- Как работает метрика Load Average в Linux
- Основы Load Average в Linux
- Метрика Load Average в Linux
- Проверка Load Average в Linux
- 1: Команда uptime
- 2: Команда top
- 3: Утилита glances
- Подводим итоги
- Understand Linux Load Averages and Monitor Performance of Linux
- How to Monitor Linux System Load Average
- Top Command
- Glances Tool
- Understanding System Average Load in Relation Number of CPUs
- Multi-processor Vs Multi-core
Как работает метрика Load Average в Linux
Load Average (cредняя нагрузка) — это метрика, которую используют пользователи Linux для отслеживания системных ресурсов. Она также помогает мониторить, как задействованы ресурсы системы.
Load Average является одной из самых основных метрик использования ресурсов, но она не принесет никакой пользы, если вы не понимаете, о чем она говорит. В этом мануале мы рассмотрим, что такое Load Average в Linux и как ее читать. Кроме того, мы обсудим несколько простых методов для мониторинга Load Average вашей системы.
Основы Load Average в Linux
Чтобы понять, что такое Load Average, нам нужно знать, что именно мы определяем как нагрузку. В системе Linux это показатель загруженности CPU в любой момент времени.
Она показывает количество процессов, которые выполняются или ожидают выполнения процессором в данный момент.
В состоянии бездействия нагрузка системы равна 0. Она увеличивается на 1 с каждым процессом, который выполняется или находится в списке ожидания.
Сама по себе нагрузка не дает пользователю никакой полезной информации. Она может измениться за доли секунды. Это происходит потому, что количество процессов, использующих процессорное время или находящихся в списке ожидания, не остается постоянным. Вот почему мы используем Load Average для мониторинга использования ресурсов.
Метрика Load Average в Linux
Как следует из названия, Load Average отображает среднюю нагрузку на CPU за определенный период времени. Эти значения представляют собой количество процессов, ожидающих выполнения на CPU или использующих его в данный период.
Большинство пользователей знакомы с процентами нагрузки в Windows, но в Linux Load Average представляется тремя десятичными значениями.

Посмотрите на скриншот выше, где показаны значения “load average: 0.03, 0.03, 0.01”.
Рассмотрим эти значения по порядку:
- Первое показывает среднюю нагрузку на CPU за последнюю минуту
- Второе дает нам среднюю нагрузку за последний 5-минутный интервал
- Третье значение показывает среднюю загрузку за последние 15 минут
Это помогает пользователю понять, как процессы в системе нагружают CPU с течением времени.
Значение 1 может означать примерно 100% использования ресурсов в однопроцессорной системе, но такие системы сегодня практически не встречаются. Если за последние 10 лет вы хотя бы раз обновляли свою систему, она должна работать на многоядерном процессоре.
Для двухъядерного процессора значение 1 означает, что одно ядро свободно на 100 %. То есть это примерно 50% использования CPU. Соответственно, для четырехъядерного процессора это 25% использования.
Load Average в Linux учитывает ожидающие и выполняемые процессы. Кроме того, это среднее значение, а не текущее.
Для приблизительного представления об использовании ресурсов можно разделить значение Load Average на количество ядер вашего процессора. Это не точное значение загрузки CPU, но это может быть полезно для мониторинга ресурсов.
Проверка Load Average в Linux
Теперь мы рассмотрим несколько способов проверки значения Load Average. Её можно посмотреть тремя способами.
1: Команда uptime
uptime — один из наиболее распространенных методов проверки Load Average в системе. Чтобы выполнить команду uptime, просто откройте терминал и введите следующее:
На скриншоте выше показано, что вы увидете при выполнении команды uptime. Здесь отображается время работы системы, количество активных пользователей и Load Average.
Как видите, Load Average за последнюю минуту равна 0.03. Значения за последние 5 и 15 минут составляют 0.03 и 0.01 соответственно .
2: Команда top
Ещё один способ мониторинга Load Average — выполнить команду top. Для этого откройте терминал и введите следующую команду:
Команда откроет интерфейс top в терминале. В отличие от uptime, эта команда выводит подробное описание об использовании ресурсов вашей системы.
На следующем скриншоте показано, что вы увидите при выполнении команды top.
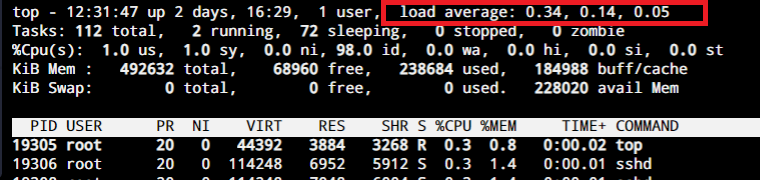
Как видно из самой верхней строки, Load Average за последнюю минуту составляет 0.34. За последние 5 минут и 15 минут значения равны 0.14 и 0.05 соответственно.
3: Утилита glances
glances — это утилита мониторинга системы, которая работает аналогично команде top. Она дает подробный обзор использования системных ресурсов. Чтобы использовать утилиту glances, необходимо установить её пакет с помощью этой команды:
sudo apt-get install glances
После завершения установки введите в терминале следующее:
Команда откроет интерфейс glances в терминале. В отличие от команды top, здесь отображается количество доступных процессорных ядер, а также Load Average системы.
На следующем скриншоте показано, что вы увидите, при выполнении команды glances.
Как видно из выделенной области, Load Average за последнюю минуту равна 0.14. За последние 5 минут и 15 минут значения равны 0.12 и 0.05 соответственно.
Подводим итоги
Load Average в Linux — это важная метрика, позволяющая легко мониторить использование системных ресурсов. Контроль Load Average гарантирует, что ваша система не столкнется со сбоями или медленными сессиями.
Understand Linux Load Averages and Monitor Performance of Linux
In this article, we will explain one of the critical Linux system administration tasks – performance monitoring in regards to system/CPU load and load averages.
Before we move any further, let’s understand these two important phrases in all Unix-like systems:
- System load/CPU Load – is a measurement of CPU over or under-utilization in a Linux system; the number of processes which are being executed by the CPU or in waiting state.
- Load average – is the average system load calculated over a given period of time of 1, 5 and 15 minutes.
In Linux, the load-average is technically believed to be a running average of processes in it’s (kernel) execution queue tagged as running or uninterruptible.
- All if not most systems powered by Linux or other Unix-like systems will possibly show the load average values somewhere for a user.
- A downright idle Linux system may have a load average of zero, excluding the idle process.
- Nearly all Unix-like systems count only processes in the running or waiting states. But this is not the case with Linux, it includes processes in uninterruptible sleep states; those waiting for other system resources like disk I/O etc.
How to Monitor Linux System Load Average
There are numerous ways of monitoring system load average including uptime which shows how long the system has been running, number of users together with load averages:
$ uptime 07:13:53 up 8 days, 19 min, 1 user, load average: 1.98, 2.15, 2.21
The numbers are read from left to right, and the output above means that:
- load average over the last 1 minute is 1.98
- load average over the last 5 minutes is 2.15
- load average over the last 15 minutes is 2.21
High load averages imply that a system is overloaded; many processes are waiting for CPU time.
We will uncover this in the next section in relation to number of CPU cores. Additionally, we can as well use other well known tools such as top and glances which display a real-time state of a running Linux system, plus many other tools:
Top Command
top - 12:51:42 up 2:11, 1 user, load average: 1.22, 1.12, 1.26 Tasks: 243 total, 1 running, 242 sleeping, 0 stopped, 0 zombie %Cpu(s): 17.4 us, 2.9 sy, 0.3 ni, 74.8 id, 4.6 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 8069036 total, 388060 free, 4381184 used, 3299792 buff/cache KiB Swap: 3906556 total, 3901876 free, 4680 used. 2807464 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6265 tecmint 20 0 1244348 170680 83616 S 13.3 2.1 6:47.72 Headset 2301 tecmint 9 -11 640332 13344 9932 S 6.7 0.2 2:18.96 pulseaudio 2459 tecmint 20 0 1707692 315628 62992 S 6.7 3.9 6:55.45 cinnamon 2957 tecmint 20 0 2644644 1.035g 137968 S 6.7 13.5 50:11.13 firefox 3208 tecmint 20 0 507060 52136 33152 S 6.7 0.6 0:04.34 gnome-terminal- 3272 tecmint 20 0 1521380 391324 178348 S 6.7 4.8 6:21.01 chrome 6220 tecmint 20 0 1595392 106964 76836 S 6.7 1.3 3:31.94 Headset 1 root 20 0 120056 6204 3964 S 0.0 0.1 0:01.83 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:00.10 ksoftirqd/0 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H .
Glances Tool
TecMint (LinuxMint 18 64bit / Linux 4.4.0-21-generic) Uptime: 2:16:06 CPU 16.4% nice: 0.1% LOAD 4-core MEM 60.5% active: 4.90G SWAP 0.1% user: 10.2% irq: 0.0% 1 min: 1.20 total: 7.70G inactive: 2.07G total: 3.73G system: 3.4% iowait: 2.7% 5 min: 1.16 used: 4.66G buffers: 242M used: 4.57M idle: 83.6% steal: 0.0% 15 min: 1.24 free: 3.04G cached: 2.58G free: 3.72G NETWORK Rx/s Tx/s TASKS 253 (883 thr), 1 run, 252 slp, 0 oth sorted automatically by cpu_percent, flat view enp1s0 525Kb 31Kb lo 2Kb 2Kb CPU% MEM% VIRT RES PID USER NI S TIME+ IOR/s IOW/s Command wlp2s0 0b 0b 14.6 13.3 2.53G 1.03G 2957 tecmint 0 S 51:49.10 0 40K /usr/lib/firefox/firefox 7.4 2.2 1.16G 176M 6265 tecmint 0 S 7:08.18 0 0 /usr/lib/Headset/Headset --type=renderer --no-sandbox --primordial-pipe-token=879B36514C6BEDB183D3E4142774D1DF --lan DISK I/O R/s W/s 4.9 3.9 1.63G 310M 2459 tecmint 0 R 7:12.18 0 0 cinnamon --replace ram0 0 0 4.2 0.2 625M 13.0M 2301 tecmint -11 S 2:29.72 0 0 /usr/bin/pulseaudio --start --log-target=syslog ram1 0 0 4.2 1.3 1.52G 105M 6220 tecmint 0 S 3:42.64 0 0 /usr/lib/Headset/Headset ram10 0 0 2.9 0.8 409M 66.7M 6240 tecmint 0 S 2:40.44 0 0 /usr/lib/Headset/Headset --type=gpu-process --no-sandbox --supports-dual-gpus=false --gpu-driver-bug-workarounds=7,2 ram11 0 0 2.9 1.8 531M 142M 1690 root 0 S 6:03.79 0 0 /usr/lib/xorg/Xorg :0 -audit 0 -auth /var/lib/mdm/:0.Xauth -nolisten tcp vt8 ram12 0 0 2.6 0.3 79.3M 23.8M 9651 tecmint 0 R 0:00.71 0 0 /usr/bin/python3 /usr/bin/glances ram13 0 0 1.6 4.8 1.45G 382M 3272 tecmint 0 S 6:25.30 0 4K /opt/google/chrome/chrome .
The load averages shown by these tools is read /proc/loadavg file, which you can view using the cat command as below:
$ cat /proc/loadavg 2.48 1.69 1.42 5/889 10570
On desktop machines, there are graphical user interface tools that we can use to view system load averages.
Understanding System Average Load in Relation Number of CPUs
We can’t possibly explain system load or system performance without shedding light on the impact of the number of CPU cores on performance.
Multi-processor Vs Multi-core
- Multi-processor – is where two or more physical CPU’s are integrated into a single computer system.
- Multi-core processor – is a single physical CPU which has at least two or more separate cores (or what we can also refer to as processing units) that work in parallel. Meaning a dual-core has 2 two processing units, a quad-core has 4 processing units and so on.
Furthermore, there is also a processor technology which was first introduced by Intel to improve parallel computing, referred to as hyper threading.
Under hyper threading, a single physical CPU core appears as two logical CPUs core to an operating system (but in reality, there is one physical hardware component).
Note that a single CPU core can only carry out one task at a time, thus technologies such as multiple CPUs/processors, multi-core CPUs and hyper-threading were brought to life.
With more than one CPU, several programs can be executed simultaneously. Present-day Intel CPUs use a combination of both multiple cores and hyper-threading technology.
To find the number of processing units available on a system, we may use the nproc or lscpu commands as follows:
$ nproc 4 OR lscpu
Another way to find the number of processing units using grep command as shown.
$ grep 'model name' /proc/cpuinfo | wc -l 4
Now, to further understand system load, we will take a few assumptions. Let’s say we have load averages below:
23:16:49 up 10:49, 5 user, load average: 1.00, 0.40, 3.35
On a single core system this would mean:
- The CPU was fully (100%) utilized on average; 1 processes was running on the CPU (1.00) over the last 1 minute.
- The CPU was idle by 60% on average; no processes were waiting for CPU time (0.40) over the last 5 minutes.
- The CPU was overloaded by 235% on average; 2.35 processes were waiting for CPU time (3.35) over the last 15 minutes.
On a dual-core system this would mean:
- The one CPU was 100% idle on average, one CPU was being used; no processes were waiting for CPU time(1.00) over the last 1 minute.
- The CPUs were idle by 160% on average; no processes were waiting for CPU time. (0.40) over the last 5 minutes.
- The CPUs were overloaded by 135% on average; 1.35 processes were waiting for CPU time. (3.35) over the last 15 minutes.
In conclusion, if you are a system administrator then high load averages are real to worry about. When they are high, above the number of CPU cores, it signifies high demand for the CPUs, and low load averages below the number of CPU cores tells us that CPUs are underutilized.