- How to Read a File Line By Line in Bash?
- Prerequisites: A File and Lines to Read
- Method 1: Using the read Command With the While Loop
- Method 2: Using the cat Command and for Loop
- Method 3: Read a File Line by Line in Bash Using File Descriptors
- Method 4: Using Different Strings
- Method 5: Using Process Substitution
- Conclusion
- How to Read Files Line by Line in Bash
- Reading Line by Line in Bash
- Method 1: Using Read Command and While Loop
- Method 3: Using here Strings
- Method 5: Using Process Substitution
- Read line by line in Bash script
How to Read a File Line By Line in Bash?
While working with the bash scripts, sometimes we have to read all the lines from the bash scripts. By reading every line of the bash scripts, we can extract the outputs or serve a specific programming purpose.
This post will elaborate on how to read a file line by line. The content of the post is as follows:
- Prerequisites: A File and Lines to Read
- Method 1: Using the read command with the while loop
- Method 2: Using the cat command and for loop
- Method 3: Using File Descriptors
- Method 4: Using different strings
- Method 5: Using Process Substitution
Prerequisites: A File and Lines to Read
Before proceeding with the methods, first, create and add some text which will be then read by a bash script. In our case, we used the nano editor to serve the purpose:
$ nano linux_distributions.txt
Next, type some data names into it:
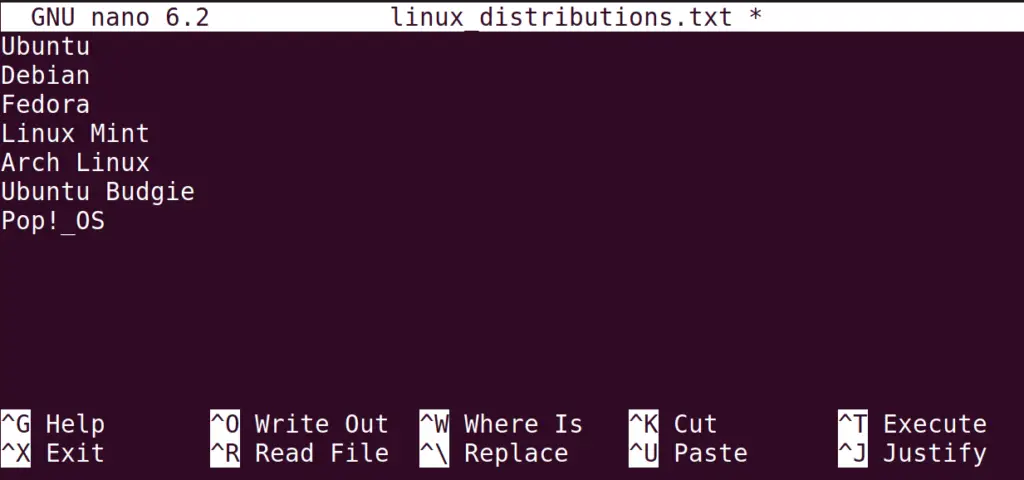
Save the file using “CTRL+S” and exit the editor via the “CTRL+X” command.
Method 1: Using the read Command With the While Loop
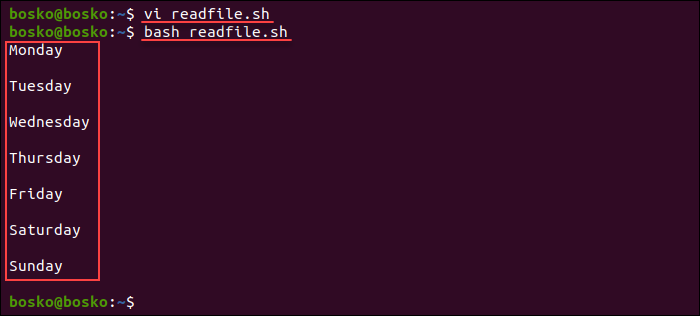
In this method, the read command will be utilized with the while loop to read a text file line by line. First, we will create a bash script file named “line_read.sh” with the nano text editor:
Then type the below bash script to read the “linux_distributions.txt” file line by line:
#!/bin/bash file="linux_distributions.txt" while read -r line; do echo -e "$line\n" done
The script’s code is explained below:
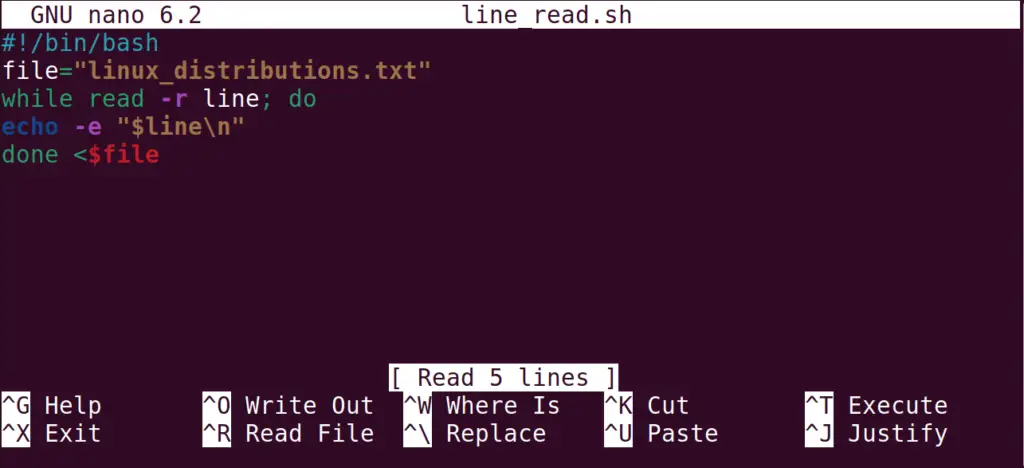
- With the help of the “-r”, read each line of the file in a while loop
- Save each line in the “line” variable and print it on the screen using the “e” option
- On completing the while loop, the data has been stored in the “file” variable
Then, use the command mentioned-below to run the “line_read.sh” script:
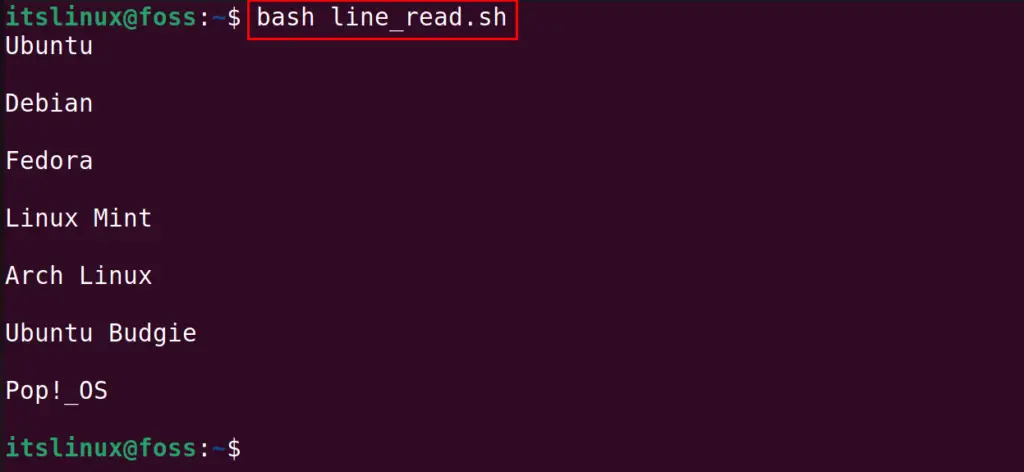
All the lines are being read and displayed on the screen using the bash script.
Method 2: Using the cat Command and for Loop
In this method, we use the cat command with to read all the content of the “linux_distributions.txt” file.
As an experiment, we are using the following code.
#!/bin/bash file=$(cat linux_distributions.txt) for line in $file do echo -e "$line\n" done
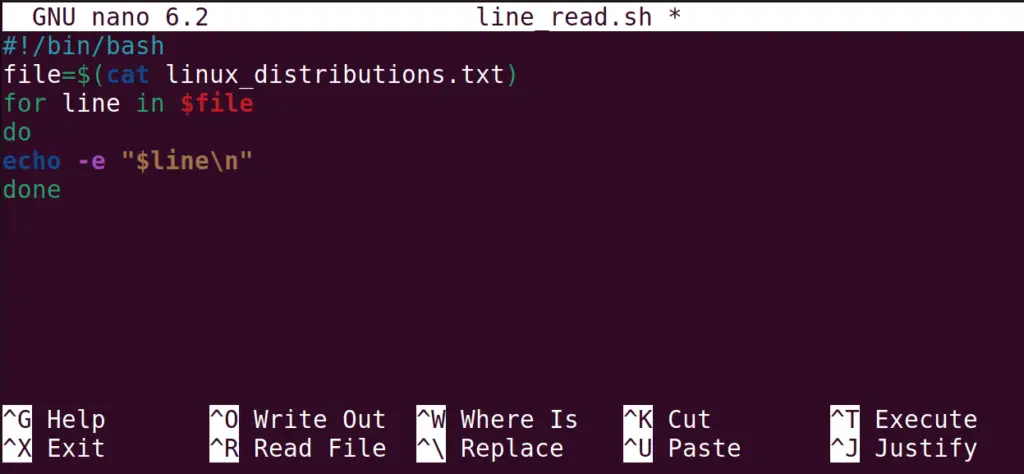
The explanation of the above script is:
- Read the file using the cat command and store it in the variable file
- Use the for loop to display the contents as well as to save them in “file” variable
- Terminate the for loop with the done word
Run the bash script again of line_read.sh:
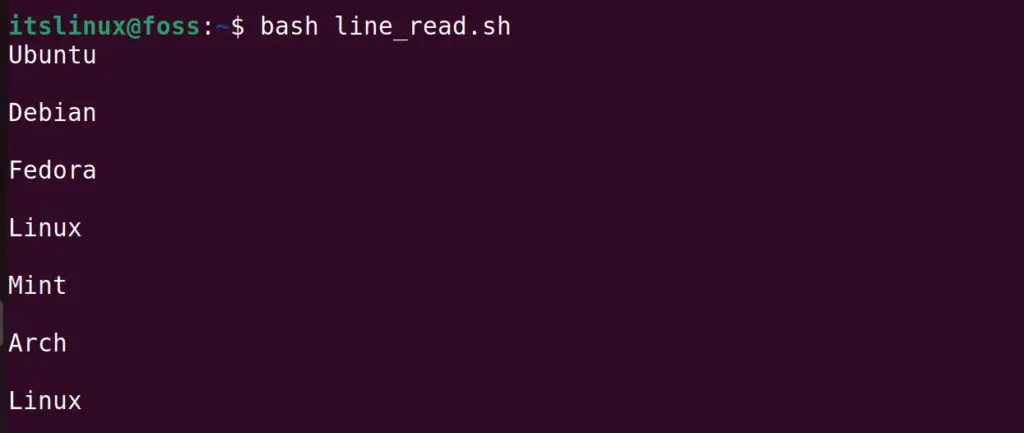

The contents of the file have been read line by line.
Method 3: Read a File Line by Line in Bash Using File Descriptors
In this method, file descriptors are used in a bash script to read the file line by line, for example, the following lines of code are used in the test bash script.
#!/bin/bash while IFS= read -r -u9 line; do printf '%s\n' "$line" done 9< linux_distributions.txt
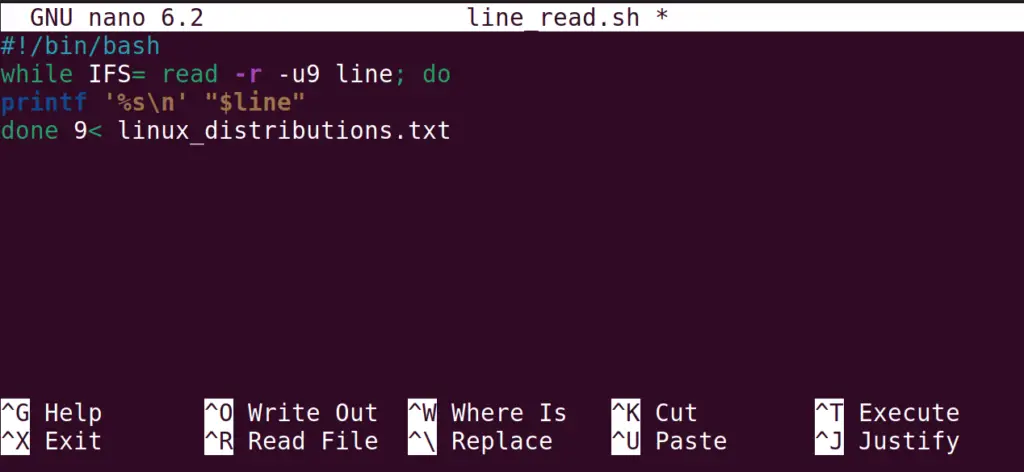
- The while loop IFS(internal File Separator) is used to read the lines of the specified file with the -u argument
- Then display the line with the same descriptor as used in while loop by using the “9
Save the file and exit the nano text editor to run the bash script:
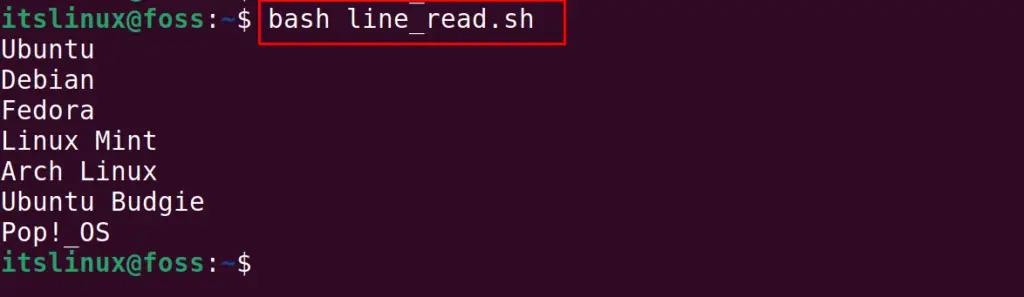
The bash script is read line by line.
Method 4: Using Different Strings
This is similar to the above method as we used the IFS but will set no arguments unlikely the above method. The bash script’s test code we used is written below:
#!/bin/bash while IFS= read -r line; do printf '%s\n' "$line" done
The explanation of the above bash script is:
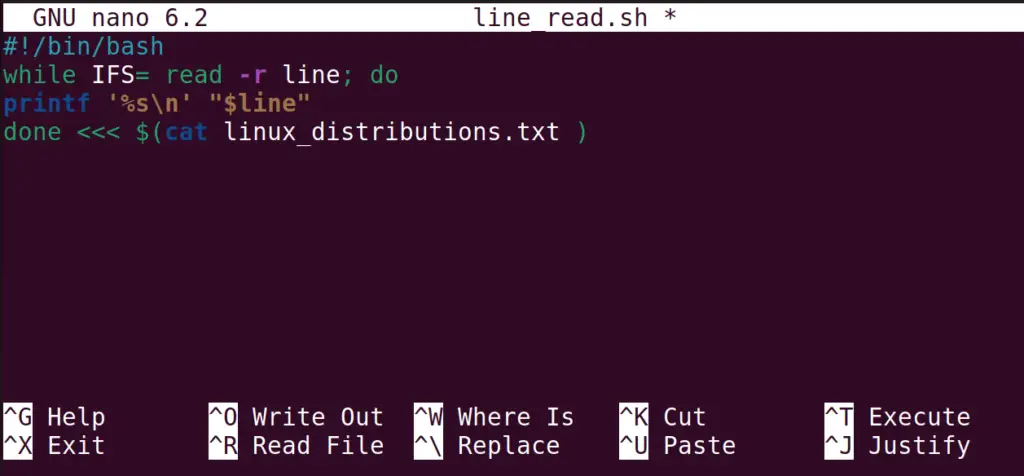
- Use the while loop and read all the lines using the IFS
- Then display the lines by saving them in variable line
- And in specified the file by using the cat command
Run the above bash script with the command:
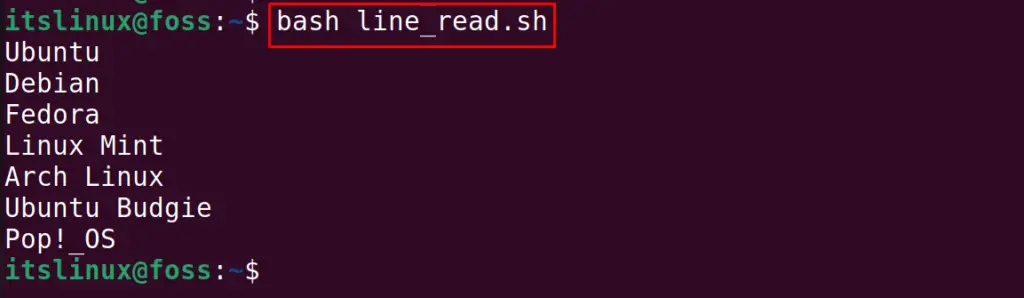
The lines have been read line by line using the above bash script.
Method 5: Using Process Substitution
In this method, we will substitute the standard output of the file and then treat it as the standard input for the next process. For reading the linux_distributions.txt file, the following script’s code is utilized.
#!/bin/bash while IFS= read -r line; do printf '%s\n' "$line" done < <(cat linux_distributions.txt)
In the above bash script, the only difference as compared to method 4 is that the output file is enclosed in the () and then sent to the process as the input and to see the output, run the command:
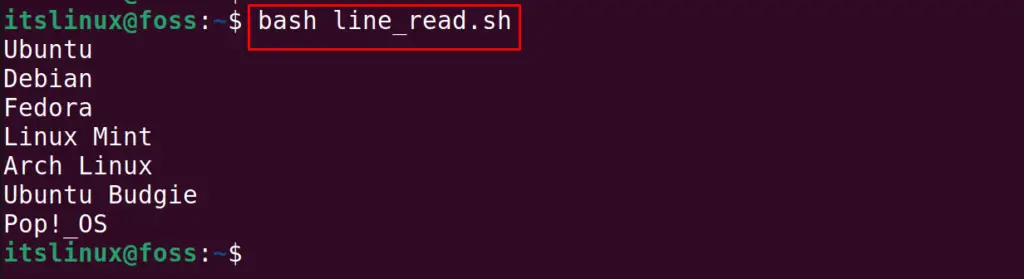
That’s how you can read a file line by line in Bash.
Conclusion
To read a file line by line in a bash script, we can use the read command with the while loop or the cat command with the for a loop, and the three other methods can also be used to read a file. In this blog, five different methods of reading file line by line in the bash script have been discussed in detail.
How to Read Files Line by Line in Bash
Reading a file line by line allows you to effectively process a file's contents and output each line as an element in a list. After displaying each line separately, search for or match any specific content easily.
One of the ways to read a text file in individual lines is to use the Bash shell.
In this tutorial, you will learn to read a file line by line in Bash.

- A system running Linux.
- Access to a terminal (Ctrl + Alt + T).
- A text editor (such as Nano or vi/vim).
Reading Line by Line in Bash
There are several methods for reading a file line by line using Bash. The following sections highlight five methods for processing a file one line at a time using Bash.
Method 1: Using Read Command and While Loop
The first method is to use the read command and a while loop in a Bash script. While it is possible to do the same in a terminal, Bash scripts save the code and make it reusable. Follow the steps below:
1. Open the terminal (Ctrl + Alt + T) and create a new Bash script using a text editor such as vi/vim:
2. Enter the following lines:
#!/bin/bash file="days.txt" while read -r line; do echo -e "$line\n" done - The $file variable is defined after the shebang line (the first line in Bash scripts), and it stores the path to the input file you want to process.
- The -r argument appended to the read command prevents the interpretation of any backslash-escaped characters while reading the file's contents.
Note: Prevent the read command from trimming leading/trailing whitespaces by setting the internal field separator to an empty string - IFS= .
- Each line's contents are stored in the $line variable. Within the while loop, the echo command prints the $line variable's contents. The -e argument allows echo to interpret special characters such as the newline character \n .
- The while loop continues until it reaches the end of the file and the loop ends.
Note: Use printf instead of echo to print and format the output. Learn to use the Bash printf command.

The script outputs each line of the example text file separately.
Method 2: Using cat Command and for Loop
Another method to display a file's contents in individual lines is to use the cat command and the for loop. The for loop allows echo to print the lines from the cat command output until it reaches the end of the file.
Note: Learn more about the Bash for loop and see examples of using the loop.
2. Enter the following lines:
#!/bin/bash file=$(cat days.txt) for line in $file do echo -e "$line\n" done
- The $file variable stores the input file's contents using the cat command.
- The for loop iterates through each line of the cat command output and prints it using the echo command until it reaches the end of the file.

The script outputs the file's contents line by line in standard output.
Method 3: Using here Strings
Another method of printing a file's contents line by line is to use a here string to feed the file's contents to the read command. The here string connects the contents of a variable, string, or file specified after the syntax to the standard input of the invoked program.
Note: A here string is a simpler form of a here document.
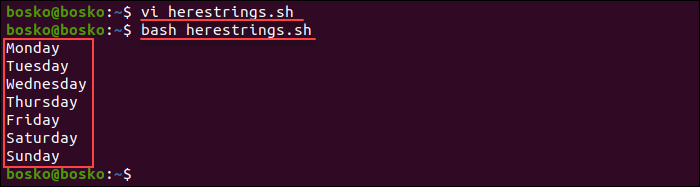
1. Create a new Bash script:
2. Enter the following lines:
#!/bin/bash while IFS= read -r line; do printf '%s\n' "$line" done
- In the while loop, the IFS= argument is an empty string to prevent trimming whitespaces.
- The -r argument prevents the interpretation of backslash-escaped characters.
- The printf command prints each line of the file. The format specifiers treat the input as a string ( %s ) and add a newline character ( \n ) after each line.
- The here string feeds the cat command's output to the read command.
3. Save the script and exit the editor:

The output prints the file's contents line by line.
Method 4: Using File Descriptors
A file descriptor refers to an open file or process. Each process has three default file descriptors:
Provide the input for the read command using a file descriptor and output each line from the file's contents separately. Follow the steps below:
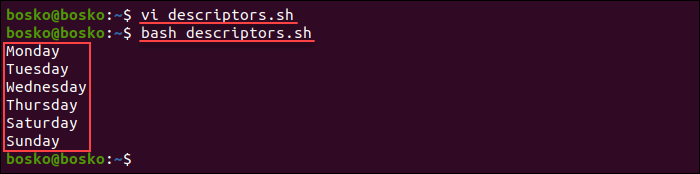
1. Create a new bash script:
2. Enter the following lines:
#!/bin/bash while IFS= read -r -u9 line; do printf '%s\n' "$line" done 9< days.txt
- In the while loop, instruct the read command to read input from a file descriptor by specifying the -u argument and the file descriptor number.
Important: When specifying file descriptors, use a number between 4 and 9 to avoid conflict with the internal shell file descriptors.
- The printf command treats the input $line variable as a string ( %s ) and adds a newline character ( \n ) after printing the $line contents.
- The 9 syntax contains the same file descriptor number as in the while loop. The input file's contents are sent to the specified file descriptor.
4. Execute the script to test the code:

The script output prints each line of the file separately.
Method 5: Using Process Substitution
Process substitution allows the standard output of a process (or processes) to appear as a file, and feeds it into another process' standard input. Use process substitution to supply the input file and print each file line separately.
2. Enter the following lines:
#!/bin/bash while IFS= read -r line; do printf '%s\n' "$line" done < <(cat days.txt)
Read line by line in Bash script
The best way to do this is to redirect the file into the loop:
# Basic idea. Keep reading for improvements. FILE=test while read CMD; do echo "$CMD" done < "$FILE"
There are some additional improvements that could be made:
- Add IFS= so that read won't trim leading and trailing whitespace from each line.
- Add -r to read to prevent backslashes from being interpreted as escape sequences.
- Lower-case CMD and FILE . The Bash convention is that only environmental and internal shell variables are uppercase.
- Use printf in place of echo which is safer if $cmd is a string like -n , which echo would interpret as a flag.
file=test while IFS= read -r cmd; do printf '%s\n' "$cmd" done < "$file"
use
What you have is piping the text "cat test" into the loop.
cat test | \ while read CMD; do echo $CMD done
xargs is the most flexible solution for splitting output into command arguments.
It is also very human readable and easy to use due to its simple parameterisation.
Format is xargs -n $NUMLINES mycommand .
For example, to echo each individual line in a file /tmp/tmp.txt you'd do:
cat /tmp/tmp.txt | xargs -n 1 echo
Or to diff each successive pair of files listed as lines in a file of the above name you'd do:
cat /tmp/tmp.txt | xargs -n 2 diff
The -n 2 instructs xargs to consume and pass as separate arguments two lines of what you've piped into it at a time.
You can tailor xargs to split on delimiters besides carriage return/newline.
Use man xargs and google to find out more about the power of this versatile utility.