- How to change character encoding of a text file on Linux
- Step One: Detect Character Encoding of a File
- Step Two: Find Out Supported Text Encodings
- Step Three: Convert Text Encoding
- Support Xmodulo
- How to Convert Files to UTF-8 Encoding in Linux
- Convert Files from UTF-8 to ASCII Encoding
- Convert Multiple Files to UTF-8 Encoding
- How to Determine and Change File Character Encoding of Text Files in Linux Systems
- Part 1: Detect a File’s Encoding using file Linux command
- Part 2: Change a File’s Encoding using iconv Linux command
How to change character encoding of a text file on Linux
Question: I have an «iso-8859-1»-encoded subtitle file which shows broken characters on my Linux system, and I would like to change its text encoding to «utf-8» character set. In Linux, what is a good tool to convert character encoding in a text file?
As you already know, computers can only handle binary numbers at the lowest level — not characters. When a text file is saved, each character in that file is mapped to bits, and it is those «bits» that are actually stored on disk. When an application later opens that text file, each of those binary numbers are read and mapped back to the original characters that are understood by us human. This «save and open» process is best performed when all applications that need access to a text file «understand» its encoding, meaning the way binary numbers are mapped to characters, and thus can ensure a «round trip» of understandable data.
If different applications do not use the same encoding while dealing with a text file, non-readable characters will be shown wherever special characters are found in the original file. By special characters we mean those that are not part of the English alphabet, such as accented characters (e.g., ñ, á, ü).
The questions then become: 1) how can I know which character encoding a certain text file is using?, and 2) how can I convert it to some other encoding of my choosing?
Step One: Detect Character Encoding of a File
In order to find out the character encoding of a file, we will use a commad-line tool called file . Since the file command is a standard UNIX program, we can expect to find it in all modern Linux distros.
Run the following command:
$ file --mime-encoding filename
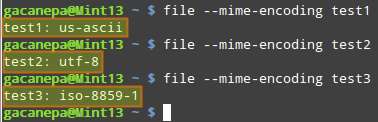
Step Two: Find Out Supported Text Encodings
The next step is to check what kinds of text encodings are supported on your Linux system. For this, we will use a tool called iconv with the -l flag (lowercase L), which will list all the currently supported encodings.
The iconv utility is part of the the GNU libc libraries, so it is available in all Linux distributions out-of-the-box.
Step Three: Convert Text Encoding
Once we have selected a target encoding among those supported on our Linux system, let’s run the following command to perform the conversion:
$ iconv -f old_encoding -t new_encoding filename
For example, to convert iso-8859-1 to utf-8 :
$ iconv -f iso-8859-1 -t utf-8 input.txt
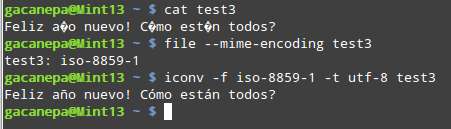
Knowing how to use these tools together as we have demonstrated, you can for example fix a broken subtitle file:
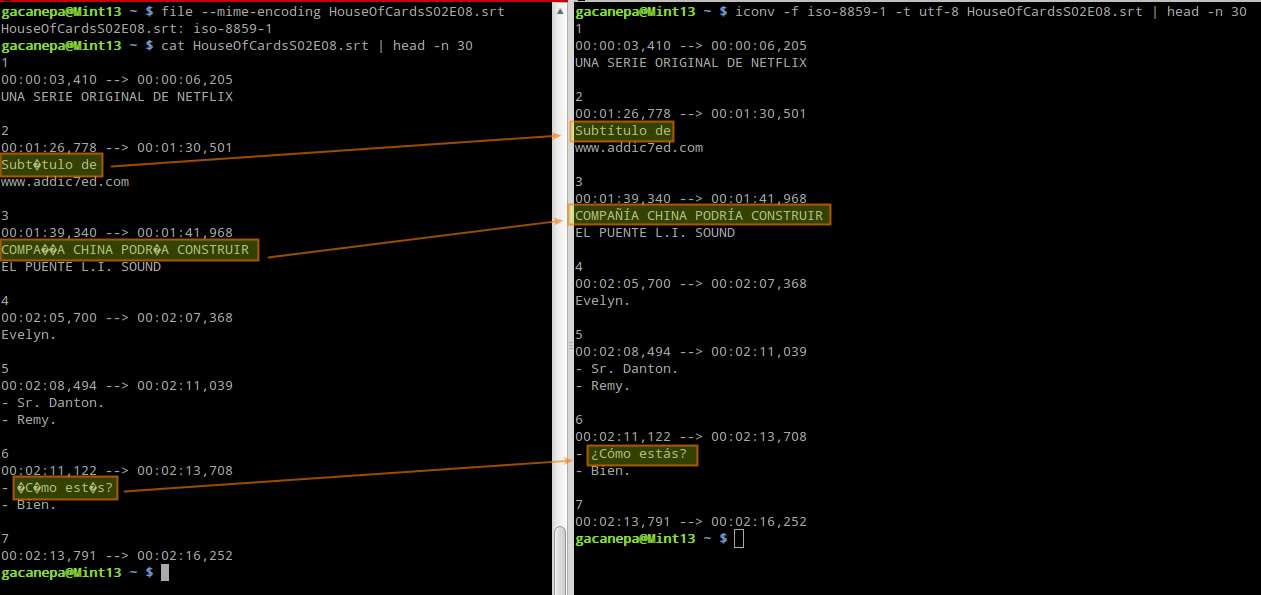
Support Xmodulo
This website is made possible by minimal ads and your gracious donation via PayPal or credit card
Please note that this article is published by Xmodulo.com under a Creative Commons Attribution-ShareAlike 3.0 Unported License. If you would like to use the whole or any part of this article, you need to cite this web page at Xmodulo.com as the original source.
How to Convert Files to UTF-8 Encoding in Linux
In this guide, we will describe what character encoding and cover a few examples of converting files from one character encoding to another using a command line tool. Then finally, we will look at how to convert several files from any character set (charset) to UTF-8 encoding in Linux.
As you may probably have in mind already, a computer does not understand or store letters, numbers or anything else that we as humans can perceive except bits. A bit has only two possible values, that is either a 0 or 1 , true or false , yes or no . Every other thing such as letters, numbers, images must be represented in bits for a computer to process.
In simple terms, character encoding is a way of informing a computer how to interpret raw zeroes and ones into actual characters, where a character is represented by set of numbers. When we type text in a file, the words and sentences we form are cooked-up from different characters, and characters are organized into a charset.
There are various encoding schemes out there such as ASCII, ANSI, Unicode among others. Below is an example of ASCII encoding.
Character bits A 01000001 B 01000010
In Linux, the iconv command line tool is used to convert text from one form of encoding to another.
You can check the encoding of a file using the file command, by using the -i or —mime flag which enables printing of mime type string as in the examples below:
$ file -i Car.java $ file -i CarDriver.java

The syntax for using iconv is as follows:
$ iconv option $ iconv options -f from-encoding -t to-encoding inputfile(s) -o outputfile
Where -f or —from-code means input encoding and -t or —to-encoding specifies output encoding.
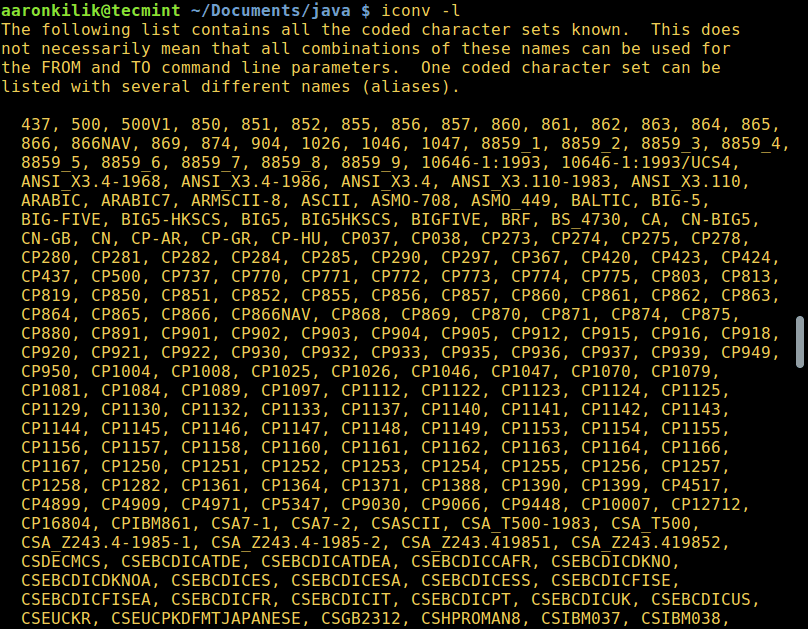
To list all known coded character sets, run the command below:
Convert Files from UTF-8 to ASCII Encoding
Next, we will learn how to convert from one encoding scheme to another. The command below converts from ISO-8859-1 to UTF-8 encoding.
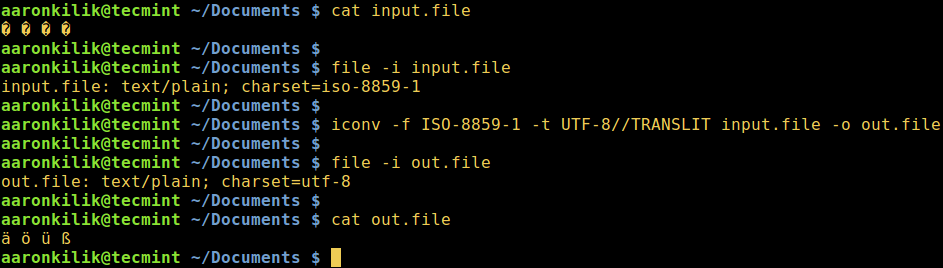
Consider a file named input.file which contains the characters:
Let us start by checking the encoding of the characters in the file and then view the file contents. Closely, we can convert all the characters to ASCII encoding.
After running the iconv command, we then check the contents of the output file and the new encoding of the characters as below.
$ file -i input.file $ cat input.file $ iconv -f ISO-8859-1 -t UTF-8//TRANSLIT input.file -o out.file $ cat out.file $ file -i out.file
Note: In case the string //IGNORE is added to to-encoding, characters that can’t be converted and an error is displayed after conversion.
Again, supposing the string //TRANSLIT is added to to-encoding as in the example above (ASCII//TRANSLIT), characters being converted are transliterated as needed and if possible. Which implies in the event that a character can’t be represented in the target character set, it can be approximated through one or more similar looking characters.
Consequently, any character that can’t be transliterated and is not in target character set is replaced with a question mark (?) in the output.
Convert Multiple Files to UTF-8 Encoding
Coming back to our main topic, to convert multiple or all files in a directory to UTF-8 encoding, you can write a small shell script called encoding.sh as follows:
#!/bin/bash #enter input encoding here FROM_ENCODING="value_here" #output encoding(UTF-8) TO_ENCODING="UTF-8" #convert CONVERT=" iconv -f $FROM_ENCODING -t $TO_ENCODING" #loop to convert multiple files for file in *.txt; do $CONVERT "$file" -o "$.utf8.converted" done exit 0
Save the file, then make the script executable. Run it from the directory where your files ( *.txt ) are located.
$ chmod +x encoding.sh $ ./encoding.sh
Important: You can as well use this script for general conversion of multiple files from one given encoding to another, simply play around with the values of the FROM_ENCODING and TO_ENCODING variable, not forgetting the output file name «$.utf8.converted» .
For more information, look through the iconv man page.
To sum up this guide, understanding encoding and how to convert from one character encoding scheme to another is necessary knowledge for every computer user more so for programmers when it comes to dealing with text.
Lastly, you can get in touch with us by using the comment section below for any questions or feedback.
How to Determine and Change File Character Encoding of Text Files in Linux Systems

How many times did you want to find and detect the encoding of a text files in Linux systems? or How many times did you try to watch a movie and it’s subtitles .srt showed in unreadable shapes “characters” ?
Sure many times you tried/needed to know/change the encoding of text files in Linux systems.
All this because you are using a wrong encoding format for your text files. The solution for this is very simple Just knowing the text files encoding will end your problems. You can either “for example” set your media player to use the correct encoding for your subtitles OR YOU CAN CHANGE THE ENCODING OF YOUR TEXT FILES TO A GLOBAL ACCEPTED ENCODING “UTF-8 FOR EXAMPLE”
This post is divided into two parts. In part 1: I’ll show you how to find and detect the text files encoding in Linux systems using Linux file command available by default in all Linux distributions. In part 2: I’ll show you how to change the encoding of the text files using iconv Linux command between CP1256 (Windows-1256, Cyrillic), UTF-8, ISO-8859-1 and ASCII character sets.
Part 1: Detect a File’s Encoding using file Linux command
The file command makes “best-guesses” about the encoding. Use the following command to determine what character encoding is used by a file :
Example 1 : Detect the encoding of the file “storks.srt”
$ file -ib storks.srt text/plain; charset=iso-8859-1
As you see, “storks.srt” file is encoded with iso-8859-1
Example 2 : Detect the encoding of the file “The.Girl.on.the.Train.2016.1080p.WEB-DL.DD5.1.H264-FGT.srt”
$ file -ib The.Girl.on.the.Train.2016.1080p.WEB-DL.DD5.1.H264-FGT.srt text/plain; charset=utf-8
Here’s the “The.Girl.on.the.Train.2016.1080p.WEB-DL.DD5.1.H264-FGT.srt” file is utf-8 encoded.
Finally, file command is perfect for telling you what exactly the encoding of a text file. You can use it to detect if your text file is encoded with UTF-8, WINDOWS-1256, ISO-8859-6, GEORGIAN-ACADEMY, etc…
Part 2: Change a File’s Encoding using iconv Linux command
To use iconv Linux command you need to know the encoding of the text file you need to change it. Use the following syntax to convert the encoding of a file :
$ iconv -f [encoding] -t [encoding] [filename] > [output_filename]
| Option | Description |
|---|---|
| -f, —from-code | Convert characters from encoding |
| -t, —to-code | Convert characters to encoding |
Example 1: Convert a file’s encoding from iso-8859-1 to UTF-8 and save it to New_storks.srt
$ iconv -f iso-8859-1 -t utf-8 storks.srt > New_storks.srt
Here’s the New_storks.srt is UTF-8 encoded.
Example 2: Convert a file’s encoding from cp1256 to UTF-8 and save it to output.txt
$ iconv -f cp1256 -t utf-8 input.txt > output.txt
Here’s the output.txt is UTF-8 encoded.
Example 3: Convert a file’s encoding from ASCII to UTF-8 and save it to output.txt
$ iconv -f ascii -t utf-8 input.txt > output.txt
Here’s the output.txt is UTF-8 encoded.
Example 4: Convert a file’s encoding from UTF-8 to ASCII
Hints: 1. UTF-8 can contain characters that can't be encoded with ASCII, the iconv will generate the error message "illegal input sequence at position X" unless you tell it to strip all non-ASCII characters using the -c option. 2. With using iconv with the -c option, you could loose some characters from your text file.
$ iconv -c -f utf-8 -t ascii input.txt > output.txt
Finally, to list all the coded character sets known run -l option with iconv as follow:
Here’s the output of the above command:
The following list contain all the coded character sets known. This does not necessarily mean that all combinations of these names can be used for the FROM and TO command line parameters. One coded character set can be listed with several different names (aliases). 437, 500, 500V1, 850, 851, 852, 855, 856, 857, 860, 861, 862, 863, 864, 865, 866, 866NAV, 869, 874, 904, 1026, 1046, 1047, 8859_1, 8859_2, 8859_3, 8859_4, 8859_5, 8859_6, 8859_7, 8859_8, 8859_9, 10646-1:1993, 10646-1:1993/UCS4, ANSI_X3.4-1968, ANSI_X3.4-1986, ANSI_X3.4, ANSI_X3.110-1983, ANSI_X3.110, ARABIC, ARABIC7, ARMSCII-8, ASCII, ASMO-708, ASMO_449, BALTIC, BIG-5, BIG-FIVE, BIG5-HKSCS, BIG5, BIG5HKSCS, BIGFIVE, BRF, BS_4730, CA, CN-BIG5, CN-GB, CN, CP-AR, CP-GR, CP-HU, CP037, CP038, CP273, CP274, CP275, CP278, CP280, CP281, CP282, CP284, CP285, CP290, CP297, CP367, CP420, CP423, CP424, CP437, CP500, CP737, CP770, CP771, CP772, CP773, CP774, CP775, CP803, CP813, CP819, CP850, CP851, CP852, CP855, CP856, CP857, CP860, CP861, CP862, CP863, CP864, CP865, CP866, CP866NAV, CP868, CP869, CP870, CP871, CP874, CP875, CP880, CP891, CP901, CP902, CP903, CP904, CP905, CP912, CP915, CP916, CP918, CP920, CP921, CP922, CP930, CP932, CP933, CP935, CP936, CP937, CP939, CP949, CP950, CP1004, CP1008, CP1025, CP1026, CP1046, CP1047, CP1070, CP1079, .
Finally, I hope this article is useful for you.