- How to Count Lines in a Linux File?
- How to Count Lines in a Linux File?
- Method 1: Using wc Command
- Method 2: Using grep Command
- Method 3: Using sed Command
- Method 4: Using awk Command
- Method 5: Using nl Command
- Method 6: Using perl Command
- Additional Tip: How to Count the Number of Lines in Real-Time?
- Conclusion
- How to Count lines in a file in UNIX/Linux
- Using “wc -l”
- Using awk
- Using sed
- Using grep
- Some more commands
- 8 Ways to Count Lines in a File in Linux
- The concept of Data Streams and Piping
- Data streams
- Piping
- Ways to Count Lines in a File in Linux
- WC
- count lines in a file
How to Count Lines in a Linux File?
In Linux, all the primary operations are performed from the terminal, and so is the file management. Files can be created, edited, and deleted through the terminal. The number of lines in a file can be counted to analyze the size (vertically) of the file. This post will offer various command line utilities to count lines in a Linux file. The content discussed in the post is provided below:
- How to Count Lines in a Linux File?
- Method 1: Using wc Command
- Method 2: Using grep Command
- Method 3: Using sed Command
- Method 4: Using awk Command
- Method 5: Using nl Command
- Method 6: Using perl Command
- Additional Tip: How to Count the Number of Lines in Real-Time?
How to Count Lines in a Linux File?
While working with files in Linux, we may encounter the need to manage the file length by counting the number of lines. There are several methods to count lines in Linux files; let’s discuss each method.
For example, the following file will be used in the upcoming methods.
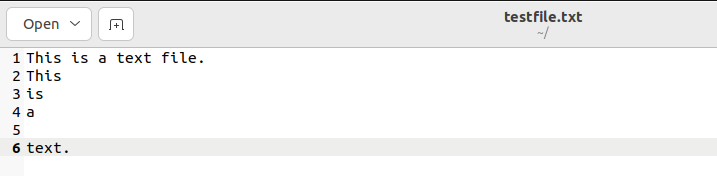
Method 1: Using wc Command
The “wc” (words count) command is the most popular way to count the number of lines in a document. This command counts the number of characters, words, and lines, words in a document.
Example 1: Count the Lines in a Single File
To count the total lines in a Linux file “testfile.txt” with the help of the “wc” command, the below command is used:
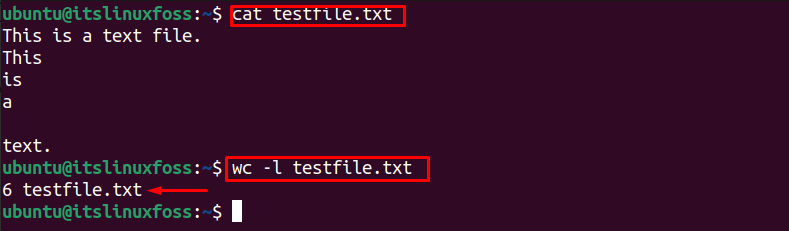
The output shows 6 lines, including the blank line in “testfile.txt”.
Example 2: Count Lines in Multiple Files
Similarly, the wc command counts the lines for several files simultaneously. For instance, to find total lines in three files, i.e., “testfile.txt”, “testfile1.txt”, and “testfile2.txt”.
$ wc -l testfile.txt testfile1.txt testfile2.txt
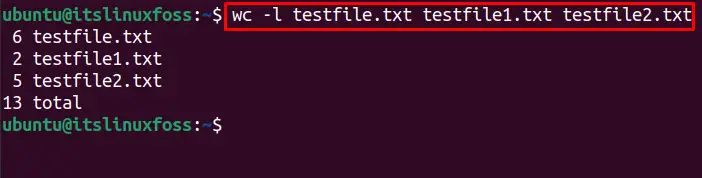
The output represents the total lines (first column), and respective file name (column 2). Moreover, it also calculates the sum of the lines in three files.
Example 3: Count the Number of Lines, Characters, and Words
Using the wc command, you can count the characters, lines, and words in “testfile.txt”, use the following command:

The output shows 6 lines, 9 words, and 58 characters in “testfile.txt”.
Method 2: Using grep Command
The grep command is widely used to search different patterns, words, and lines. The grep command counts all lines, lines with a specific word/pattern, and lines without a specific word or pattern.
Example 1: Count Lines in a File
To count the lines in “testfile.txt”, with the “grep” command, this command is used:

Similarly, the below grep command can also be used to count lines in a Linux file:

Six (6) lines are in testfile.txt.
Example 2: Count Lines That Contain Specific Word
If you want to count lines having a specific pattern/word (text) in them, execute this command:
$ grep -w "text" -c testfile.txt
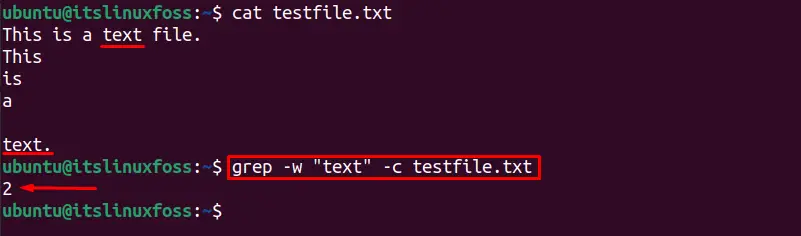
Two lines have a “text” word.
Example 3: Count Lines That Do Not Have Specific Word(s)
We can count the number of lines in which a specific word is not present. To find the lines which do not have a “text” word/pattern in them, run this command:
$ grep -w "text" -c -v testfile.txt

The output shows four (4) lines that do not have the “text” word.
Method 3: Using sed Command
The “sed”command allows the users to count the lines in a Linux file. For instance, to count the lines in “testfile.txt”, utilize the below command:

The output shows the line count is 6.
Method 4: Using awk Command
The awk helps users to manipulate the file data and find the details. For counting the lines in “testfile.txt” with awk, execute this command:

The output displays the line count “6”.
Method 5: Using nl Command
The nl (number of lines) command reads the file parameters and displays details on the standard output. To count the “testfile.txt” lines with nl, use the below command:
Note: The nl command counts the non-empty lines only.
$ nl testfile.txt | tail -1 | awk ''
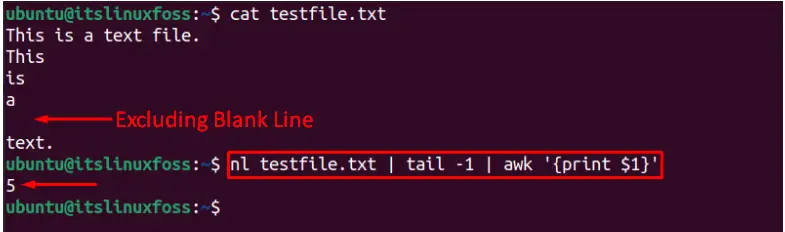
It shows five (5) lines are in the testfile.txt, which excludes the empty lines.
Method 6: Using perl Command
The perl command is commonly used for text processing, like getting the desired information from a specific file. The perl command allows us to count the lines in Linux as done for “testfile.txt”:
$ perl -lne 'END < print $. >' testfile.txt

6 lines are present in the testfile.txt.
Additional Tip: How to Count the Number of Lines in Real-Time?
If you want to find the real-time file information after a specified delay, the watch command is used with wc. To count the lines in testfile.txt after a specific time (in this case, 2 seconds), the below command should be used:

The output displays the time interval (2 seconds), file name, timestamp, the file lines are counted and the number of lines present in the file.
That’s the end of the post.
Conclusion
To count the lines in a Linux file, numerous commands are used, including wc (word count), grep, sed, awk, nl (number of lines), and perl. Among these, the “wc” utility is used the most as it offers the number of words and characters. This post has addressed various command line utilities used to count lines in a Linux file.
How to Count lines in a file in UNIX/Linux
Question: I have a file on my Linux system having a lot of lines. How do I count the total number of lines in the file?
Using “wc -l”
There are several ways to count lines in a file. But one of the easiest and widely used way is to use “wc -l”. The wc utility displays the number of lines, words, and bytes contained in each input file, or standard input (if no file is specified) to the standard output.
So consider the file shown below:
$ cat file01.txt this is a sample file with some sample data
1. The “wc -l” command when run on this file, outputs the line count along with the filename.
$ wc -l file01.txt 5 file01.txt
2. To omit the filename from the result, use:
3. You can always provide the command output to the wc command using pipe. For example:
You can have any command here instead of cat. Output from any command can be piped to wc command to count the lines in the output.
Using awk
If you must want to use awk to find the line count, use the below awk command:
Using sed
Use the below sed command syntax to find line count using GNU sed:
Using grep
Our good old friend «grep» can also be used to count the number of lines in a file. These examples are just to let you know that there are multiple ways to count the lines without using «wc -l». But if asked I will always use «wc -l» instead of these options as it is way too easy to remember.
With GNU grep, you can use the below grep syntax:
Here is another version of grep command to find line count.
$ grep -Hc ".*" file01.txt file01.txt:5
Some more commands
Along with the above commands, its good to know some rarely used commands to find the line count in a file.
1. Use the nl command (line numbering filter) to get each line numbered. The syntax for the command is:
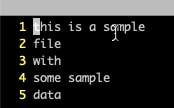
$ nl file01.txt 1 this is a sample 2 file 3 with 4 some sample 5 data
Not so direct way to get line count. But you can use awk or sed to get the count from last line. For example:
$ nl file01.txt | tail -1 | awk '' 5
2. You can also use vi and vim with the command «:set number» to set the number on each line as shown below. If the file is very big, you can use «Shift+G» to go to the last line and get the line count.
3. Use the cat command with -n switch to get each line numbered. Again, here you can get the line count from the last line.
$ cat -n file01.txt 1 this is a sample 2 file 3 with 4 some sample 5 data
$ cat -n file01.txt | tail -1 | awk '' 5
4. You can also use perl one lines to find line count:
$ perl -lne 'END < print $. >' file01.txt 5
8 Ways to Count Lines in a File in Linux
![wc -l < [filename] on a green background](https://bytexd.com/wp-content/uploads/2022/06/8-Ways-to-Count-Lines-in-a-File-in-Linux-800x500.png)
Counting lines in a Linux file can be hectic if you don’t know the applicable commands and how to combine them. This tutorial makes the process comfortable by walking you through eight typical commands to count lines in a file in Linux.
For example, the word count, wc , command’s primary role, as the name suggests, is to count words. However, since a group of words forms a line, you can use the command to count lines besides characters and words.
All you do is redirect the input of a file to the command alongside the -l flag.
Apart from the wc , you can use the awk, sed, grep, nl , pr , cat and perl commands. Before that, it would help to understand data streams and piping in Linux.
Table of Contents
The concept of Data Streams and Piping
Data streams
Three files come together to complete the request when you run a command: standard input, standard output, and error files.
The standard input, abbreviated as stdin and redirected as < , feeds the computer with data. The standard output, abbreviated as stdout and redirected as >, shows the result of running a command. If an error occurs when processing the result, we see the standard error, often abbreviated as stderr .
The primary stdin is the keyboard, while the stdout is the (monitor) screen. However, due to the flexibility of Linux and the fact that everything in Linux is a file, we can change the stdin , stdout , or stderr to suit our needs, as you will see when counting lines with the wc command.
Before that, you should understand the concept of piping in Linux.
Piping
Piping in Linux, denoted by | , means running two or more commands simultaneously on the terminal. For example, we can cat a file, let’s call the file index.txt . But instead of waiting to see the output, we redirect it to the sort command, which outputs the data alphabetically.
Now that you understand the main concepts applied when customizing a file’s input to get the number of lines, let’s see eight ways to count lines in a file in Linux.
Ways to Count Lines in a File in Linux
WC
The wc command returns a file’s line numbers, words, and characters, respectively.
Let’s create a file, practice.txt , and append the following lines.
We are counting file lines. We use the wc, awk, sed, grep, and perl commands. The process is easy because we can redirect ouptut and pipe commands. Linux is becoming fun!
Running the wc command on the file, we get the following output:
Likewise, we can control the output using specific flags with the input redirection symbol.
count lines in a file
The standard way is with wc , which takes arguments to specify what it should count (bytes, chars, words, etc.); -l is for lines:
$ wc -l file.txt 1020 file.txt How do I count the lines in a file if I want to ignore comments? Specifically, I want to not count lines that begin with a +, some white space (could be no white space) and then a %, which is the way comment lines appear in a git diff of a MATLAB file. I tried doing this with grep, but couldn’t figure out the correct regular expression.
@Gdalya I hope the following pipeline will do this (no tests were perfomed): cat matlab.git.diff | sed -e ‘/^\+[ ]*.*\%$/d’ | wc -l . /regexp/d deletes a line if it matches regexp , and -e turns on an adequate (IMNSHO) syntax for regexp .
@celtschk , as long as this is usual in comment lines: is it possible to modify your grep command in order to consider as comment cases like » + Hello» (note the space(s) before the + )?
@SopalajodeArrierez: Of course it is possible: grep -v ‘^ *+’ matlab.git.diff | wc -l (I’m assuming the quote signs were not actually meant to be part of the line; I also assume that both lines with and without spaces in front of the + are meant to be comments; if at least one space is mandatory, either replace the star * with \+ , or just add another space in front of the star). Probably instead of matching only spaces, you’d want to match arbitrary whitespace; for this replace the space with [[:space:]] . Note that I’ve also removed matching the % since it’s not in your example.