- Linux cut command
- Syntax
- Options
- Usage Notes
- Specifying LIST
- Specifying A Delimiter Other Than Tab
- Examples
- Related commands
- 8 Cut Command Examples [Cut Sections of Line in File]
- cut Command Syntax
- 1. Print First Byte of File
- 2. Print Multiple Bytes of File
- 3. Print a Range of Bytes of File
- 4. Print Specify Start Byte Position of File
- 5. Print Specify End Byte Position of File
- 6. Cut First Byte by Character Position
- 7. Cut a String by Delimiter in Linux
- 8. Print All Bytes or Characters Except Selected Ones
Linux cut command

On Unix-like operating systems, the cut command removes («cuts out») sections of each line of a file or files.
This page covers the GNU/Linux version of cut.
Syntax
cut OPTION. [FILE].
Options
| -b, —bytes=LIST | Select only the bytes from each line as specified in LIST. LIST specifies a byte, a set of bytes, or a range of bytes; see Specifying LIST below. |
| -c, —characters=LIST | Select only the characters from each line as specified in LIST. LIST specifies a character, a set of characters, or a range of characters; see Specifying LIST below. |
| -d, —delimiter=DELIM | Use character DELIM instead of a tab for the field delimiter. |
| -f, —fields=LIST | Select only these fields on each line; also print any line containing no delimiter character, unless the -s option is specified. LIST specifies a field, a set of fields, or a range of fields; see Specifying LIST below. |
| -n | This option is ignored, but is included for compatibility reasons. |
| —complement | Complement the set of selected bytes, characters or fields. |
| -s, —only-delimited | Do not print lines not containing delimiters. |
| —output-delimiter=STRING | Use STRING as the output delimiter string. The default is to use the input delimiter. |
| —help | Display a help message and exit. |
| —version | Output version information and exit. |
Usage Notes
When invoking cut, use the -b, -c, or -f option, but only one of them.
If no FILE is specified, cut reads from the standard input.
Specifying LIST
Each LIST is made up of an integer, a range of integers, or multiple integer ranges separated by commas. Selected input is written in the same order that it is read, and is written to output exactly once. A range consists of:
| N | The Nth byte, character, or field, counted from 1. |
| N— | From the Nth byte, character, or field, to the end of the line. |
| N—M | From the Nth to the Mth byte, character, or field (inclusive). |
| —M | From the first to the Mth byte, character, or field. |
For example, let’s say you have a file named data.txt which contains the following text:
one two three four five alpha beta gamma delta epsilon
In this example, each of these words is separated by a tab character, not spaces. The tab character is the default delimiter of cut, so by default, it considers a field to be anything delimited by a tab.
To «cut» only the third field of each line, use the command:
. which outputs the following:
If instead you want to «cut» only the second-through-fourth field of each line, use the command:
. which outputs the following:
two three four beta gamma delta
To «cut» only the first-through-second and fourth-through-fifth field of each line (omitting the third field), use the command:
. which outputs the following:
one two four five alpha beta delta epsilon
Or, let’s say you want the third field and every field after it, omitting the first two fields. In this case, you could use the command:
. which outputs the following:
three four five gamma delta epsilon
Specifying a range with LIST also applies to cutting characters (-c) or bytes (-b) from a line. For example, to output only the third-through-twelfth character of every line of data.txt, use the command:
. which outputs the following:
Remember that the «space» between each word is actually a single tab character, so both lines of output are displaying ten characters: eight alphanumeric characters and two tab characters. In other words, cut is omitting the first two characters of each line, counting tabs as one character each; outputting characters three through twelve, counting tabs as one character each; and omitting any characters after the twelfth.
Counting bytes instead of characters results in the same output in this case, because in an ASCII-encoded text file, each character is represented by a single byte (eight bits) of data. So the command:
. for our file data.txt, produces the same output:
Specifying A Delimiter Other Than Tab
The tab character is the default delimiter that cut uses to determine what constitutes a field. So, if your file’s fields are already delimited by tabs, you don’t need to specify a different delimiter character.
You can specify any character as the delimiter, however. For instance, the file /etc/passwd contains information about each user on the system, one user per line, and each information field is delimited by a colon («:«). For example, the line of /etc/passwd for the root user may look like this:
These fields contain the following information, in the following order, separated by a colon character:
- Username
- Password (shown as x if encrypted)
- User ID number or UID
- Group ID number or GID
- Comment field (used by the finger command)
- Home Directory
- Shell
The username is the first field on the line, so to display each username on the system, use the command:
. which outputs, for example:
root daemon bin sys chope
(There are many more user accounts on a typical system, including many accounts specific to system services, but for this example, we pretend there are only five users.)
The third field of each line in the /etc/passwd file is the UID (user ID number), so to display each username and user ID number, use the command:
. which outputs the following, for example:
root:0 daemon:1 bin:2 sys:3 chope:1000
As you can see, the output is delimited, by default, using the same delimiter character specified for the input. In this case, that’s the colon character («:«). You can specify a different delimiter for the input and output, however. So, if you want to run the previous command, but have the output delimited by a space, you could use the command:
cut -f 1,3 -d ':' --output-delimiter=' ' /etc/passwd
root 0 daemon 1 bin 2 sys 3 chope 1000
But what if you want the output to be delimited by a tab? Specifying a tab character on the command line is a bit more complicated, because it is an unprintable character. To specify it on the command line, you must «protect» it from the shell. This is done differently depending on which shell you’re using, but in the Linux default shell (bash), you can specify the tab character with $’\t’. So the command:
cut -f 1,3 -d ':' --output-delimiter=$'\t' /etc/passwd
. outputs the following, for example:
root 0 daemon 1 bin 2 sys 3 chope 1000
Examples
Output the third character of every line of the file file.txt, omitting the others.
Output the first three characters of every line of the file file.txt, omitting the rest.
Same as the above command. Output the first three characters of every line of file.txt.
Output the third through the last characters of each line of the file file.txt, omitting the first two characters.
Output the first field of the file /etc/passwd, where fields are delimited by a colon (‘:‘). The first field of /etc/passwd is the username, so this command outputs every username in the passwd file.
grep '/bin/bash' /etc/passwd | cut -d ':' -f 1,6
Output the first and sixth fields, delimited by a colon, of any entry in the /etc/passwd file which specifies /bin/bash as the login shell. This command outputs the username and home directory of any user whose login shell is /bin/bash.
Related commands
grep — Filter text which matches a regular expression.
paste — Merge corresponding lines of files.
8 Cut Command Examples [Cut Sections of Line in File]
As Linux users, we interact with the text files on a regular basis. One of the common operations we perform on these files is text filtering. Linux provides many command-line utilities for text filtering, such as – grep, fgrep, sed, awk, and the list goes on.
However, in this guide, we will discuss one more text-filtering utility called cut, which is used to remove a particular section from the input line. The cut command performs filtering based on the byte position, character, field, and delimiter.
In this beginner’s guide, we will learn about the cut command with examples in the Linux command line. After following this guide Linux command line users will be able to use the cut command efficiently in their day-to-day life.
cut Command Syntax
The syntax of the cut command is just like any other Linux command:
In the above syntax, the angular bracket (<>) represents the mandatory arguments whereas the square bracket ([]) represents the optional parameters.
Now that we are familiar with the syntax of the cut command. Next, let’s create a sample file to use as an example:
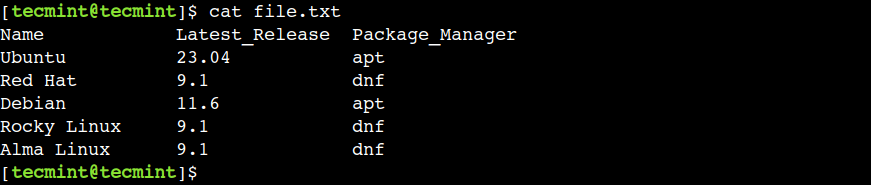
1. Print First Byte of File
The cut command allows us to extract the text based on byte position using the -b option.
Let’s use the below command to extract the first byte from each line of the file:
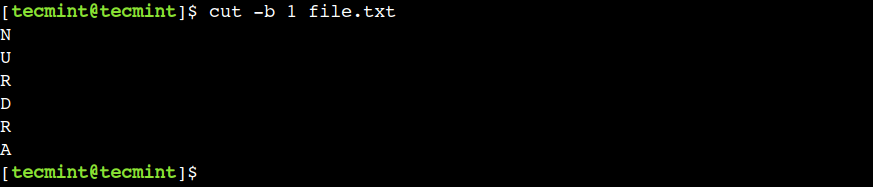
In this example, we can see that the cut command shows only the first character because all characters are one byte long.
2. Print Multiple Bytes of File
In the previous example, we saw how to select a single byte from the file. However, the cut command also allows us to select multiple bytes using the comma.
Let us use the below command to select the first four bytes from the file:
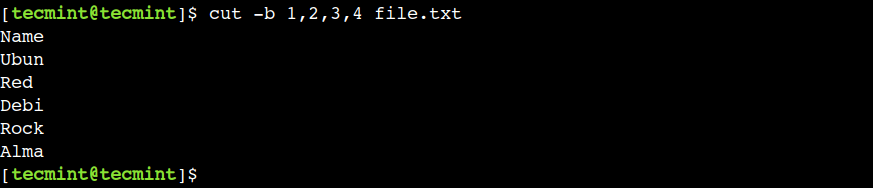
In this example, we have selected the consecutive bytes but that is not mandatory. We can use any valid byte position with the cut command.
3. Print a Range of Bytes of File
In the previous example, we used commas to select consecutive bytes. However, that approach is not suitable if we want to select a large number of bytes consecutively. In such cases, we can use the hyphen (-) to specify the byte range.
To understand this, let’s use the 1-12 as a byte range to select the first twelve bytes from each line:
In a similar way, we can select a byte range from the middle as well. For example, the below command selects bytes from column numbers 17 to 30:
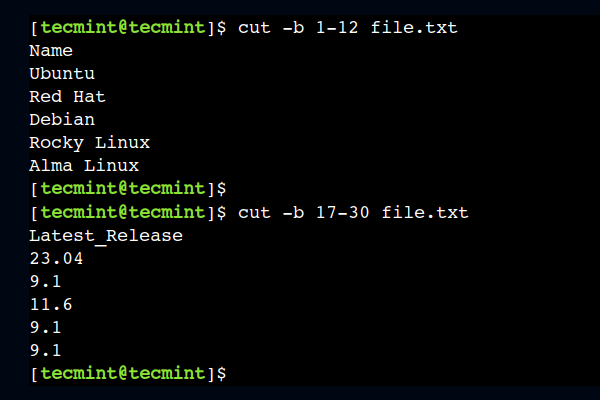
4. Print Specify Start Byte Position of File
Sometimes, we want to extract all the text from a certain byte position. In such cases, we can omit the end byte position.
For example, we can use the following command to print all bytes starting from position 17:
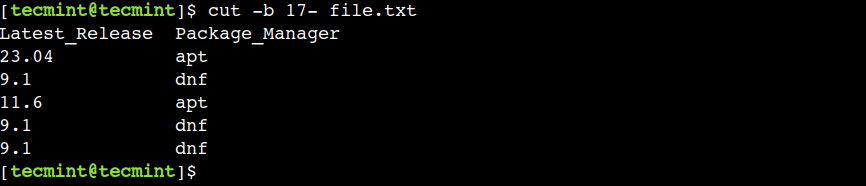
In the above command, 17 represents the starting byte position whereas the hyphen (-) represents the end of the line.
5. Print Specify End Byte Position of File
In a similar way, we can also specify the end byte position only. For example, the below command prints all the bytes from the start of the line till the 12th column:
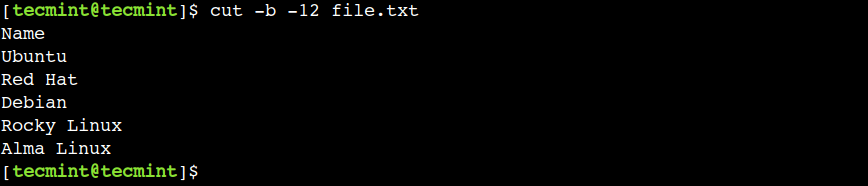
In the above command, the hyphen (-) represents the start of the line whereas 12 represents the end byte position.
6. Cut First Byte by Character Position
In the last few sections, we saw how to perform text extraction based on byte position. Now, let’s see how to perform the text extraction by character position.
To achieve this, we can use the -c option to cut the first byte from the following multi-byte string:
$ echo école | cut -b 1 �
In the above output, we can see that, the cut command shows a question mark instead of the character é . This happens because we are trying to print the first byte from the multi-byte character.
Now, let’s use the -c option to cut the same multi-byte character and observe the result:
$ echo école | cut -c 1 é
In the above output, we can see that now the cut command shows the expected output.
It is important to note that, not all versions of the cut commands support the multi-byte characters. For example, Ubuntu and its derivatives don’t support multi-byte characters.
To understand this, let’s run the same command on the Linux Mint which is derived from Ubuntu:

Here we can see that, the cut command treats both multi-byte characters and single-byte characters the same. Hence it doesn’t generate the expected output.
7. Cut a String by Delimiter in Linux
By default, the cut command uses a TAB character as a delimiter. However, we can override this default behavior using the -d option.
Oftentimes, the -d option is used in combination with the -f option which is used to select a particular field.
To understand this, let’s use the space character as a delimiter and print the first two fields using the -f option:
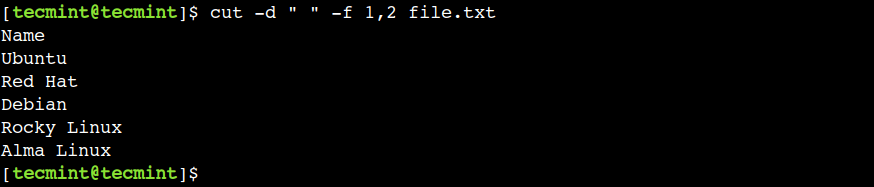
In the above example, we have used the comma with the -f option to select multiple fields.
8. Print All Bytes or Characters Except Selected Ones
Sometimes, we want to print all the characters except a few ones. In such cases, we can use the —complement option. As the name suggests, this option prints all the columns except the specified ones.
$ cut -c 1 --complement file.txt
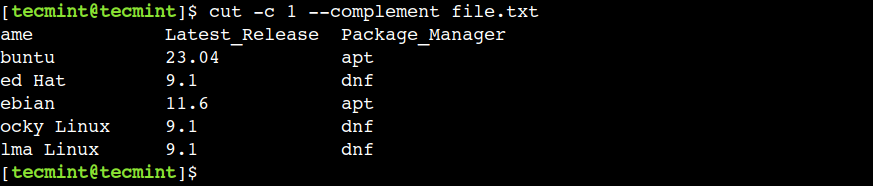
In the above output, we can see that the —complement option prints all the characters except the first character.
It is important to note that, in this example, we have used commas to select multiple fields. However, we can also use the other supported ranges as well. We can refer to the first few examples of this tutorial to understand more about the ranges.
Conclusion
In this beginner’s guide, we discussed the practical examples of the cut command with text filtering based on the byte position, character position, and delimiter.
Do you know of any other best example of the cut command in Linux? Let us know your views in the comments below.