- Цикл по содержимому файла в Bash
- Ответ 1
- Ответ 2
- Ответ 3
- Ответ 4
- Чтение из файла с разделителями
- Чтение вывода другой команды с использованием подстановки процесса
- Чтение из ввода с разделителями NULL, например , find . -print0
- Чтение из более чем одного файла за раз
- Чтение всего файла в массив (версии Bash до 4)
- Чтение всего файла в массив (версии Bash 4x и новее)
- Команда Ls в Linux (список файлов и каталогов)
- Как использовать команду ls
- Формат длинных списков
- Показать скрытые файлы
- Сортировка вывода
- Рекурсивный список подкаталогов
- Выводы
- Просмотр содержимого файлов в командной строке Linux
- Команда cat
- Команда nl
- Команда less
- Команда more
- Команда head
- Команда tail
- Заключение
Цикл по содержимому файла в Bash
Как мне в цикле перебрать каждую строку текстового файла с помощью Bash ?
Я использую следующий скрипт:
echo «Start!»
for p in (peptides.txt)
do
echo «$
«
done
Я получаю такой вывод на экране:
Start!
./runPep.sh: line 3: синтаксическая ошибка – неожиданная лексема «(‘
./runPep.sh: line 3: «for p in (peptides.txt)’
Ответ 1
Один из способов сделать это:
while read p; do
echo «$p»
done
Данный способ имеет побочные эффекты, заключающиеся в обрезке ведущих пробелов, интерпретации последовательностей обратной косой черты и пропуске последней строки, если в ней отсутствует завершающий перевод строки. Если это не приемл е мо, можно сделать следующее:
while IFS=»» read -r p || [ -n «$p» ]
do
printf ‘%s\n’ «$p»
done < peptides.txt
В исключительных ситуациях, если содержимое считывается из стандартного ввода , можно открыть файл, используя другой дескриптор файла:
while read -u 10 p; do
.
done 10
Здесь 10 — это просто произвольное число (отличное от 0, 1, 2).
Ответ 2
Вариант 1: используя цикл while — по одной строке за раз: перенаправление ввода:
#!/bin/bash
filename=’peptides.txt’
echo Start
while read p; do
echo $p
done < $filename
Вариант 2: цикл while — открыть файл, прочитать из файлового дескриптора (в данном случае файлового дескриптора №4).
#!/bin/bash
filename=’peptides.txt’
exec 4
echo Start
while read -u4 p ; do
echo $p
done
Ответ 3
Еще один способ выполнить данную операцию :
for word in $(cat peptides.txt); do echo $word; done
Этот формат позволяет поместить все это в одну командную строку. Изменяя часть «echo $word», вы можете выполнить несколько команд, разделенных точкой с запятой. В следующем примере содержимое файла используется в качестве аргументов двух других сценариев:
for word in $(cat peptides.txt); do cmd_a.sh $word; cmd_b.py $word; done
Или, если вы собираетесь использовать это как редактор потока (используя sed), можно выгрузить вывод в другой файл следующим образом:
for word in $(cat peptides.txt); do cmd_a.sh $word; cmd_b.py $word; done > outfile.txt
Если у вас есть пробелы, которые вы не хотите разделять словами/строками, это становится немного сложнее, но та же команда по-прежнему работает следующим образом:
OLDIFS=$IFS; IFS=$’\n’; for line in $(cat peptides.txt); do cmd_a.sh $line; cmd_b.py $line; done > outfile.txt; IFS=$OLDIFS
Этот пример указывает оболочке разделять символы по строкам.
Ответ 4
Еще несколько возможных решений:
Чтение из файла с разделителями
# ‘:’ является разделителем, и на каждой строке в файле име ю тся три поля
# IFS, установленный ниже, ограничен контекстом `read`, он не влияет на любой другой код
while IFS=: read -r field1 field2 field3; do
# обработка полей
# если строка содержит менее трех полей, то недостающие поля будут установлены в пустую строку
# если строка имеет более трех полей, `field3` получит все значения, включая третье поле плюс разделитель(и)
done < input.txt
Чтение вывода другой команды с использованием подстановки процесса
while read -r line; do
# обработка строки
done < <(command . )
Этот подход лучше, чем command . | while read -r line; do . потому, что цикл while здесь выполняется в текущей оболочке, а не в подоболочке.
Чтение из ввода с разделителями NULL, например , find . -print0
Чтение из более чем одного файла за раз
while read -u 3 -r line1 && read -u 4 -r line2; do
# обработка строк
# обратите внимание, что цикл завершится, когда мы достигнем EOF в любом из файлов
done 3 < input1.txt 4< input2.txt
Для совместимости с POSIX каждый вызов будет выглядеть примерно так read -r X
Чтение всего файла в массив (версии Bash до 4)
while read -r line; do
my_array+=(«$line»)
done < my_file
Если файл заканчивается неполной строкой (в конце отсутствует новая строка), то:
while read -r line || [[ $line ]]; do
my_array+=(«$line»)
done < my_file
Чтение всего файла в массив (версии Bash 4x и новее)
readarray -t my_array < my_file
или же
mapfile -t my_array < my_file
А потом :
for line in «$»; do
# обработка строк
done
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
Команда Ls в Linux (список файлов и каталогов)
ls — одна из основных команд, которую должен знать любой пользователь Linux.
Команда ls выводит список файлов и каталогов в файловой системе и показывает подробную информацию о них. Это часть пакета основных утилит GNU, который установлен во всех дистрибутивах Linux.
Эта статья покажет вам, как использовать команду ls, на практических примерах и подробных объяснениях наиболее распространенных параметров ls.
Как использовать команду ls
Синтаксис команды ls следующий:
При использовании без параметров и аргументов ls отображает список имен всех файлов в текущем рабочем каталоге :
Файлы перечислены в алфавитном порядке в столько столбцов, сколько может поместиться на вашем терминале:
cache db empty games lib local lock log mail opt run spool tmp Чтобы вывести список файлов в определенном каталоге, передайте путь к каталогу в качестве аргумента команде ls . Например, чтобы отобразить содержимое каталога /etc , введите:
Вы также можете передать несколько каталогов и файлов, разделенных пробелом:
Если пользователь, с которым вы вошли в систему, не имеет прав на чтение каталога, вы получите сообщение о том, что ls не может открыть каталог:
ls: cannot open directory '/root': Permission denied У команды ls есть несколько опций. В следующих разделах мы рассмотрим наиболее часто используемые варианты.
Формат длинных списков
По умолчанию вывод команды ls показывает только имена файлов и каталогов, что не очень информативно.
Параметр -l (нижний регистр L) указывает ls печатать файлы в формате длинного списка.
Когда используется формат длинного списка, вы можете увидеть следующую информацию о файле:
- Тип файла.
- Права доступа к файлу.
- Количество жестких ссылок на файл.
- Владелец файла.
- Файловая группа.
- Размер файла.
- Дата и время.
- Имя файла.
-rw-r--r-- 1 root root 337 Oct 4 11:31 /etc/hosts Давайте объясним самые важные столбцы вывода.
Первый символ показывает тип файла. В этом примере первый символ — , что указывает на обычный файл. Значения для других типов файлов следующие:
- — — Обычный файл.
- b — Заблокировать специальный файл.
- c — Символьный специальный файл.
- d — Справочник.
- l — символическая ссылка.
- n — Сетевой файл.
- p — ФИФО.
- s — Розетка.
Следующие девять символов показывают права доступа к файлу. Первые три символа предназначены для пользователя, следующие три — для группы, а последние три — для остальных. Вы можете изменить права доступа к файлу с помощью команды chmod . Символ разрешения может принимать следующие значения:
- r — Разрешение на чтение файла.
- w — Разрешение на запись в файл.
- x — Разрешение на выполнение файла.
- s — бит setgid .
- t — sticky бит.
В нашем примере rw-r—r— означает, что пользователь может читать и записывать файл, а группа и другие пользователи могут только читать файл. Цифра 1 после символов разрешения — это количество жестких ссылок на этот файл.
Следующие два поля root root показывают владельца файла и группу, за которыми следует размер файла ( 337 ), показанный в байтах. Используйте параметр -h если вы хотите печатать размеры в удобочитаемом формате. Вы можете изменить владельца файла с помощью команды chown .
Oct 4 11:31 — дата и время последнего изменения файла.
Последний столбец — это имя файла.
Показать скрытые файлы
По умолчанию команда ls не отображает скрытые файлы. В Linux скрытый файл — это любой файл, который начинается с точки ( . ).
Чтобы отобразить все файлы, включая скрытые, используйте параметр -a :
drwxr-x--- 10 linuxize linuxize 4096 Feb 12 16:28 . drwxr-xr-x 18 linuxize linuxize 4096 Dec 26 09:21 .. -rw------- 1 linuxize linuxize 1630 Nov 18 2017 .bash_history drwxr-xr-x 2 linuxize linuxize 4096 Jul 20 2018 bin drwxr-xr-x 2 linuxize linuxize 4096 Jul 20 2018 Desktop drwxr-xr-x 4 linuxize linuxize 4096 Dec 12 2017 .npm drwx------ 2 linuxize linuxize 4096 Mar 4 2018 .ssh Сортировка вывода
Как мы уже упоминали, по умолчанию команда ls перечисляет файлы в алфавитном порядке.
Параметр —sort позволяет сортировать вывод по расширению, размеру, времени и версии:
- —sort=extension (или -X ) — отсортировать в алфавитном порядке по расширению.
- —sort=size (или -S ) — сортировать по размеру файла.
- —sort=time (или -t ) — сортировать по времени модификации.
- —sort=version (или -v ) — естественный вид номеров версий.
Если вы хотите получить результаты в обратном порядке сортировки, используйте параметр -r .
Например, чтобы отсортировать файлы в каталоге /var по времени модификации в обратном порядке, вы должны использовать:
Стоит отметить, что команда ls не показывает общее пространство, занятое содержимым каталога. Чтобы узнать размер каталога , используйте команду du .
Рекурсивный список подкаталогов
Параметр -R указывает команде ls рекурсивно отображать содержимое подкаталогов:
Выводы
Команда ls отображает информацию о файлах и каталогах.
Для получения дополнительной информации о ls посетите страницу GNU Coreutils или введите man ls в свой терминал.
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Просмотр содержимого файлов в командной строке Linux

Рассмотрим несколько команд, которые используются для просмотра содержимого текстовых файлов в командной строке Linux.
Команда cat
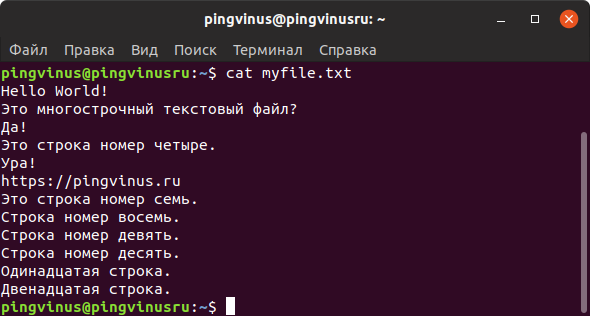
Команда cat выводит содержимое файла, который передается ей в качестве аргумента.
Это самый простой и наиболее часто используемый способ для вывода содержимого текстовых файлов. Но выводить большие файлы через cat не всегда удобно.
Команда nl
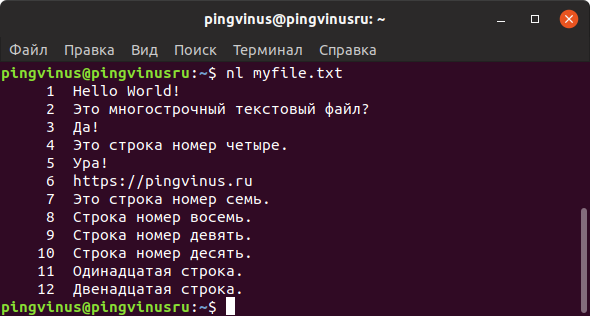
Команда nl действует аналогично команде cat , но выводит еще и номера строк в столбце слева.
Команду nl удобно применять для просмотра программного кода или поиска строк в файлах конфигурации.
Команда less
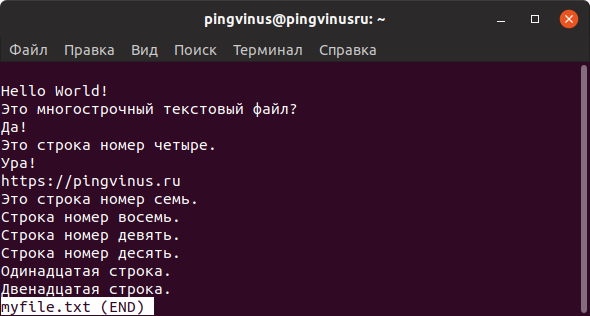
Утилита less выводит содержимое файла, но отображает его только в рамках текущего окна в режиме просмотра.
Вы можете прокручивать текст файла клавишами стрелок или перелистывать страницы клавишами w и z .
Для поиска текста внутри файла нажмите / .
Для просмотра списка доступных горячих клавиш нажмите h
Чтобы выйти из режима просмотра используется клавиша q .
Очень удобно, что после выхода окно терминала остается чистым и не содержит текст файла.
Команда more
Команда more очень похожа на команду less . Она также выводит файл в терминале в режиме просмотра, но имеет некоторые отличия от команды less.
Например, less в конце файла выводит сообщение (END) (или EOF — End Of File) и ожидает нажатия клавиши q чтобы закрыть режим просмотра, а more по достижении конца файла сразу возвращает управление в терминал.
Также more после своей работы оставляет текст файла в терминале, а less работает «чисто» и не сохраняет текст в терминале.
Команда head
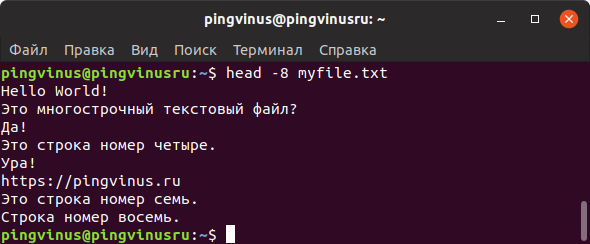
Команда head выводит на экран только первые 10 строк файла.
Используя опцию -n можно задать количество строк, которое нужно вывести. Например, чтобы вывести 15 строк используется команда:
Вместо -n можно просто использовать знак минус — , за которым сразу указывается количество строк.
Команда tail
Команда tail аналогична команде head , но выводит последние 10 строк файла.
Заключение
Команды, которые мы рассмотрели, имеют дополнительные возможности и области применения. Для получения справки по каждой команде можно воспользоваться Man-страницами.
man cat man nl man less man more man head man tail