Count lines in large files
I commonly work with text files of ~20 Gb size and I find myself counting the number of lines in a given file very often. The way I do it now it’s just cat fname | wc -l , and it takes very long. Is there any solution that’d be much faster? I work in a high performance cluster with Hadoop installed. I was wondering if a map reduce approach could help. I’d like the solution to be as simple as one line run, like the wc -l solution, but not sure how feasible it is. Any ideas?
Thanks. yes. but to access many nodes I use an LSF system which sometimes exhibits quite an annoying waiting time, that’s why the ideal solution would be to use hadoop/mapreduce in one node but it’d be possible to use other nodes (then adding the waiting time may make it slower than just the cat wc approach)
wc -l fname may be faster. You can also try vim -R fname if that is faster (it should tell you the number of lines after startup).
15 Answers 15
Also cat is unnecessary: wc -l filename is enough in your present way.
mmm interesting. would a map/reduce approach help? I assume if I save all the files in a HDFS format, and then try to count the lines using map/reduce would be much faster, no?
@lvella. It depends how they are implemented. In my experience I have seen sed is faster. Perhaps, a little benchmarking can help understand it better.
@KingsIndian. Indeeed, just tried sed and it was 3 fold faster than wc in a 3Gb file. Thanks KingsIndian.
@Dnaiel If I would guess I’d say you ran wc -l filename first, then you ran sed -n ‘$=’ filename , so that in the first run wc had to read all the file from the disk, so it could be cached entirely on your probably bigger than 3Gb memory, so sed could run much more quickly right next. I did the tests myself with a 4Gb file on a machine with 6Gb RAM, but I made sure the file was already on the cache; the score: sed — 0m12.539s, wc -l — 0m1.911s. So wc was 6.56 times faster. Redoing the experiment but clearing the cache before each run, they both took about 58 seconds to complete.
This solution using sed has the added advantage of not requiring an end of line character. wc counts end of line characters («\n»), so if you have, say, one line in the file without a \n, then wc will return 0. sed will correctly return 1.
Your limiting speed factor is the I/O speed of your storage device, so changing between simple newlines/pattern counting programs won’t help, because the execution speed difference between those programs are likely to be suppressed by the way slower disk/storage/whatever you have.
But if you have the same file copied across disks/devices, or the file is distributed among those disks, you can certainly perform the operation in parallel. I don’t know specifically about this Hadoop, but assuming you can read a 10gb the file from 4 different locations, you can run 4 different line counting processes, each one in one part of the file, and sum their results up:
$ dd bs=4k count=655360 if=/path/to/copy/on/disk/1/file | wc -l & $ dd bs=4k skip=655360 count=655360 if=/path/to/copy/on/disk/2/file | wc -l & $ dd bs=4k skip=1310720 count=655360 if=/path/to/copy/on/disk/3/file | wc -l & $ dd bs=4k skip=1966080 if=/path/to/copy/on/disk/4/file | wc -l & Notice the & at each command line, so all will run in parallel; dd works like cat here, but allow us to specify how many bytes to read ( count * bs bytes) and how many to skip at the beginning of the input ( skip * bs bytes). It works in blocks, hence, the need to specify bs as the block size. In this example, I’ve partitioned the 10Gb file in 4 equal chunks of 4Kb * 655360 = 2684354560 bytes = 2.5GB, one given to each job, you may want to setup a script to do it for you based on the size of the file and the number of parallel jobs you will run. You need also to sum the result of the executions, what I haven’t done for my lack of shell script ability.
If your filesystem is smart enough to split big file among many devices, like a RAID or a distributed filesystem or something, and automatically parallelize I/O requests that can be paralellized, you can do such a split, running many parallel jobs, but using the same file path, and you still may have some speed gain.
EDIT: Another idea that occurred to me is, if the lines inside the file have the same size, you can get the exact number of lines by dividing the size of the file by the size of the line, both in bytes. You can do it almost instantaneously in a single job. If you have the mean size and don’t care exactly for the the line count, but want an estimation, you can do this same operation and get a satisfactory result much faster than the exact operation.
Количество строк в файле Linux
Несмотря на то, что утилиты с графическим интерфейсом гораздо удобнее в использовании и адаптированы под высокие разрешения, в терминале можно делать многие вещи гораздо быстрее. Например, утилита wc просто подсчитывает количество строк в файле.
Но само количество строк мало о чём говорит, поэтому совмещение нескольких команд позволяет считать строки с учётом требуемых параметров. Мы рассмотрим несколько примеров как подсчитать количество строк в файле linux с использованием таких команд, как grep, sed и awk.
Как узнать количество строк в файле Linux
Команду wc мы уже рассматривали, нас интересует только параметр -l. В общем случае он считает количество переходов на новую строку, поэтому учитываются все строки, в том числе пустые. С этой задачей она справится быстрее остальных команд, таких как grep, sed, awk. Но эти команды способны подсчитать строки с заданным условием.
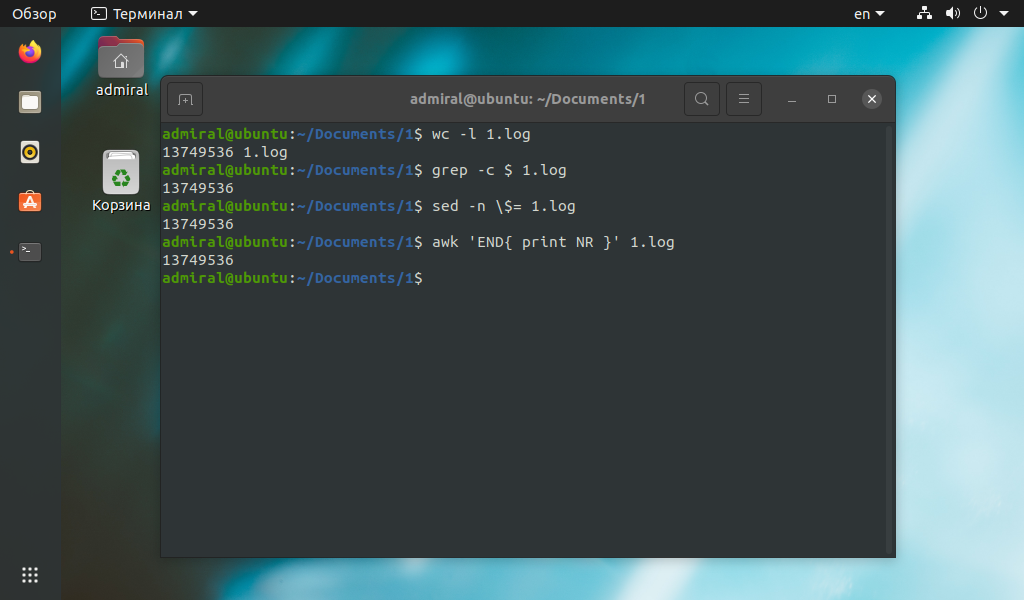
Как видите, результат один и тот же, только вот команда wc потратила на порядок меньше времени. Поэтому остальные команды стоит использовать для более сложных запросов. Рассмотрим несколько примеров.
Команда grep поможет найти строки только с нужным текстом:
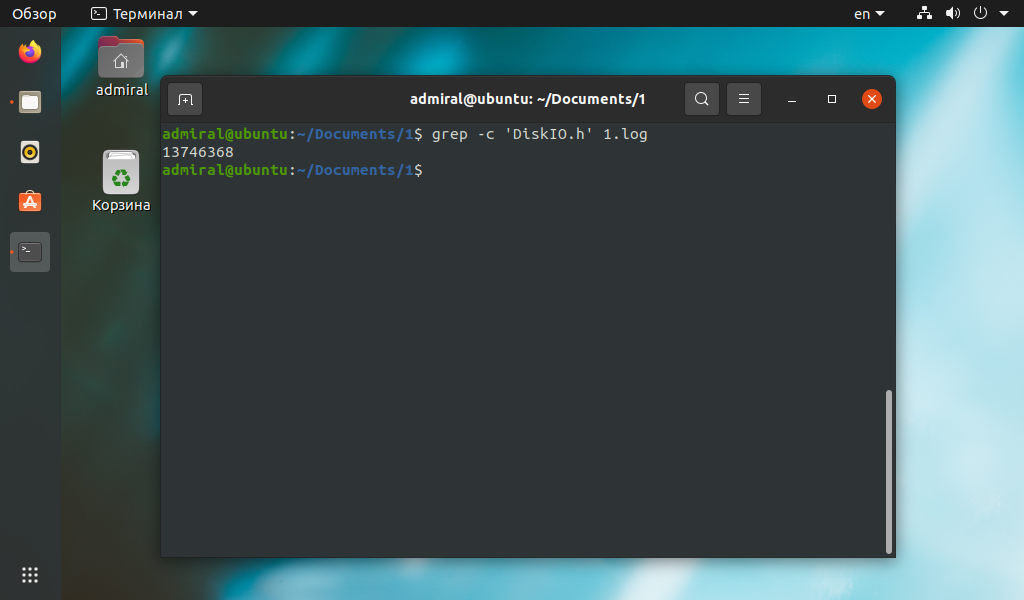
Команда grep умеет работать с регулярными выражениями и объединять условия с помощью операторов И, ИЛИ, НЕ.
Команда sed умеет обрабатывать текст, но проще всего посчитать количество результирующих строк командой wc. Например, можно удалить все строки длиной менее 3 символов, а в более сложных случаях подсчитать количество строк без комментариев.
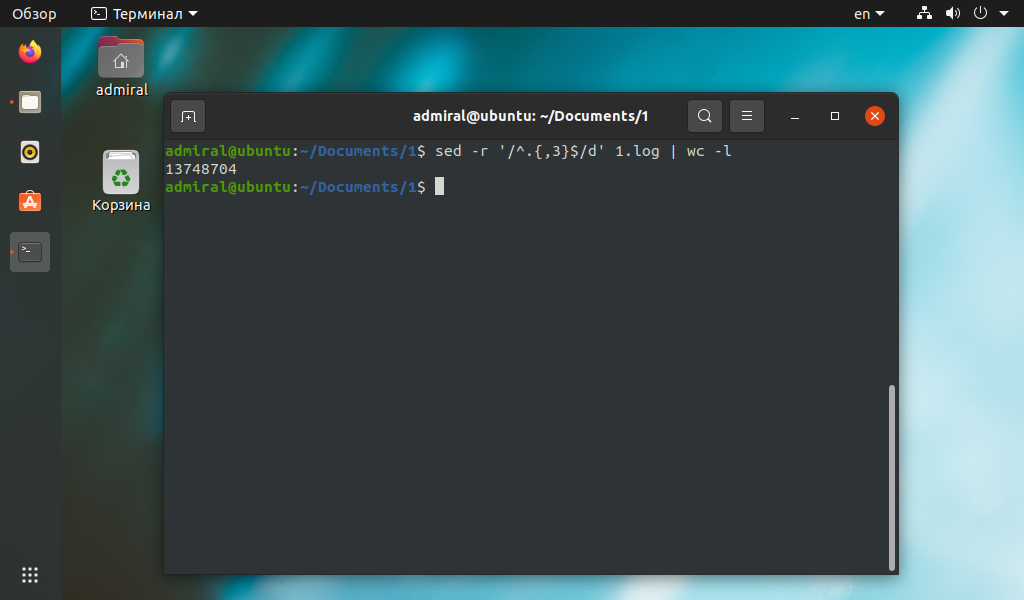
Столь простой пример можно было выполнить и другими командами. Синтаксис команды awk в этом случае гораздо понятнее.
awk ‘length >3’ имя_файла | wc -l
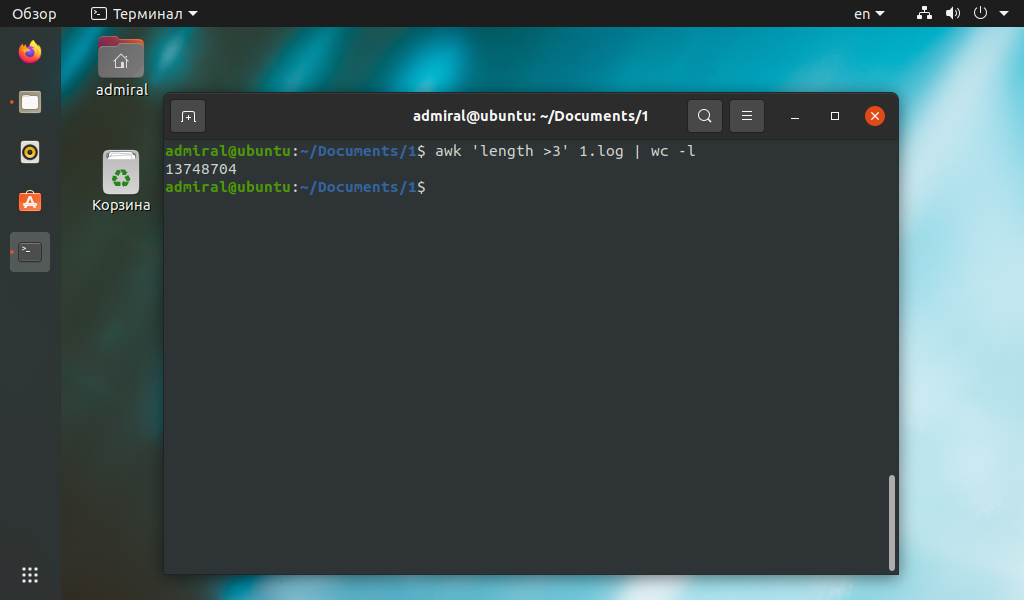
Другим примером использования команды awk может стать подсчёт строк с поиском нужного значения в табличном файле csv. В этом примере мы подсчитали количество строк, у которых значение второго параметра больше 50.
awk ‘$2+0 > 50’ имя_файла | wc -l
Мы добавили 0 к выражению неспроста, он позволяет отсеять нечисловые выражения.
Выводы
Теперь вы знаете как посчитать количество строк в файле linux. К плюсам подсчёта количества строк с помощью консольных команд можно отнести универсальность и скорость работы. Мы рассмотрели далеко не все команды, способные подсчитать количество строк, есть tr, nl, не говоря уже о языках программирования, вроде PERL. Но имеются и существенные минусы, например, сложный синтаксис регулярных выражений, внести изменения в команду порой сложнее, чем написать её заново.
Если правильно подойти к подсчёту строк, то он может стать основой для сбора статистики и оценки файлов. Как вы могли убедиться, одну и ту же задачу можно выполнить нескольким способами, поэтому выбирайте наиболее подходящую команду.
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.
count lines in a file
The standard way is with wc , which takes arguments to specify what it should count (bytes, chars, words, etc.); -l is for lines:
$ wc -l file.txt 1020 file.txt How do I count the lines in a file if I want to ignore comments? Specifically, I want to not count lines that begin with a +, some white space (could be no white space) and then a %, which is the way comment lines appear in a git diff of a MATLAB file. I tried doing this with grep, but couldn’t figure out the correct regular expression.
@Gdalya I hope the following pipeline will do this (no tests were perfomed): cat matlab.git.diff | sed -e ‘/^\+[ ]*.*\%$/d’ | wc -l . /regexp/d deletes a line if it matches regexp , and -e turns on an adequate (IMNSHO) syntax for regexp .
@celtschk , as long as this is usual in comment lines: is it possible to modify your grep command in order to consider as comment cases like » + Hello» (note the space(s) before the + )?
@SopalajodeArrierez: Of course it is possible: grep -v ‘^ *+’ matlab.git.diff | wc -l (I’m assuming the quote signs were not actually meant to be part of the line; I also assume that both lines with and without spaces in front of the + are meant to be comments; if at least one space is mandatory, either replace the star * with \+ , or just add another space in front of the star). Probably instead of matching only spaces, you’d want to match arbitrary whitespace; for this replace the space with [[:space:]] . Note that I’ve also removed matching the % since it’s not in your example.
How do I count the number of rows and columns in a file using bash?
Say I have a large file with many rows and many columns. I’d like to find out how many rows and columns I have using bash.
Sorry, I’m not very familiar with bash. In R, it would look something like dim(input), which would return two numbers, #rows and #cols.
an actual input file might look like: «blah\tdata\tdata\tdata\tdata\nblah2\tdata\tdata\tdata\tdata\n»
I was hoping there might be an elegant way to do this with some built-in function. perhaps something like wc?
13 Answers 13
Columns: awk » file | sort -nu | tail -n 1
Use head -n 1 for lowest column count, tail -n 1 for highest column count.
Rows: cat file | wc -l or wc -l < file for the UUOC crowd.
@Tim: Typo, should be < obviously. This isn't how I'd do it, but it satisfies the UUOC crowd ( cat enhances readability IMO, and I prefer it over the less readable pipes especially when answering newbie questions)
@Erik You can also do «< file wc -l" and put the redirection before the command for enhanced readability. (Although, in this case I'm not sure why you don't just do "wc -l file")
No need for the sort or the tail, just do it all in awk: awk ‘
@Joy: awk -F’\t’ ‘
Alternatively to count columns, count the separators between columns. I find this to be a good balance of brevity and ease to remember. Of course, this won’t work if your data include the column separator.
head -n1 myfile.txt | grep -o " " | wc -l Uses head -n1 to grab the first line of the file. Uses grep -o to to count all the spaces, and output each space found on a new line. Uses wc -l to count the number of lines.
EDIT: As Gaurav Tuli points out below, I forgot to mention you have to mentally add 1 to the result, or otherwise script this math.
column count in a CSV will be head -n1 myfile.txt | grep -o «,» | wc -l + 1 because grep is counting the number of commas (or any other column separator) but the number of columns would be 1 more than that.
If your file is big but you are certain that the number of columns remains the same for each row (and you have no heading) use:
to find the number of columns, where FILE is your file name.
To find the number of lines ‘wc -l FILE’ will work.
Little twist to kirill_igum’s answer, and you can easily count the number of columns of any certain row you want, which was why I’ve come to this question, even though the question is asking for the whole file. (Though if your file has same columns in each line this also still works of course):
head -2 file |tail -1 |tr '\t' '\n' |wc -l Gives the number of columns of row 2. Replace 2 with 55 for example to get it for row 55.
-bash-4.2$ cat file 1 2 3 1 2 3 4 1 2 1 2 3 4 5 -bash-4.2$ head -1 file |tail -1 |tr '\t' '\n' |wc -l 3 -bash-4.2$ head -4 file |tail -1 |tr '\t' '\n' |wc -l 5 Code above works if your file is separated by tabs, as we define it to «tr». If your file has another separator, say commas, you can still count your «columns» using the same trick by simply changing the separator character «t» to «,»:
-bash-4.2$ cat csvfile 1,2,3,4 1,2 1,2,3,4,5 -bash-4.2$ head -2 csvfile |tail -1 |tr '\,' '\n' |wc -l 2