- Concatenate N number of csv files to one single csv file
- 3 Answers 3
- How to Merge multiple CSV Files in Linux Mint
- Example 1: Append multiple CSV files in bash with(out) header
- Example 2: Merge CSV files without new line in Linux terminal
- Example 3: Concatenate two CSV files in Linux with awk (including headers)
- How to join two CSV files?
- 9 Answers 9
- Concatenating / Merging .csv on the Linux or Mac OS Terminal
- CSV only keep first header / skip headers
Concatenate N number of csv files to one single csv file
I have a requirement to build a shell script which would concatenate all available CSV files into one. All these CSV files have a similar structure (i.e same headers and number of columns) and these files have a common prefix GFP . for example : One day I might have the following files ,
GFP_20210609.csv GFP_20210610.csv or sometimes I might have many such files. The problem here is I am not sure how many such files would appear in a day (assuming not greater than 5 CSV files per day). Am quite a beginner to shell scripting. Any help would be highly appreciated.
sed 1d GFP_20210610.csv > GFP_20210610_NO_HEADER.csv cat GFP_20210609.csv GFP_20210610_NO_HEADER.csv > GFP_FINAL.csv 3 Answers 3
awk 'NR==1||FNR>1' GFP*.csv > output.csv This will print all lines of each file starting from the second line ( FNR>1 means per-file line-counter larger than one) to suppress repeating headers, but be sure to print the very first line encountered ( NR==1 ) which is the header line of the first file.
The output is then redirected to a file output.csv .
The syntax makes use of the fact that awk will print the current line if a condition found outside of a rule block ( < . >) is true. In this case, we can omit the rule blocks altogether since we don’t actually want to edit, but only filter, the input files.
First of all, we’ll create our header file once and we’ll leave it in the same folder as the rest of csv files
head -qn 1 GFP_20210609.csv > common.header common_header.csv contains the 1st line of any csv file you choose (based on what you’ve said, all csv files have the same header). You should build this file once and leave it for further use in the same directory.
head command outputs first n lines of a text file, which is «1» in our header file case.
tail command outputs last n lines of a text file. Starting at «1» we will be ignoring first line on all csv files, as we want to avoid header repetition.
Extra -q (quiet) parameter in both head and tail prevents extra output information we don’t want in final file.
Next line is source code for your script:
cat common.header > FINAL.csv && tail -qn 1 GFP_*.csv >> FINAL.csv Both commands cat and tail are jointed with a && which means that tail will run only if cat command succeed.
(*) Note: tail -qn 1. could also be written as tail -q -n 1. and is the same thing.
How to Merge multiple CSV Files in Linux Mint
In this short tutorial, I’ll show you several ways to merge multiple files with bash in Linux Mint. The examples will cover merging with and without the headers.
It’s assumed that CSV files are identical if not you can check Python solution: How to merge multiple CSV files with Python
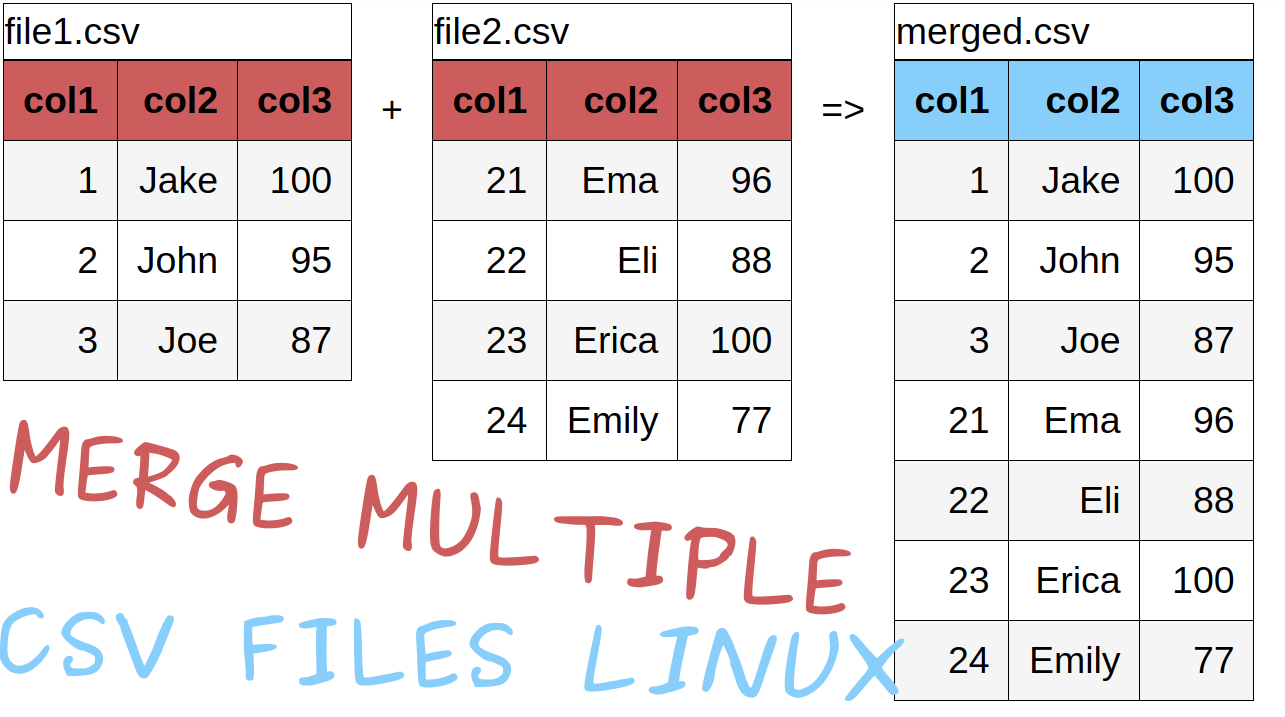
Example 1: Append multiple CSV files in bash with(out) header
The first example will merge multiple CSV or text files by combining head and tail commands in Linux. If the files don’t have headers only head is enough:
In case of headers — head can get the header from one file and the values to be collected with tail
head -n 1 file1.csv > merged.out && tail -n+2 -q *.csv >> merged.out Note 1: if the last line in the file doesn’t have new line separator this way will produce results:
In this case you can check the second example.
Note 2: parameter -q is used to remove extra text for command tail.
Example 2: Merge CSV files without new line in Linux terminal
This example shows an improved version of the first one which solves the problem of missing a new line at the end of each CSV file. This is the short version:
head -n 1 1.csv > combined.out for f in *.csv; do tail -n 2 "$f"; printf "\n"; done >> combined.out and prettified shell version will be:
for f in *.csv; do tail -n 2 "$f"; printf "\n"; done >> merged.out col1,col2,col3
1,Jake,100
2,John,95
3,Joe,87
21,Ema,96
22,Eli,88
23,Erica,100
24,Emily,77
Example 3: Concatenate two CSV files in Linux with awk (including headers)
Third example shows how to merge two and more files by using the command awk . If all files have headers the command will take only 1 header from one file. The rest of the data will be appended to the end of the file. The command is:
awk 'FNR==1 && NR!=1' *.csv >> merged.csv col1,col2,col3
1,Jake,100
2,John,95
3,Joe,87
21,Ema,96
22,Eli,88
23,Erica,100
24,Emily,77
where the condition FNR==1 && NR!=1 reads the first line of the first file and skips the first line for the rest.
If you don’t care for the headers than you can change it to:
col1,col2,col3
1,Jake,100
2,John,95
3,Joe,87
col1,col2,col3
21,Ema,96
22,Eli,88
23,Erica,100
24,Emily,77
By using SoftHints — Python, Linux, Pandas , you agree to our Cookie Policy.
How to join two CSV files?
Suppose you have one CSV file with 2 fields: ID and email. You have another file with 2 fields: email and name. How can you produce a file with all three fields joined on email?
A little more detail on the join (i.e., inner, outer, left). Is the email list on the 1st CSV identical to the second list? Or does one contain more?
9 Answers 9
You must sort both lists on email alphabetically, then join. Given that the email field the 2nd field of file1 and the 1st field of file2:
sort -t , -k 2,2 file1.csv > sort1.csv sort -t , -k 1,1 file2.csv > sort2.csv join -t , -1 2 -2 1 sort1.csv sort2.csv > sort3.csv -t , : ',' is the field separator -k 2,2 : character sort on 2nd field -k 1,1 : character sort on 1st field -1 2 : file 1, 2nd field -2 1 : file 2, 1st field > : output to file
sorted by email alphabetically.
Note that if any email is missing from either file it will be omitted from the results.
This won’t work if the CSV is mixed quoted/unqoted, if the ID contains a comma. Use this solution only for one-time processing where you check the result. But I recommend not using it for a production-level script.
csvjoin -c email id_email.csv email_name.csv csvjoin -c 2,1 id_email.csv email_name.csv Perhaps it is overkill, but you could import into a database (e.g. OpenOffice Base) as two kinds of tables and define a report that is the desired output.
If the CSV import is a problem, then a spreadsheet program (e.g. OpenOffice Calc) can do the import. The result can then easily be transferred to the database.
As a future reference you might want to start playing around with AWK. It’s a very simple little scripting language that exists in some form on every *nix system and its sole mission is life is the manipulation of standard delimited textual databases. With a few lines of throwaway script you can do some very useful things. The language is small and elegant and has a better utility/complexity ratio than anything else I am aware of.
awk doesn’t handle quoting and escaping (e.g. dealing with ,s in a ,-separated CSV file) as far as I know. If you need that, using a dedicated CSV handling library is easier; they exist for many languages.
package main import ( "flag" "os" "github.com/chrislusf/gleam" "github.com/chrislusf/gleam/source/csv" ) var ( aFile = flag.String("a", "a.csv", "first csv file with 2 fields, the first one being the key") bFile = flag.String("b", "b.csv", "second csv file with 2 fields, the first one being the key") ) func main() It takes CSV files as SQL tables and then allows SQL queries, resulting in another CSV or JSON file.
For your case, you would just call:
crunch -in tableA.csv tableB.csv -out output.csv \ "SELECT tableA.id, tableA.email, tableB.name FROM tableA LEFT JOIN tableB USING (email)" The tool needs Java 8 or later.
- You really get CSV support, not just «let’s assume the data is correct».
- You can join on multiple keys.
- Easier to use and understand than join -based solutions.
- You can combine more than 2 CSV files.
- You can join by SQL expressions — the values don’t have to be the same.
Disclaimer: I wrote that tool. It used to be in disarray after Google Code was closed, but I revived it and added new features as I use it.
You could read the CSV file with a spreadsheet program like LibreOffice and use VLOOKUP() macro to search for the name in second file.
File extension xlsx implies Microsoft Excel and I think VLOOKUP does as well. This question is tagged with Linux. Is Microsoft Excel available for Linux?
In Bash 5.0.3 with GNU Coreutils 8.30 and building off of hyperslug’s answer:
If you have unsorted CSV files with duplicate lines and don’t want to omit data due to a missing field in a line of either file1.csv or file2.csv , then you can do the following:
Sort file 1 by field 2 and sort file 2 by field 1:
( head -n1 file1.csv && tail -n+2 file1.csv | sort -t, -k2,2 ) > sort1.csv ( head -n1 file2.csv && tail -n+2 file2.csv | sort -t, -k1,1 ) > sort2.csv Expanding on hyperslug’s parameters:
-k 2,2 : character sort starting and stopping on 2nd field -k 1,1 : character sort starting and stopping on 1st field head -n1 : read first line tail -n+1: : read all but first line ( ) : subshell > : output to file I had to do head and tail within the subshell ( ) in order to preserve the first header line of the CSV file when sorting by a given field.
join -t , -a1 -a2 -1 2 -2 1 -o auto sort1.csv sort2.csv > sort3.csv Expanding on hyperslug’s parameters:
-t , : ',' is the field separator -a1 : Do not omit lines from file 1 if no match in file 2 found -a2 : Do not omit lines from file 2 if no match in file 1 found. -1 2 : file 1, 2nd field -2 1 : file 2, 1st field -o auto : Auto format: includes extra commas indicating unmatched fields > : output to file Here is an example file1.csv , file2.csv , and the resulting sort3.csv :
ID,email 02,bob@test.com 03,frank@test.com 05,sally@test.com 07,raul@prueba.eu 11,zulu@xi.com email,name tim@test.com,Timothy Brown bob@test.com,Robert Green raul@prueba.eu,Raul Vasquez carol@google.com,Carol Lindsey email,ID,name bob@test.com,02,Robert Green carol@google.com,,Carol Lindsey frank@test.com,03, raul@prueba.eu,07,Raul Vasquez sally@test.com,05, tim@test.com,,Timothy Brown zulu@xi.com,11, You can see Timothy Brown and Carol Lindsey lack IDs but are still included in the joined CSV file (with their names and emails in the correct fields).
Concatenating / Merging .csv on the Linux or Mac OS Terminal
For data analysis .csv files with houndreds of thousands of data sets still play a role. You might think:
Think again! CSV files, comma separated values (that also can be separated by tabs or kind of any character you want, but never mind that) are still used a lot on in data analysis as a raw input format.
Thanks to a former colleague I was tasked with merging 1.5 million records that were split over several files into a big CSV file. Of course they all contained neat little header portions like so:
# file 1 Name,Email Sirius,s.black@hogwarts.com Remus,r.lupin@hogwarts.com Whistler,grumpy_redneck@vampirekillerelite.net Salome,givemethehead@dungeon.com # file 2 Name,Email Galadriel,AwesomeElvenQueen@loth.lorien Saruman,WhiteHand69@dark.tower So the simple way would be to just cat file* > output_simple.csv , right? That would repeat the row that contains the headers though, which is no good.
CSV only keep first header / skip headers
To concatenate without repeating the headers, we can craft a simple (if that term ever applies to bash) script:
#!/bin/bash if [[ $# -eq 1 ]] ; then echo 'usage:' echo './merge.sh pattern output.csv' exit 1 fi output_file=$2 i=0 files=$(ls "$1"*".csv" ) echo $files for filename in $files; do echo $i if [[ $i -eq 0 ]] ; then # copy csv headers from first file echo "first file" head -1 $filename > $output_file fi echo $i "common part" # copy csv without headers from other files tail -n +2 $filename >> $output_file i=$(( $i + 1 )) done It’s still fairly simple, because it just uses a loop, a conditional and head and tail which either read a line-based file from the top or the bottom (with a specified offset).
This script will produce output like the following to output.csv if run like this: ./merge.sh file output.csv
Name,Email Sirius,s.black@hogwarts.com Remus,r.lupin@hogwarts.com Whistler,grumpy_redneck@vampirekillerelite.net Salome,givemethehead@dungeon.com Galadriel,AwesomeElvenQueen@loth.lorien Saruman,WhiteHand69@dark.tower I hope somebody finds this useful. If you found this post, let me know what you’re doing with it
Are you in email marketing? Are you a data scientist?
Tagged with: #csv #head #tail
Thank you for reading! If you have any comments, additions or questions, please tweet or toot them at me!