- How to Use cURL to Download a File on Linux? | cURL Command Explained
- #What is curl?
- #Prerequisites
- #How to use curl to download a file: step-by-step
- #Step 1: Download a file with curl
- #Step 2: Where does curl download to and how to save the files with a different name
- #Step 3: Specify a non-default port
- #How to use several curl download commands with multiple conditions
- #Step 1: Restart interrupted downloads
- #Step 2: Download multiple files with one command
- #Step 3: Download multiple files in prallel
- #Step 4: Apply rate limiting to a curl download request
- #Step 5: Automatically abort slow downloads
- #Step 6: Display download status bar
- #Step 7: Make curl follow redirects
- #Step 8: Use basic authentication
- #Step 9: Suppress curl output
- #Step 10: Allow insecure SSL/TLS certificates
- #Step 11: Download Files with FTP and SFTP
- #Next Steps with Curl
- Mantas Levinas
- Join Cherry Servers Community
How to Use cURL to Download a File on Linux? | cURL Command Explained

If you’re looking for a quick answer, the curl -O command lets you use the curl command-line utility to download a file. Of course, there is much more to learn about downloading files with curl than just the -O parameter.
We’ll show how to use curl to download a file on Linux, as well as provide examples for multiple curl download commands you can use to meet different requirements. If you’re new to curl, we recommend reading the article end-to-end. If you’re familiar with curl but just need a quick refresher, feel free to jump to a specific section.
#What is curl?
curl is an open source command line utility for transferring data using URL syntax and a wide range of network protocols including HTTP(S), FTP, SFTP, LDAP(S), and SMTP. The curl command line utility is part of the cURL (“client for URLs”) project that includes the libcurl library.
Because curl often “just works”, is highly portable and installed by default on many systems, and is something of a de-facto standard in API documentation, it is a popular tool among developers and DevOps engineers.
#Prerequisites
If you’re running a modern Linux operating system, you probably have everything you need to follow along. To be sure, here are the prerequisites:
- curl — curl is installed by default on most popular *nix operating systems, including macOS. It is also available on modern Windows operating systems. You can check if curl is installed by running the curl -V command from a terminal. The output should look similar to:

If you’re a Linux user and don’t have curl installed, you can likely download it using your operating system’s default package manager (e.g. apt, yum, or zypper). There are curl download links for a variety of other operating systems here.
- Connection to a server to download files from- We’ll use HTTPS connections for most of our example commands, and we recommend you do too. However, curl supports over two dozen protocols. You can follow along with the example commands as long as you have access to a server to download files from that supports at least one of the protocols curl does. Be sure to replace our example links (such as http://speedtest.lt.cherryservers.com/test-100mb) with links to the files you want to download.
💡 Pro Tip: you can combine curl parameters. We’ll stick to using one or two parameters with the curl command in most of our examples. However, curl supports combining parameters as well. For example, if you want to download a file (-O), follow 301 redirects (-L), and allow insecure SSL certificates (-k), you can use curl -OLk.
#How to use curl to download a file: step-by-step
First, let’s dive right in to see how to download a file with the curl command on Linux.
#Step 1: Download a file with curl
The basic syntax to use curl to download a file is:
For example, to download a 1GB of dummy date using HTTPS from http://speedtest.lt.cherryservers.com/test-1000mb, use this command:
curl -O http://speedtest.lt.cherryservers.com/test-100mb
The output, known as the curl progress meter, is similar to the following:

By default, the files you download are saved in your current working directory. Below is an end-to-end visual example.
#Step 2: Where does curl download to and how to save the files with a different name
The curl -O command saves files locally in your current working directory using the filename from the remote server. You can specify a different local file name and download location using curl -o . The basic syntax is:
To save http://speedtest.lt.cherryservers.com/test-1000mb in your local /tmp directory as mydownload.zip, use this command:
curl -o /tmp/mydownload.zip http://speedtest.lt.cherryservers.com/test-1000mb
#Step 3: Specify a non-default port
By default, curl uses the default port for a protocol (80 for HTTP, 443 for HTTPS, 21 for FTP, etc). To specify a non-default port, append :[port_number] to the end of the remote server’s domain name or IP address.
Using our http://speedtest.lt.cherryservers.com/test-1000mb example, if the HTTP server ran on port 4040, you would use this command:
curl -O http://speedtest.lt.cherryservers.com:4040/test-1000mb
#How to use several curl download commands with multiple conditions
Curl commands are an excellent tool for downloading and transferring files on the Linux operating system. Here are some ways and examples of how you can use several curl download commands to download multiple files, restart interrupted downloads, download files in parallel, and more.
#Step 1: Restart interrupted downloads
In some cases, like when you download a large file over a poor network connection, file downloads get interrupted. The -C — option allows you to resume an interrupted download. The basic syntax is:
For example, to resume an HTTPS download of example.zip when the local download was /tmp/mydownload.zip, use this command:
curl -C — -o /tmp/mydownload.zip http://speedtest.lt.cherryservers.com/test-1000mb
Before displaying the curl progress meter, the output will include text similar to:

#Step 2: Download multiple files with one command
You can specify multiple URLs in a single curl command to download multiple files in one command.
For example, to download http://speedtest.lt.cherryservers.com/test-1000mb and http://speedtest.lt.cherryservers.com/test-100mb use this command:
curl -O http://speedtest.lt.cherryservers.com/test-1000mb -O http://speedtest.lt.cherryservers.com/test-100mb
The curl progress meter will display statistics for each of the downloads. For two URLs, the output will look similar to this:

If you have a long list of URLs, you can add them to a text file and then pass them to curl using xargs . To demonstrate, suppose we have a curlsites.txt file with our URLs placing each URL on a new line:
We can now use the xargs command with curl and our curlsites.txt file as an input to download each file:
#Step 3: Download multiple files in prallel
Normally, curl processes URLs one by one, and the xargs example above does too. However, you can add the -P parameter to xargs to download multiple files in parallel. For example, this command will run two curl downloads in parallel.
For more detail on xargs and its options, check out xargs man page.
#Step 4: Apply rate limiting to a curl download request
Rate limiting lets you specify a maximum transfer rate for a curl request. The basic syntax to apply rate limiting to a curl download request is:
By default, is measured in bytes per second. You can append one of the following suffixes to change the unit of measure:
For example, to set a 1000 byte per second rate limit on our example download, we can use this command:
curl —limit-rate 1000 -O http://speedtest.lt.cherryservers.com/test-100mb
curl —limit-rate 1k -O http://speedtest.lt.cherryservers.com/test-100mb
To limit to 100 megabytes per second:
curl —limit-rate 100m -O http://speedtest.lt.cherryservers.com/test-100mb
Note that curl attempts to average the transfer speed not to exceed the value. When you first run curl with the —limit-rate option, you may see speeds greater than the specified but they should quickly level off.
#Step 5: Automatically abort slow downloads
If the server you download a file from is too slow, you may want to abort the connection automatically. You can use the -Y (or —speed-limit ) and -y (or —speed-time ) options.
-Y (or —speed-limit ) option defines a speed (in bytes per second). The -y (or —speed-time ) option specifies an amount of time in seconds. If download speeds are less than the speed defined by -Y for the amount of time defined by -y , curl will abort the download. 30 seconds is the default time for -Y if -y is not specified. Below are three examples to demonstrate.
- Abort download if speed is less than ~100 KB/s (kilobytes per second) for 10 seconds: curl -O -Y 100000 -y 10 http://speedtest.lt.cherryservers.com/test-1000mb
- Abort download if speed is less than ~100 MB/s (megabytes per second) for 15 seconds: curl -O -Y 100000000 -y 15 http://speedtest.lt.cherryservers.com/test-1000mb
- Abort download if speed is less than 1KB/s for 30 seconds (30 seconds is default, so no need to specify -y): curl -O -Y 1000 http://speedtest.lt.cherryservers.com/test-1000mb
If curl aborts a download due to a speed transfer limit, it will print an error message similar to:

#Step 6: Display download status bar
Instead of a standard progress bar, you can make curl display a progress bar with the —progress-bar parameter. The progress bar will display the download’s progress as a percentage and with # symbols across the terminal.
You can append the —progress-bar parameter to most curl commands. Here is the basic syntax HTTPS download command with the —progress-bar parameter:
The progress bar output will look similar to:
#Step 7: Make curl follow redirects
301 redirects are common when downloading files from HTTP(S) servers. To have curl follow 301 redirects, use the -L parameter.
Examples of the basic syntax for following 301 redirects with the -L parameter are:
#Step 8: Use basic authentication
While modern forms of authentication like OAuth 2.0 are more common on modern HTTP servers, in some cases, a download may be protected using basic authentication that requires a username and password. For example, FTP downloads are a typical use case for basic authentication. You can supply a username and password for basic authentication using the -u parameter.
The basic syntax for basic authentication on a curl download request is:
#Step 9: Suppress curl output
You can suppress curl’s output with the -s parameter. The basic syntax to download a file silently with curl is:
This command downloads the file just like -O but does not print progress or statistics to standard output.
#Step 10: Allow insecure SSL/TLS certificates
In some cases, you may want to download a file via HTTPS even though a server has an invalid or self-signed certificate. You can use the -k option to have curl proceed without verifying TLS/SSL certificates. Note that this behavior is not secure!
Here is the basic syntax to allow insecure SSL certificates for a curl download:
If you’re intentionally connecting to a site with an insecure TLS/SSL certificate, the -k parameter can help resolve errors like:
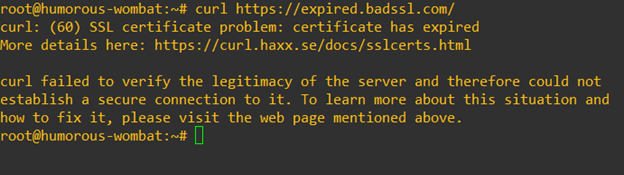
We also recommend visiting the official page mentioned in the error message for more details on curl and TLS/SSL.
#Step 11: Download Files with FTP and SFTP
In addition to HTTP(S), FTP and SFTP are popular protocols curl can use to download files. You can use FTP or SFTP by specifying those protocols in the command as we have with HTTPS in other examples.
Since FTP and SFTP servers often require a username and password, we’ll use the -u parameter in our examples.
The basic syntax for an FTP download with curl:
#Next Steps with Curl
Now that you understand common methods for downloading files with curl on Linux operating systems, you can move on to more advanced cases. We recommend referencing the official curl docs and the free Everything curl book for detailed information on specific use cases.

Mantas Levinas
Helping engineers learn 💡 about new technologies and ingenious IT automation use cases to build better systems 💻
Join Cherry Servers Community
Get monthly practical guides about building more secure, efficient and easier to scale systems on an open cloud ecosystem.