BASH — If else, Regular expression, OR
My bash script is supposed to check if the user inputs two numbers. Each number should be preceded by either a + or a — sign. The first number should be four digits long, and the second number should be five digits long. No matter what values I enter, the output is always Fail Command-line statement to run the script:
#!/bin/bash #Script name add if [ $1 != [\+\-]8116 ] || [ $2 != [\+\-]63934 ] then echo Fail else echo Success fi 3 Answers 3
POSIX-style tests ( [ ) don’t perform pattern matching at all. The != operator is a string comparison. ksh-style tests ( [[ )) perform pattern matching with reglular shell patterns using the == operator, and ERE matching with =~ . (There is no !=~ , but we can DeMorganify)
To perform pattern matching in POSIX sh, the only option is the case statement.
I don’t think there is a way (I was wrong, there is a way) to do pattern matching using if statement. case can be used for such things. Working example:
#!/bin/bash #Script name add case $1 in [+-]3219) r1='success' ;; *) r1='fail' ;; esac case $2 in [+-]67625) r2='success' ;; *) r2='fail' ;; esac if [ $r1 = 'fail' ] || [ $r2 = 'fail' ] then echo Fail else echo Success fi && will execute the next command as long as the previous one does NOT fail. || will execute the next command if the previous one DOES fail. Which does work. Just not the way that I would construct it, but doesn’t make it incorrect. My bad 🙂 I deleted my previous (incorrect) comment.
You need to use double brackets to enable advanced functionality that is more similar to traditional programming languages. For instance, to use || instead of -o and && instead of -a . Double brackets are also required in order to perform pattern (matching.
Also, brackets should be used for the entire expression, not for each sub-expression separately and should include the || .
if [[ $1 == [+-]7742 && $2 == [+-]86138 ]] then echo "success" else echo "fail" fi EDIT: using == instead of != (why be so negative?) and to remove references to regex (uses pattern matching).
@tripleee not true, see the edit to my answer to see how you’re wrong. Did you test it out before making silly statements?
@DavidDraughn That means shell glob patterns, not regular expressions. Citing the ABS as factual information should never be done. It’s wrong about many things. See the PATTERN MATCHING section of your bash manpage. Your example can be made to work properly with extglob enabled.
What’s the problem here? You were right the first time, @DavidDraughn. The only mistake was in using the term «regex», though «pattern match» is also used (the code is valid as both regex and shell pattern). «Globbing» technically means only «filename expansion», but they are often used interchangeably. I prefer what you have now, but also [[ $1 != pat || $2 != pattern ]] and [[ ! $1 == pat || ! $2 == pat ]] are exactly equivalent. Both == and != match shell patterns. Neither match regex. Beginning in Bash 4.1 alpha, extglob patterns are forced on within [[ for == and != .
Regex Matching in a Bash if Statement
![]()
In many programming languages, including Bash, regular expressions known as regex, are an effective tool for pattern matching and text processing. The if statement is a common control structure used in Bash scripts to execute certain commands based on certain conditions. In Bash, you can use regex to match patterns in if statements to control the execution of the script and this guide is all about Regex matching in a Bash if statement.
Regex Matching in a Bash if Statement
The syntax for using regex in a Bash if statement is straightforward as you can use the =~ operator to match a string against a regular expression pattern, here is an example:
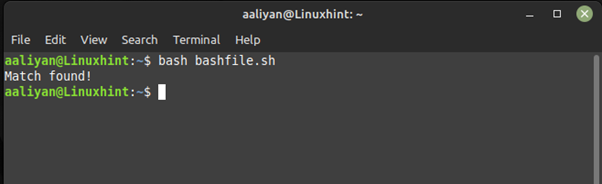
#!/bin/bash
if [ [ «Hello Linux» =~ ^Hello. * ] ] ; then
echo «Match found!»
else
echo «No match found.»
fi
The if statement checks if the string “Hello Linux” matches the regular expression pattern “^Hello.*”. The caret (^) symbol in the pattern indicates the beginning of the string, and the dot-star (. ) matches any character zero or more times.
If the match is found, the script will execute the commands in the then block. In this case, the script will print “Match found!” to the console. If there is no match, the script will execute the commands in the else block, which will print “No match found.” to the console:
You can also use regex to match against variables in a Bash script, here is an example:
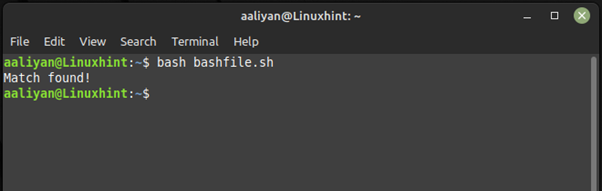
if [ [ $str =~ ^Hello. * ] ] ; then
echo «Match found!»
else
echo «No match found.»
fi
Here the if statement checks if the variable “str” matches the regular expression pattern “^Hello.*”. The variable is enclosed in double quotes to prevent word splitting and filename expansion:
Conclusion
A Bash if statement with regex matching is a effective tool for text processing and pattern matching in Bash scripts. It can be used to limit how your scripts are executed based on particular criteria. By mastering regex matching in Bash, you can write more efficient and effective scripts that automate your workflow and save you time and effort.
About the author
Aaliyan Javaid
I am an electrical engineer and a technical blogger. My keen interest in embedded systems has led me to write and share my knowledge about them.
if with regex in bash code
In bash I did the following. This if expression will evaluate to true if the Redhat version is 7.5 or 7.6.
if [[ ` cat /etc/redhat-release | awk '' ` == "7.5" ]] || [[ ` cat /etc/redhat-release | awk '' ` == "7.6" ]] then . . . Can we do it in a more elegant way with regular expressions? This is the content of /etc/redhat-release :
cat /etc/redhat-release Red Hat Enterprise Linux Server release 7.6 (Maipo) Of course, using the VERSION_ID from the intended-to-be-machine-readable /etc/os-release is easier than parsing the human-readable string in /etc/redhat-release . Luckily for doing that, this is RHEL (where bug #1240624 was fixed in version 7.2) and not CentOS or Debian or Arch. unix.stackexchange.com/a/382537/5132 unix.stackexchange.com/a/125241/5132
4 Answers 4
Far simpler just to check the release string directly
if grep -q 'release 7\.[56] ' /etc/redhat-release then . The grep command matches by regular expression. The [56] atom matches 5 or 6 , allowing the pattern to match on 7.5 or 7.6 . Since . matches any character I’ve escaped it with a backslash so that it matches a literal dot. The trailing space ensures there are no other characters following the matched version string.
Personally, I’d use grep -q ‘release 7[.][56] ‘ — IMO still fairly readable, and you don’t have to worry about it failing when release 705 comes out. (or. does Red Hat use alpha-beta numbers like 7a5?) The big advantage of [] instead of escaping is that you don’t have to worry about whether you might have to double-escape (or triple, or. ) based on what kind of quotes it’s in, etc.
That’s an interesting approach. I had to read it twice though, so maybe I should have just gone for \. in the first place.
You can do this with bash ‘s built-in string matching. Note that this uses glob (wildcard) patterns, not regular expressions.
if [[ $(cat /etc/redhat-release | awk '') == 7.[56] ]] if [[ $(awk '' /etc/redhat-release) == 7.[56] ]] if [[ $(cat /etc/redhat-release) == *" release 7."[56]" "* ]] (Note that wildcards at the beginning and end are needed to make it match the entire line. The quoted space after the number is to make sure it doesn’t accidentally match «7.50».)
Or if you really want to use regular expressions, use =~ and switch to RE syntax:
(Note that the part in quotes will be matched literally, so . doesn’t need to be escaped or bracketed (as long as you don’t enable bash31 compatibility). And RE matches aren’t anchored by default, so you don’t need anything at the ends like in the last one.)
use regular expression in if-condition in bash
Why the last three fails to match? Hope you could give as many general rules as possible, not just for this example.
5 Answers 5
When using a glob pattern, a question mark represents a single character and an asterisk represents a sequence of zero or more characters:
if [[ $gg == . grid* ]] ; then echo $gg; fi When using a regular expression, a dot represents a single character and an asterisk represents zero or more of the preceding character. So » .* » represents zero or more of any character, » a* » represents zero or more «a», » 7* » represents zero or more digits. Another useful one (among many) is the plus sign which represents one or more of the preceding character. So » [a-z]+ » represents one or more lowercase alpha character (in the C locale — and some others).
if [[ $gg =~ ^. grid.*$ ]] ; then echo $gg; fi So there are two ways of string matching: glob pattern and regular expression? Is glob pettern not only used for file names? In bash, when to use glob pattern and when to use regular expression? Thanks!
@Tim: Globbing is available in most or all versions of Bash. Regex matching is available only in version 3 and higher, but I’d recommend only using it in 3.2 and later. Regexes are much more versatile than globbing.
You should be able to use «.<4>» instead of «. «, ie «^.<4>grid.*». It can be easier to read and understand.
Adding this solution with grep and basic sh builtins for those interested in a more portable solution (independent of bash version; also works with plain old sh , on non-Linux platforms etc.)
# GLOB matching gg=svm-grid-ch case "$gg" in *grid*) echo $gg ;; esac # REGEXP if echo "$gg" | grep '^. grid*' >/dev/null ; then echo $gg ; fi if echo "$gg" | grep '. grid*' >/dev/null ; then echo $gg ; fi if echo "$gg" | grep 's. grid*' >/dev/null ; then echo $gg ; fi # Extended REGEXP if echo "$gg" | egrep '(^. grid*|. grid*|s. grid*)' >/dev/null ; then echo $gg fi Some grep incarnations also support the -q (quiet) option as an alternative to redirecting to /dev/null , but the redirect is again the most portable.
Is glob pettern not only used for file names?
No, «glob» pattern is not only used for file names. you an use it to compare strings as well. In your examples, you can use case/esac to look for strings patterns.
gg=svm-grid-ch # looking for the word "grid" in the string $gg case "$gg" in *grid* ) echo "found";; esac # [[ $gg =~ ^. grid* ]] case "$gg" in . grid*) echo "found";; esac # [[ $gg =~ s. grid* ]] case "$gg" in s. grid*) echo "found";; esac In bash, when to use glob pattern and when to use regular expression? Thanks!
Regex are more versatile and «convenient» than «glob patterns», however unless you are doing complex tasks that «globbing/extended globbing» cannot provide easily, then there’s no need to use regex. Regex are not supported for version of bash
Update for OP: Example to find files that start with 2 characters (the dots «.» means 1 char) followed by «g» using regex
$ shopt -s dotglob $ ls -1 * abg degree ..g $ for file in *; do [[ $file =~ "..g" ]] && echo $file ; done abg degree ..g In the above, the files are matched because their names contain 2 characters followed by «g». (ie ..g ).
The equivalent with globbing will be something like this: (look at reference for meaning of ? and * )
$ for file in ??g*; do echo $file; done abg degree ..g