How to capture cURL output to a file?
What I’m looking to do is to run curl -K myfile.txt , and get the output of the response cURL returns, into a file. How can I do this?
11 Answers 11
curl -K myconfig.txt -o output.txt Writes the first output received in the file you specify (overwrites if an old one exists).
curl -K myconfig.txt >> output.txt Appends all output you receive to the specified file.
Note: The -K is optional.
Sorry maybe I need to clarify — the doc with all my URL’s in the format about is called myfile.txt so I do curl -K myfile.txt and it runs though each one but I don’t get the output into any file.
For a single file you can use -O instead of -o filename to use the last segment of the URL path as the filename. Example:
curl http://example.com/folder/big-file.iso -O will save the results to a new file named big-file.iso in the current folder. In this way it works similar to wget but allows you to specify other curl options that are not available when using wget.
Another addition for qwr’s comment: the argument need to be put before the URLs like curl —remote-name-all https://example.tld/resource <1,2,3>. See: curl.se/docs/manpage.html#—remote-name-all
There are several options to make curl output to a file
# saves it to myfile.txt curl http://www.example.com/data.txt -o myfile.txt # The #1 will get substituted with the url, so the filename contains the url curl http://www.example.com/data.txt -o "file_#1.txt" # saves to data.txt, the filename extracted from the URL curl http://www.example.com/data.txt -O # saves to filename determined by the Content-Disposition header sent by the server. curl http://www.example.com/data.txt -O -J Either curl or wget can be used in this case. All 3 of these commands do the same thing, downloading the file at http://path/to/file.txt and saving it locally into «my_file.txt».
Note that in all commands below, I also recommend using the -L or —location option with curl in order to follow HTML 302 redirects to the new location of the file, if it has moved. wget requires no additional options to do this, as it does this automatically.
# save the file locally as my_file.txt wget http://path/to/file.txt -O my_file.txt # my favorite--it has a progress bar curl -L http://path/to/file.txt -o my_file.txt curl -L http://path/to/file.txt > my_file.txt Alternatively, to save the file as the same name locally as it is remotely, use either wget by itself, or curl with -O or —remote-name :
# save the file locally as file.txt wget http://path/to/file.txt curl -LO http://path/to/file.txt curl -L --remote-name http://path/to/file.txt Notice that the -O in the curl commands above is the capital letter «O».
The nice thing about the wget command is it shows a nice progress bar.
You can prove the files downloaded by each of the sets of 3 techniques above are exactly identical by comparing their sha512 hashes. Running sha512sum my_file.txt after running each of the commands above, and comparing the results, reveals all 3 files to have the exact same sha hashes (sha sums), meaning the files are exactly identical, byte-for-byte.
References
How to download a file into a directory using curl or wget? [closed]
Closed. This question does not meet Stack Overflow guidelines. It is not currently accepting answers.
This question does not appear to be about a specific programming problem, a software algorithm, or software tools primarily used by programmers. If you believe the question would be on-topic on another Stack Exchange site, you can leave a comment to explain where the question may be able to be answered.
curl -O example.com/file.zip wget example.com/file.zip curl -o mydir/file.zip example.com/file.zip wget -O mydir/file.zip example.com/file.zip curl -dir mydir example.com/file.zip 4 Answers 4
The following line will download all the files to a directory mentioned by you.
wget -P /home/test www.xyz.com Here the files will be downloaded to /home/test directory
If you are currently in a dir, say the Documents dir. With path Documents/home/test, the hyphen before «home» must be removed for wget to function.
I know this is an old question but it is possible to do what you ask with curl
rm directory/somefile.zip rmdir directory mkdir directory curl --http1.1 http://example.com/somefile.zip --output directory/somefile.zip first off if this was scripted you would need to make sure the file if it already exist is deleted then delete the directory then curl the download otherwise curl will fail with a file and directory already exist error.
This is exactly what was aleeady in the question. The question was for selecting a directoriy but keeping the file name.
The simplest way is to cd inside a subshell
(cd somedir; wget example.com/file.zip) and you could make that a shell function (e.g. in your ~/.bashrc )
then type wgetinside somedir http://example.com/file.zip
Short answer is no as curl and wget automatically writes to STDOUT. It does not have an option built into to place the download file into a directory.
-o/--output Write output to instead of stdout (Curl) -O, --output-document=FILE write documents to FILE. (WGet) But as it outputs to STDOUT natively it does give you programatic solutions such as the following:
The first i will define your url (example.com/file.zip) as a variable. The f= part removed the URL and leaves /file.zip and then you curl that file ($i) to the directory (~) as the file name.
How Do I Save a Curl Output to a File?
![]()
cURL is a Linux-based command which is the short form of “Client URL”. The cURL command is a command line utility that allows a programmer to transfer data over different networks. In simple words, it is a command that allows the transfer of data. It connects with the application server or web server by detailing a specific and relevant URL and the data that is to be received and sent. So, a cURL command acts as a tool to send and receive data between any two machines that are connected to the internet. It supports protocols like HTTP, FTP, SMTP, etc. cURL command has many applications and is used for many purposes because of its versatility. This tool helps us to download files and test APIs. It can also be used to debug errors related to the network. This command is powered by libcurl which itself is a very useful URL transfer library and is also free.
Syntax:
The syntax of the cURL command is as follows:
curl [OPTIONS] [URL]
The options parameter is used to tell the system for what purpose we will be using the command and the URL parameter takes the URL on which we will perform our command.
This command has two options: “-O” and “-o”. “-O” will save the file in the directory in which we will be standing at the time of operation. It will also keep the filename the same.
“-o” allows us to save the file with the name and directory of our choosing.
Example No. 1:
In the following example, we will use the curl command to download the file from the browser. For that, let us first install the curl package in our system. By running the command below in the terminal, we will start the installation of the curl package:
[ sudo ] password for linux:
Reading package lists. Done
Building dependency tree
Reading state information. Done
The following NEW packages will be installed:
curl
0 upgraded, 1 newly installed, 0 to remove and 0 not upgraded.
Need to get 161 kB of archives.
After this operation, 413 kB of additional disk space will be used.
Get: 1 http: // pk.archive.ubuntu.com / ubuntu focal-updates / main amd64 curl amd64 7.68.0-1ubuntu2.14 [ 161 kB ]
Fetched 161 kB in 2s ( 93.2 kB / s )
Selecting previously unselected package curl.
( Reading database . 188733 files and directories currently installed. )
Preparing to unpack . / curl_7.68.0-1ubuntu2.14_amd64.deb .
Unpacking curl ( 7.68.0-1ubuntu2.14 ) .
Setting up curl ( 7.68.0-1ubuntu2.14 ) .
Processing triggers for man-dB ( 2.9.1- 1 ) .
When we run the command above, it will ask us to enter the password. When we enter the correct password, it will start installing the new version of the curl package as shown above.
For downloading the file from the browser, it is necessary to have a link to that file from where it is going to be downloaded. Let us suppose we have a link to some pdf file and now we want it to be downloaded in our system. For downloading the file, we will run the command below:
linux@linux-VirtualBox:~$ curl -o linux.pdf https: // doc.lagout.org / operating % 20system % 20 / linux / Linux % 20- % 20The % 20Complete % 20Reference.pdf
In the command above, we passed the flag “-o” which instructs the compiler to rename the file. The second keyword “linux.pdf” is the name of the file which we want to be saved as the new filename in the directory. The last one is the link to the file that we are downloading.
When we run the command above, the output will be displayed on the terminal like the example below, which it will display the downloading details of the file.
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1562k 100 1562k 0 0 553k 0 0 :00:02 0 :00:02 —:—:— 553k
Now, we want to make sure that the file is downloaded or not. For that, we will go to our home directory as can be seen in the snippet below. The file with the file name “linux.pdf” has been downloaded successfully.
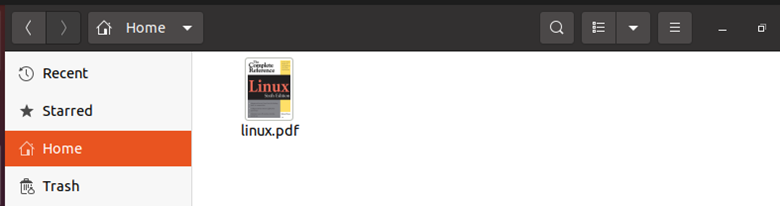
Example No. 2:
In this example, we will use the link of the same file that we have downloaded in example no 1. But this time, we will download the file with its original name. For that, we will run the command below:
linux@linux-VirtualBox:~$ curl https: // doc.lagout.org / operating % 20system % 20 / linux / Linux % 20- % 20The % 20Complete % 20Reference.pdf
One thing to notice in the command is that this time we have not included any flag or the name of the file to it which indicates that we are trying to save the file with its original name. After running the command above, the output shown below will be displayed on the terminal.
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 9127k 100 9127k 0 0 1067k 0 0 :00:08 0 :00:08 —:—:— 1132k
For checking whether the file is saved with the original file name or not we will check the home directory where the file will be stored. As can be seen below snippet,v the file is saved this time with its original name.
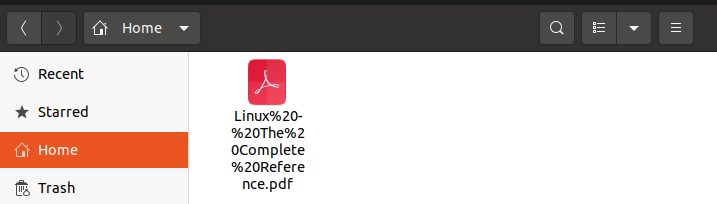
Example No. 3:
In this example, we will try to download multiple files using a single command and we will rename them according to our desire. So, we will try to download three files at a time with different names.
linux@linux-VirtualBox:~$ curl https: // doc.lagout.org / operating % 20system % 20 / linux / Linux % 20- % 20The % 20Complete % 20Reference.pdf https: // doc.lagout.org / operating % 20system % 20 / linux / Linux % 20- % 20The % 20Complete % 20Reference.pdf https: // doc.lagout.org / operating % 20system % 20 / linux / Linux % 20- % 20The % 20Complete % 20Reference.pdf
-o linux1.pdf
-o linux2.pdf
-o linux3.pdf
In the command above, we passed the same link three times to check whether it will download them multiple times for us or not. After passing the link using the flag “-o”, we renamed the files as “linux1.pdf”, “linux2.pdf” and “linux3.pdf”. The flag “-o” will be used each time while naming the files. When the command above is executed, it will display the following output in the terminal which shows the downloading details of all three files as shown below.
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 9127k 100 9127k 0 0 950k 0 0 :00:09 0 :00:09 —:—:— 1184k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 9127k 100 9127k 0 0 1133k 0 0 :00:08 0 :00:08 —:—:— 1209k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 9127k 100 9127k 0 0 975k 0 0 :00:09 0 :00:09 —:—:— 1088k
Now, let us check for all three files. For that, we will move to our home directory where all the files are downloaded as we can see below, the snippet all the files are successfully downloaded.
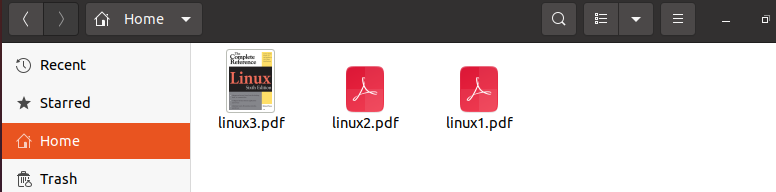
Conclusion
We have briefly studied the concept of the curl command and how it is used to download files from the browser just using a specified link of the file. Then, we discussed the basic syntax for the curl command and implemented different examples to make it easy to learn. You can also try more examples for a better idea of how it can be used to download files.
About the author
Omar Farooq
Hello Readers, I am Omar and I have been writing technical articles from last decade. You can check out my writing pieces.