Total size of the contents of all the files in a directory [closed]
Closed. This question does not meet Stack Overflow guidelines. It is not currently accepting answers.
This question does not appear to be about a specific programming problem, a software algorithm, or software tools primarily used by programmers. If you believe the question would be on-topic on another Stack Exchange site, you can leave a comment to explain where the question may be able to be answered.
When I use ls or du , I get the amount of disk space each file is occupying. I need the sum total of all the data in files and subdirectories I would get if I opened each file and counted the bytes. Bonus points if I can get this without opening each file and counting.
ls actually shows the number of bytes in each file, not the amount of disk space. Is this sufficient for your needs?
Note that du can’t be used to answer to this question. It shows the amount of disk space the directory occupy on the disk (the files’ data plus the size of auxiliary file system meta-information). The du output can be even smaller than the total size of all files. This may happen if file system can store data compressed on the disk or if hard links are used. Correct answers are based on ls and find . See answers by Nelson and by bytepan here, or this answer: unix.stackexchange.com/a/471061/152606
12 Answers 12
If you want the ‘apparent size’ (that is the number of bytes in each file), not size taken up by files on the disk, use the -b or —bytes option (if you got a Linux system with GNU coreutils):
Is there an easy way to show the “apparent size” in human-readable format? When using du -shb (as suggested by this answer), the -b setting seems to override the -h setting.
@Arkady I have tried your solution on CentOS and Ubuntu, and there is a small error. You want «du -sbh». The «-h» flag must come last.
Optionally, add the h option for more user-friendly output:
@lynxoid: You can install the GNU version with brew: brew install coreutils . It will be available as the command gdu .
Does not work. ls -> file.gz hardlink-to-file.gz . stat -c %s file.gz -> 9657212 . stat -c %s hardlink-to-file.gz -> 9657212 . du -sb -> 9661308 . It’s definitely not the total size of the content but the size the directory takes up on the disk.
This is simple and does not work. It prints the space that directory takes up on the disk, not the total size of the content that could be calculated by opening each file and counting the bytes.
ls -lAR | grep -v '^d' | awk ' END ' grep -v ‘^d’ will exclude the directories.
Isolated to a specific file type (in this case, PNG) and expressed in MB for more readability: ls -lR | grep ‘.png$’ | awk ‘
It is a correct answer. Unlike du this solution really counts the total size of all the data in files as if they were opened one by one and their bytes were counted. But yes, adding the -A parameter is required to count hidden files as well.
stat’s «%s» format gives you the actual number of bytes in a file.
find . -type f | xargs stat --format=%s | awk ' END ' Preferably use «find . -type f -print0 | xargs -0 . » to avoid problems with certain file names (containing spaces etc).
(Note that stat works with sparse files, reporting the large nominal size of the file and not the smaller blocks used on disk like du reports.)
Unlike many other answers here which erroneously use the du utility, this answer is correct. It is very similar to answer here: unix.stackexchange.com/a/471061/152606. But I would use ! -type d instead of -type f to count symlinks as well (the size of symlink itself (usually few bytes), not the size of the file it points to).
If you use busybox’s «du» in emebedded system, you can not get a exact bytes with du, only Kbytes you can get.
BusyBox v1.4.1 (2007-11-30 20:37:49 EST) multi-call binary Usage: du [-aHLdclsxhmk] [FILE]. Summarize disk space used for each FILE and/or directory. Disk space is printed in units of 1024 bytes. Options: -a Show sizes of files in addition to directories -H Follow symbolic links that are FILE command line args -L Follow all symbolic links encountered -d N Limit output to directories (and files with -a) of depth < N -c Output a grand total -l Count sizes many times if hard linked -s Display only a total for each argument -x Skip directories on different filesystems -h Print sizes in human readable format (e.g., 1K 243M 2G ) -m Print sizes in megabytes -k Print sizes in kilobytes(default) c:> dir /s c:\directory\you\want
and the penultimate line will tell you how many bytes the files take up.
I know this reads all files and directories, but works faster in some situations.
When a folder is created, many Linux filesystems allocate 4096 bytes to store some metadata about the directory itself. This space is increased by a multiple of 4096 bytes as the directory grows.
du command (with or without -b option) take in count this space, as you can see typing:
you will have a result of 4096 bytes for an empty dir. So, if you put 2 files of 10000 bytes inside the dir, the total amount given by du -sb would be 24096 bytes.
If you read carefully the question, this is not what asked. The questioner asked:
the sum total of all the data in files and subdirectories I would get if I opened each file and counted the bytes
that in the example above should be 20000 bytes, not 24096.
So, the correct answer IMHO could be a blend of Nelson answer and hlovdal suggestion to handle filenames containing spaces:
find . -type f -print0 | xargs -0 stat --format=%s | awk ' END ' There are at least three ways to get the "sum total of all the data in files and subdirectories" in bytes that work in both Linux/Unix and Git Bash for Windows, listed below in order from fastest to slowest on average. For your reference, they were executed at the root of a fairly deep file system ( docroot in a Magento 2 Enterprise installation comprising 71,158 files in 30,027 directories).
$ time find -type f -printf '%s\n' | awk '< total += $1 >; END < print total" bytes" >' 748660546 bytes real 0m0.221s user 0m0.068s sys 0m0.160s $ time echo `find -type f -print0 | xargs -0 stat --format=%s | awk ' END '` bytes 748660546 bytes real 0m0.256s user 0m0.164s sys 0m0.196s $ time echo `find -type f -exec du -bc <> + | grep -P "\ttotal$" | cut -f1 | awk '< total += $1 >; END < print total >'` bytes 748660546 bytes real 0m0.553s user 0m0.308s sys 0m0.416s These two also work, but they rely on commands that don't exist on Git Bash for Windows:
$ time echo `find -type f -printf "%s + " | dc -e0 -f- -ep` bytes 748660546 bytes real 0m0.233s user 0m0.116s sys 0m0.176s $ time echo `find -type f -printf '%s\n' | paste -sd+ | bc` bytes 748660546 bytes real 0m0.242s user 0m0.104s sys 0m0.152s If you only want the total for the current directory, then add -maxdepth 1 to find .
Note that some of the suggested solutions don't return accurate results, so I would stick with the solutions above instead.
$ du -sbh 832M . $ ls -lR | grep -v '^d' | awk ' END ' Total: 583772525 $ find . -type f | xargs stat --format=%s | awk ' END ' xargs: unmatched single quote; by default quotes are special to xargs unless you use the -0 option 4390471 $ ls -l| grep -v '^d'| awk ' END ' Total 968133 Regarding Git Bash for Windows, — in case of Cygwin, dc is part of bc package, so to get dc it is need to install bc .
du is handy, but find is useful in case if you want to calculate the size of some files only (for example, using filter by extension). Also note that find themselves can print the size of each file in bytes. To calculate a total size we can connect dc command in the following manner:
find . -type f -printf "%s + " | dc -e0 -f- -ep Here find generates sequence of commands for dc like 123 + 456 + 11 + . Although, the completed program should be like 0 123 + 456 + 11 + p (remember postfix notation).
So, to get the completed program we need to put 0 on the stack before executing the sequence from stdin, and print the top number after executing (the p command at the end). We achieve it via dc options:
- -e0 is just shortcut for -e '0' that puts 0 on the stack,
- -f- is for read and execute commands from stdin (that generated by find here),
- -ep is for print the result ( -e 'p' ).
To print the size in MiB like 284.06 MiB we can use -e '2 k 1024 / 1024 / n [ MiB] p' in point 3 instead (most spaces are optional).
How to Display File Size in Human Readable Format (KB, MB, GB) in Linux Terminal
Quick tip to display file size in Linux using the ls command.
You probably already know that you can use ls command with long listing option -l to show file size in Linux.
But unfortunately, the long listing shows the file size in blocks and that's not of much use to us humans.
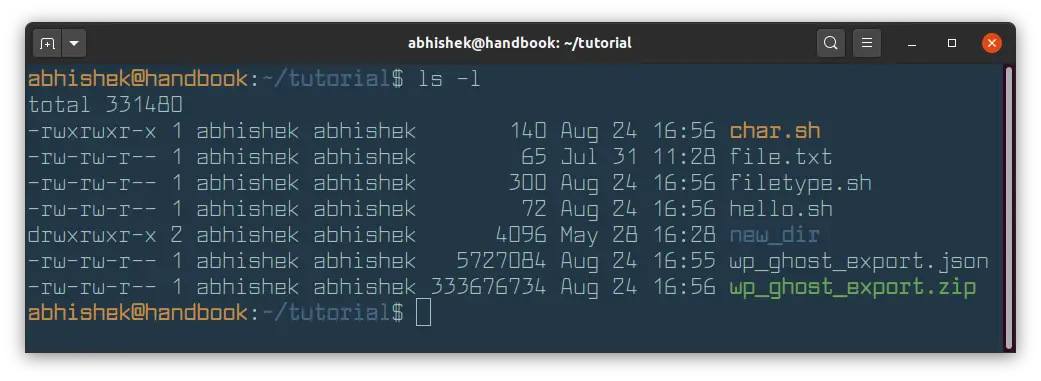
The good thing is that you can combine the option -l with -h to show the file size in a human-readable format.
As you can see, it is better to display file size in a human-readable format.
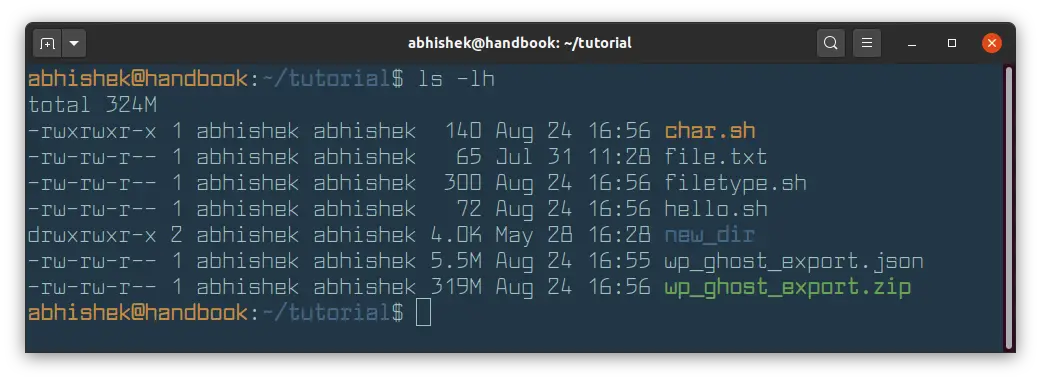
As you can see, file sizes are now displayed in K (for KB), M for (MB). If the file size is in Bytes, it is not displayed with any suffix. In the above example, char.sh is 140 Bytes in size.
Did you notice the size of new_dir directory? It is 4 KB. If you use ls -lh command on directories, it always shows the size of directory as 4.0 K.
By default, the block size in most Linux system is 4096 Bytes or 4 KB. A directory in Linux is simply a file with the information about the memory location of all the files in it.
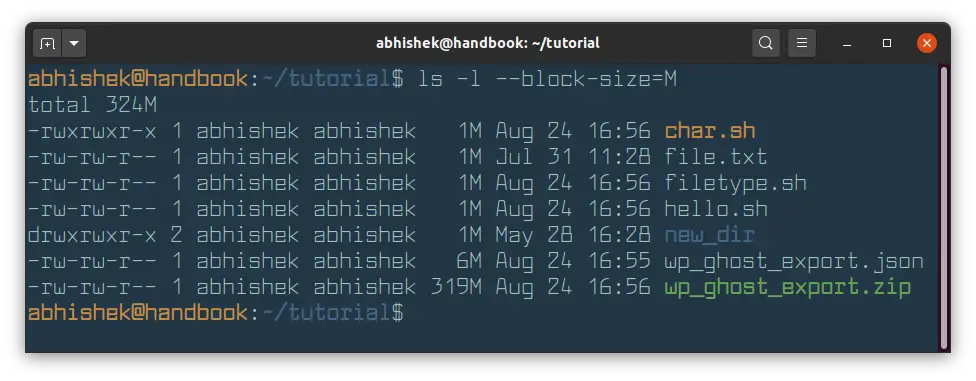
You can force ls command to display file size in MB with the --block-size flag.
The problem with this approach is that all the files with a size of less than 1 MB will also be displayed with file size of 1 MB.
The ls command also has -s option to display size. You should combine with -h to show the file size in human readable form.
[email protected]:~/tutorial$ ls -sh total 324M 4.0K char.sh 4.0K hello.sh 319M wp_ghost_export.zip 4.0K file.txt 4.0K new_dir 4.0K filetype.sh 5.5M wp_ghost_export.jsonYou can use the -S option of the ls command to sort files by size. This is also helpful in knowing which files take the most space on your system.
You can also use the stat command in Linux to check the file size.
I hope you find this quick tip helpful in seeing the file size in Linux.
what is the most reliable command to find actual size of a file linux
Recently I tried to find out the size of a file using various command and it showed huge differences. ls -ltr showed its size around 34GB (bytes rounded off by me ) while du -sh filename showed it to be around 11GB. while stat command showed the same to be around 34GB . Any idea which is the most reliable command to find actual size of the file ? There was some copy operation performed on it and we are unsure of if this was appropriately done as after a certain time source file from where copy was being performed was removed by a job of ours.
I guess that is a sparse file, du tells its current disk usage, ls its declared size (that might be reached if you modify the file decreasing the runs of blank blocks)
@l'L'l: Why so unusual? $ truncate -s 10T foo; ls -l foo; du -sh foo will give 10995116277760 and 0 .
@rodrigo, Actually, what I meant is that it would be unusual if the file in question was not sparse, or there was major discrepancy between ls -lsh and du -h; du -bh . The example you've shown gives an apparent file size and an actual file size, so of course it's going to be completely different.
3 Answers 3
There is no inaccuracy or reliability issue here, you're just comparing two different numbers: logical size vs physical size.

ls shows the gray+green areas, the logical length of the file. du (without --apparent-size ) shows only the green areas, since those are the ones that take up space.
You can create a sparse file with dd count=0 bs=1M seek=100 of=myfile .
ls shows 100MiB because that's how long the file is:
$ ls -lh myfile -rw-r----- 1 me me 100M Jul 15 10:57 myfile du shows 0, because that's how much data it's allocated:
Just note that this does not really answer the literal question posted, although this is likely what the user needed to know
@rodrigo On which compressing file systems does du show post-compression blocks? On btrfs it shows pre-compression blocks.
@thatotherguy: I'll do a few experiments if I got the time. But from the top of my head, I think that ZFS and maybe also ext4 did that.
will give you a long format listing (needed to actually see the file size) and round file sizes up to the nearest MiB .
If you want MB (10^6 bytes) rather than MiB (2^20 bytes) units, use --block-size=MB instead.
If you don't want the M suffix attached to the file size, you can use something like --block-size=1M . Thanks Stéphane Chazelas for suggesting this.
This is described in the man page for ls ; man ls and search for SIZE . It allows for units other than MB/MiB as well, and from the looks of it (I didn't try that) arbitrary block sizes as well (so you could see the file size as number of 412-byte blocks, if you want to).
Note that the --block-size parameter is a GNU extension on top of the Open Group's ls , so this may not work if you don't have a GNU userland (which most Linux installations do). The ls from GNU coreutils 8.5 does support --block-size as described above.