- How can I strip first X characters from string using sed?
- 11 Answers 11
- 8 Cut Command Examples [Cut Sections of Line in File]
- cut Command Syntax
- 1. Print First Byte of File
- 2. Print Multiple Bytes of File
- 3. Print a Range of Bytes of File
- 4. Print Specify Start Byte Position of File
- 5. Print Specify End Byte Position of File
- 6. Cut First Byte by Character Position
- 7. Cut a String by Delimiter in Linux
- 8. Print All Bytes or Characters Except Selected Ones
How can I strip first X characters from string using sed?
I am writing shell script for embedded Linux in a small industrial box. I have a variable containing the text pid: 1234 and I want to strip first X characters from the line, so only 1234 stays. I have more variables I need to «clean», so I need to cut away X first characters and $
If $
If these pid’s are always integers, then selecting the number directly with regex will be a better, simpler solutioin than trying to remove a specific number of chacters from the start. I provided an answer to this effect, but it’s being downvoted, because it doesn’t do specifically what you’ve asked for. However, what you’ve asked may not be the best way to solve this particular problem.
11 Answers 11
The following should work:
Are you sure bash is the shell executing your script?
would be preferable to using an external process, although this requires you to hard-code the 5 in the form of a fixed-length pattern.
Here’s a concise method to cut the first X characters using cut(1) . This example removes the first 4 characters by cutting a substring starting with 5th character.
Technically the OP asked for sed, but I feel like this is the best solution for «How can I strip the first X characters from string [in a terminal/bash]» When used in combination with git, it is nice: git log —pretty=oneline | cut -c 42- | head
+1 Simple and helpful solution.. When I had the URL as http://
Santosh Kumar Arjunan: that’s because the example «echo «$pid» | cut -c 4-» is actualy not cuting first 4 characters but extracts substring starting from 4th character. Therefore it actually cuts first 3 characters. Thus, if you want to cut 7 first characters, you want to extract everything from 8th character and thus indeed do «cut -c 8-«
@DeanHiller cut -c $
Use the -r option («use extended regular expressions in the script») to sed in order to use the syntax:
$ echo 'pid: 1234'| sed -r 's/^.//' 1234 You can do it without the -r ( -E in OS X, IIRC) if you escape the braces (don’t know if that works in OS X, though).
Cut first two characters from string:
$ string="1234567890"; echo "$" 34567890 pipe it through awk » where 42 is one more than the number of characters to drop. For example:
Chances are, you’ll have cut as well. If so:
[me@home]$ echo "pid: 1234" | cut -d" " -f2 1234 Trouble with cut is that it doesn’t handle sequences of whitespace sensibly, using tr -s ‘ ‘ to «squeeze» spaces makes it behave better.
It’s not meant to be an all singing all dancing tool; it is simple and does as it says on the can and is widely available. It should work just fine for said requirements, and is certainly more robust that cropping out fixed characters from specific positions.
Well, there have been solutions here with sed , awk , cut and using bash syntax. I just want to throw in another POSIX conform variant:
$ echo "pid: 1234" | tail -c +6 1234 -c tells tail at which byte offset to start, counting from the end of the input data, yet if the the number starts with a + sign, it is from the beginning of the input data to the end.
I really like this answer because it does exactly what OP asked for without using overcomplicated tools.
Another way, using cut instead of sed .
I found the answer in pure sed supplied by this question (admittedly, posted after this question was posted). This does exactly what you asked, solely in sed:
The dot in sed ‘/./ ) is whatever you want to match. Your question is exactly what I was attempting to, except in my case I wanted to match a specific line in a file and then uncomment it. In my case it was:
# Uncomment a line (edit the file in-place): sed -i '/#\ COMMENTED_LINE_TO_MATCH/ < s/#\ //g; >' /path/to/target/file The -i after sed is to edit the file in place (remove this switch if you want to test your matching expression prior to editing the file).
(I posted this because I wanted to do this entirely with sed as this question asked and none of the previous answered solved that problem.)
8 Cut Command Examples [Cut Sections of Line in File]
As Linux users, we interact with the text files on a regular basis. One of the common operations we perform on these files is text filtering. Linux provides many command-line utilities for text filtering, such as – grep, fgrep, sed, awk, and the list goes on.
However, in this guide, we will discuss one more text-filtering utility called cut, which is used to remove a particular section from the input line. The cut command performs filtering based on the byte position, character, field, and delimiter.
In this beginner’s guide, we will learn about the cut command with examples in the Linux command line. After following this guide Linux command line users will be able to use the cut command efficiently in their day-to-day life.
cut Command Syntax
The syntax of the cut command is just like any other Linux command:
In the above syntax, the angular bracket (<>) represents the mandatory arguments whereas the square bracket ([]) represents the optional parameters.
Now that we are familiar with the syntax of the cut command. Next, let’s create a sample file to use as an example:
1. Print First Byte of File
The cut command allows us to extract the text based on byte position using the -b option.
Let’s use the below command to extract the first byte from each line of the file:
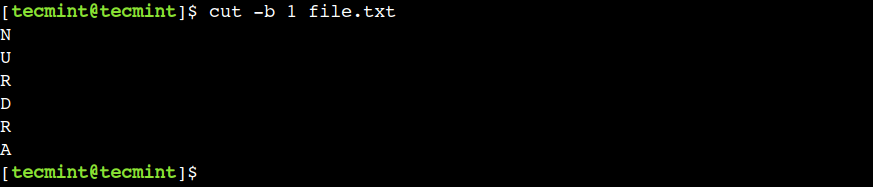
In this example, we can see that the cut command shows only the first character because all characters are one byte long.
2. Print Multiple Bytes of File
In the previous example, we saw how to select a single byte from the file. However, the cut command also allows us to select multiple bytes using the comma.
Let us use the below command to select the first four bytes from the file:
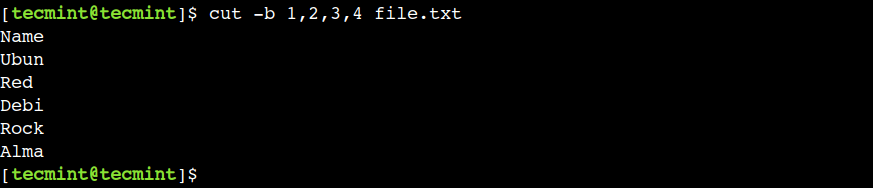
In this example, we have selected the consecutive bytes but that is not mandatory. We can use any valid byte position with the cut command.
3. Print a Range of Bytes of File
In the previous example, we used commas to select consecutive bytes. However, that approach is not suitable if we want to select a large number of bytes consecutively. In such cases, we can use the hyphen (-) to specify the byte range.
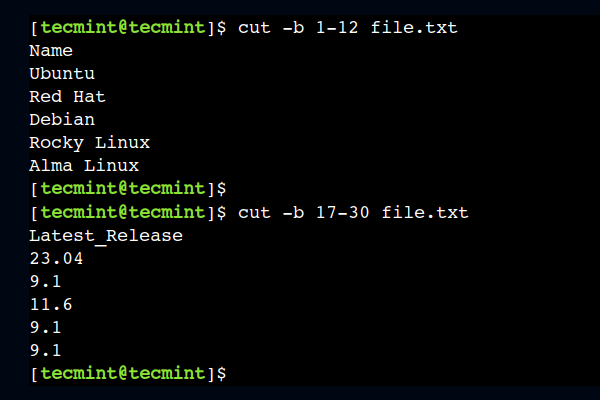
To understand this, let’s use the 1-12 as a byte range to select the first twelve bytes from each line:
In a similar way, we can select a byte range from the middle as well. For example, the below command selects bytes from column numbers 17 to 30:
4. Print Specify Start Byte Position of File
Sometimes, we want to extract all the text from a certain byte position. In such cases, we can omit the end byte position.
For example, we can use the following command to print all bytes starting from position 17:
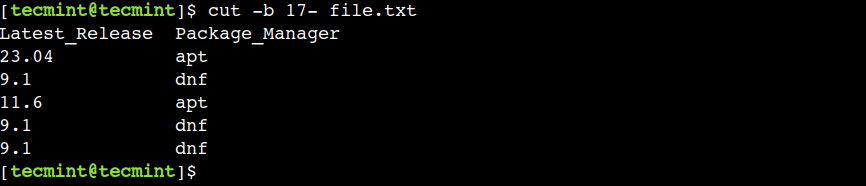
In the above command, 17 represents the starting byte position whereas the hyphen (-) represents the end of the line.
5. Print Specify End Byte Position of File
In a similar way, we can also specify the end byte position only. For example, the below command prints all the bytes from the start of the line till the 12th column:
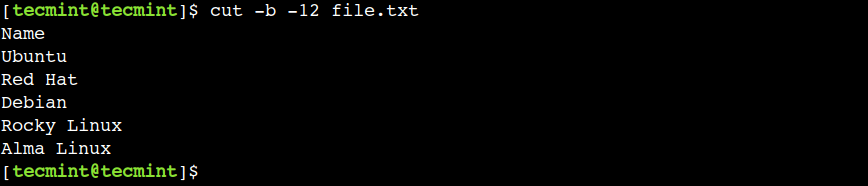
In the above command, the hyphen (-) represents the start of the line whereas 12 represents the end byte position.
6. Cut First Byte by Character Position
In the last few sections, we saw how to perform text extraction based on byte position. Now, let’s see how to perform the text extraction by character position.
To achieve this, we can use the -c option to cut the first byte from the following multi-byte string:
$ echo école | cut -b 1 �
In the above output, we can see that, the cut command shows a question mark instead of the character é . This happens because we are trying to print the first byte from the multi-byte character.
Now, let’s use the -c option to cut the same multi-byte character and observe the result:
$ echo école | cut -c 1 é
In the above output, we can see that now the cut command shows the expected output.
It is important to note that, not all versions of the cut commands support the multi-byte characters. For example, Ubuntu and its derivatives don’t support multi-byte characters.
To understand this, let’s run the same command on the Linux Mint which is derived from Ubuntu:

Here we can see that, the cut command treats both multi-byte characters and single-byte characters the same. Hence it doesn’t generate the expected output.
7. Cut a String by Delimiter in Linux
By default, the cut command uses a TAB character as a delimiter. However, we can override this default behavior using the -d option.
Oftentimes, the -d option is used in combination with the -f option which is used to select a particular field.
To understand this, let’s use the space character as a delimiter and print the first two fields using the -f option:
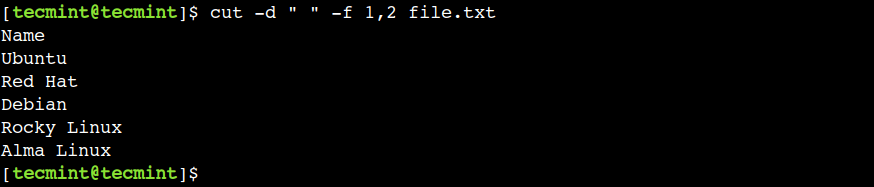
In the above example, we have used the comma with the -f option to select multiple fields.
8. Print All Bytes or Characters Except Selected Ones
Sometimes, we want to print all the characters except a few ones. In such cases, we can use the —complement option. As the name suggests, this option prints all the columns except the specified ones.
$ cut -c 1 --complement file.txt
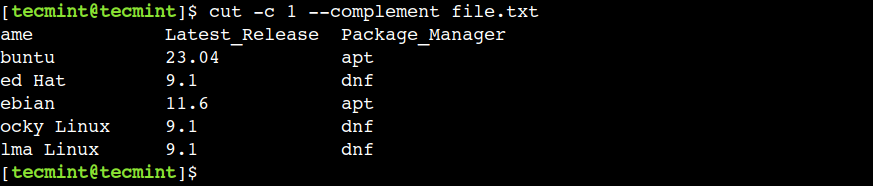
In the above output, we can see that the —complement option prints all the characters except the first character.
It is important to note that, in this example, we have used commas to select multiple fields. However, we can also use the other supported ranges as well. We can refer to the first few examples of this tutorial to understand more about the ranges.
Conclusion
In this beginner’s guide, we discussed the practical examples of the cut command with text filtering based on the byte position, character position, and delimiter.
Do you know of any other best example of the cut command in Linux? Let us know your views in the comments below.