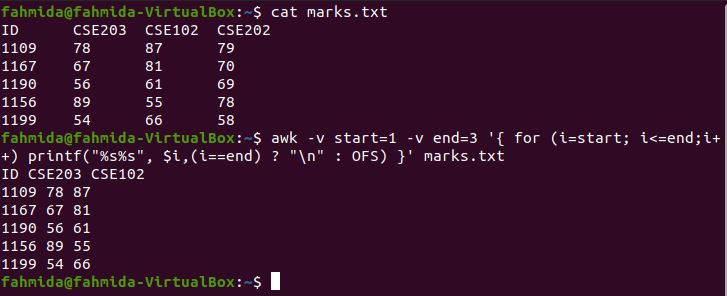
The following `awk` command will print the first three columns of marks.txt using printf and output field separator (OFS). Here, the for loop includes three steps, and three columns will be printed in sequence from the file. OFS is used here to add space between columns. When the counter value of the loop (i) equals the ending variable, then a newline(\n) is generated.
The following output will be generated after running the above commands.
Example 5: Print the range of columns from a file using a conditional statement
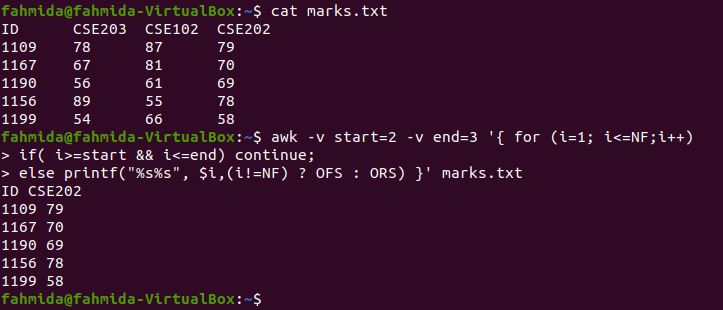
The following `awk` command will print the first and last columns from a file by using a for loop and an if statement. Here, the for loop includes four steps. The starting and ending variables are used in the script to omit the second and third columns from the file by using the if condition. The OFS variable is used to add space between the columns, and the ORS variable is used to add a newline(\n) after printing the last column.
$ cat marks.txt
$ awk -v start = 2 -v end = 3 ‘ < for (i=1; i<=NF;i++)
if( i>=start && i <=end) continue;
else printf(«%s%s», $i,(i!=NF) ? OFS : ORS) >’ marks.txt
The following output will appear after running the above commands. The output shows the first and last columns of marks.txt.
Example 6: Print the range of columns from a file using the NF variable
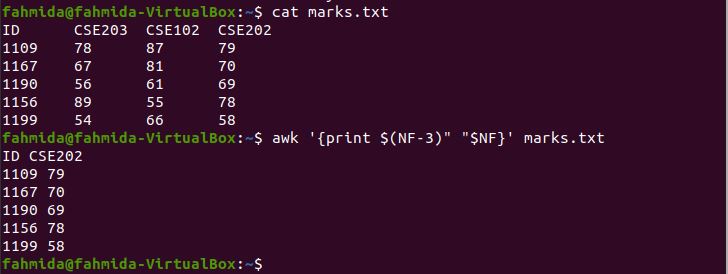
The following `awk` command will print the first and last columns from the file by using an NF variable. No loops or conditional statements are used to print the column values. NF indicates the number of fields. There are four columns in marks.txt. $(NF-3) defines the first column, and $NF indicates the last column.
$ cat marks.txt
$ awk » marks.txt
The following output is produced by running the above commands. The output shows the first and last columns of marks.txt.
Example 7: Print the range of columns from a file using substr() and index()
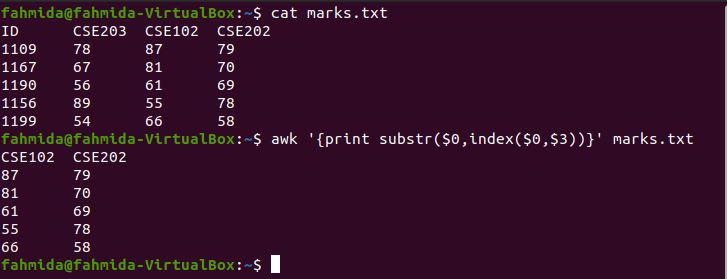
The index() function returns a position if the second argument value exists in the first argument value. The substr() function can take three arguments. The first argument is a string value, the second argument is the starting position, and the third argument is the length. The third argument of substr() is omitted in the following command. Because the column starts from $1 in the `awk` command, the index() function will return $3, and the command will print from $3 to $4.
$ cat marks.txt
$ awk » marks.txt
The following output will be produced by running the above commands.
Example 8: Sequentially print a range of columns from a file using printf
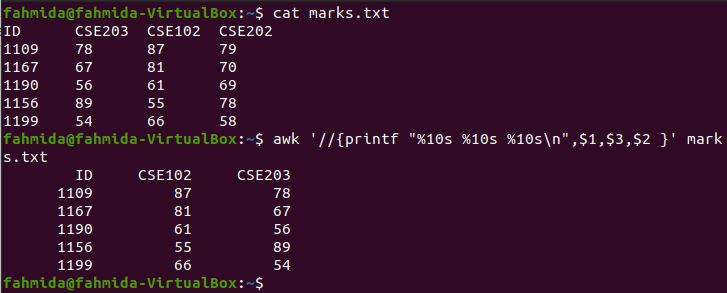
The following `awk` command will print the first, second, and third columns of marks.txt by setting enough space for 10 characters.
$ cat marks.txt
$ awk ‘//’ marks.txt
The following output will be produced by running the above commands.
Conclusion
There are various ways to print the range of columns from the command output or a file. This tutorial shows how `awk` command can help Linux users to print content from tabular data.
About the author
Fahmida Yesmin
I am a trainer of web programming courses. I like to write article or tutorial on various IT topics. I have a YouTube channel where many types of tutorials based on Ubuntu, Windows, Word, Excel, WordPress, Magento, Laravel etc. are published: Tutorials4u Help.
How to Use Awk to Print Fields and Columns in File
In this part of our Linux Awk command series, we shall have a look at one of the most important features of Awk, which is field editing.
It is good to know that Awk automatically divides input lines provided to it into fields, and a field can be defined as a set of characters that are separated from other fields by an internal field separator.

If you are familiar with the Unix/Linux or do bash shell programming, then you should know what internal field separator (IFS) variable is. The default IFS in Awk are tab and space.
This is how the idea of field separation works in Awk: when it encounters an input line, according to the IFS defined, the first set of characters is field one, which is accessed using $1, the second set of characters is field two, which is accessed using $2, the third set of characters is field three, which is accessed using $3 and so forth till the last set of character(s).
To understand this Awk field editing better, let us take a look at the examples below:
Example 1: I have created a text file called tecmintinfo.txt.
# vi tecmintinfo.txt # cat tecmintinfo.txt

Then from the command line, I try to print the first, second and third fields from the file tecmintinfo.txt using the command below:
$ awk '//' tecmintinfo.txt TecMint.comisthe
From the output above, you can see that the characters from the first three fields are printed based on the IFS defined which is space:
- Field one which is “TecMint.com” is accessed using $1 .
- Field two which is “is” is accessed using $2 .
- Field three which is “the” is accessed using $3 .
If you have noticed in the printed output, the field values are not separated and this is how print behaves by default.
To view the output clearly with space between the field values, you need to add (,) operator as follows:
$ awk '//' tecmintinfo.txt TecMint.com is the
One important thing to note and always remember is that the use of ($) in Awk is different from its use in shell scripting.
Under shell scripting ($) is used to access the value of variables while in Awk ($) it is used only when accessing the contents of a field but not for accessing the value of variables.
Example 2: Let us take a look at one other example using a file which contains multiple lines called my_shoping.list.
No Item_Name Unit_Price Quantity Price 1 Mouse #20,000 1 #20,000 2 Monitor #500,000 1 #500,000 3 RAM_Chips #150,000 2 #300,000 4 Ethernet_Cables #30,000 4 #120,000
Say you wanted to only print Unit_Price of each item on the shopping list, you will need to run the command below:
$ awk '//' my_shopping.txt Item_Name Unit_Price Mouse #20,000 Monitor #500,000 RAM_Chips #150,000 Ethernet_Cables #30,000
Awk also has a printf command that helps you to format your output is a nice way as you can see the above output is not clear enough.
Using printf to format output of the Item_Name and Unit_Price:
$ awk '//' my_shopping.txt Item_Name Unit_Price Mouse #20,000 Monitor #500,000 RAM_Chips #150,000 Ethernet_Cables #30,000
Summary
Field editing is very important when using Awk to filter text or strings, it helps you get particular data in columns in a list. And always remember that the use of ($) operator in Awk is different from that in shell scripting.
I hope the article was helpful to you and for any additional information required or questions, you can post a comment in the comment section.
Printing column separated by comma using Awk command line
I have a problem here. I have to print a column in a text file using awk. However, the columns are not separated by spaces at all, only using a single comma. Looks something like this:
column1,column2,column3,column4,column5,column6 Why you would like to use awk ? IMHO this is a very simple problem. Do You have any attemt to solve it?
4 Answers 4
Here in -F you are saying to awk that use , as the field separator.
I have been browsing through a lot of pages and got a lot more of results and this was by far the best 🙂 Thank you
If your only requirement is to print the third field of every line, with each field delimited by a comma, you can use cut:
- -d, sets the delimiter to a comma
- -f3 specifies that only the third field is to be printed
This is the best answer for this question. awk comes in very handy when lets say I want to print [col1]:[col5] with different dels and a different formatting
As well as being shorter, this is much more difficult for someone unfamiliar with awk to understand. It would be worth adding some explanation to make this answer more useful.
@TomFenech: I think cut -d, -f3 file is as cryptic as this one if someone is unfamiliar with cut . 😉
@TrueY granted, although one difference is that cut —help would explain everything that you needed to know, whereas awk —help wouldn’t. Perhaps I should’ve gone for cut —delimiter=, —fields=3 file , although I have my doubts that the longer switches are portable 🙂
A simple, although awk-less solution in bash:
while IFS=, read -r a a a b; do echo "$a"; done EDIT from Ed Morton (sorry for hi-jacking the answer, I don't know if there's a better way to address this):
To put to rest the myth that shell will run faster than awk for small files:
$ wc -l file 99 file $ time while IFS=, read -r a a a b; do echo "$a"; done /dev/null real 0m0.016s user 0m0.000s sys 0m0.015s $ time awk -F, '' file >/dev/null real 0m0.016s user 0m0.000s sys 0m0.015s
I expect if you get a REALY small enough file then you will see the shell script run in a fraction of a blink of an eye faster than the awk script but who cares?
And if you don't believe that it's harder to write robust shell scripts than awk scripts, look at this bug in the shell script you posted:
$ cat file a,b,-e,d $ cut -d, -f3 file -e $ awk -F, '' file -e $ while IFS=, read -r a a a b; do echo "$a"; done