- How do I delete the first n lines of an ascii file using shell commands?
- 7 Answers 7
- sed
- tail
- awk
- By percentage
- Sed Command to Delete a Line
- Sed on Linux
- Deleting line using sed
- Delete single line
- Delete a range of line
- Delete multiple lines
- Delete all lines except specified range
- Delete empty lines
- Delete lines based on pattern
- Delete lines starting with a specific character
- Delete lines ending with specific character
- Deleting lines that match the pattern and the next line
- Deleting line from the pattern match to the end
- Final thought
- About the author
- Sidratul Muntaha
- Delete First line of a file
- 11 Answers 11
- Remove First n Lines of a Large Text File
How do I delete the first n lines of an ascii file using shell commands?
I have multiple files that contain ascii text information in the first 5-10 lines, followed by well-tabulated matrix information. In a shell script, I want to remove these first few lines of text so that I can use the pure matrix information in another program. How can I use bash shell commands to do this? If it’s any help, I’m using RedHat and an Ubuntu linux systems.
7 Answers 7
As long as the file is not a symlink or hardlink, you can use sed, tail, or awk. Example below.
sed
You can also use sed in-place without a temp file: sed -i -e 1,3d yourfile . This won’t echo anything, it will just modify the file in-place. If you don’t need to pipe the result to another command, this is easier.
tail
awk
You can also use sed in-place without a temp file: sed -i -e 1,3d yourfile . This won’t echo anything, it will just modify the file in-place. If you don’t need to pipe the result to another command, this is easier.
@Svetlana sed -i specifically. Most implementations just delete the file and replace it with a new one, which doesn’t work for links since you end up leaving the original at its other location.
how about explaining what ‘1,3d’, +4, et.c. means? The question was for n lines, but you didn’t tell what n is (as apparently n is 2 in your examples, though it’s not obvious for a noob what to change in order to change n)
This uses a temp file so not very useful for a 100% util disk space. Would be interesting to have a solution that does this literally «in-place».
This deletes first 3 line from file.txt.
I need to remove the 50 first lines from a 10GB+ text file. Even if it’s supposed to work «in-place», this command still takes a few minutes. Is there any really fast alternative ?
@Sébastien if you only have to remove the 50 first lines, open the file in a text editor, select the 50 first lines and delete them maybe? It took 17 seconds to remove the 8 473 386 first lines of a 7GB+ text files with this command, I have to admit I find it quite fast.
If you have a 10GB log file and only ~1GB left of space, this solution won’t work as creates a tmp file
If the tabulated lines are the ones that have a tab character:
( ␉ being a literal tab character) or equivalently
In a bash/ksh/zsh script, you can write $’\t’ for a tab, e.g. grep $’\t’ or sed -n $’/\t/p’ .
If you want to eliminate 10 lines at the beginning of the file:
(note that it’s +11 to eliminate 10 lines, because +11 means “start from line 11” and tail numbers lines from 1) or
On Linux, you can take advantage of GNU sed’s -i option to modify files in place:
Or you can use a shell loop and temporary files:
for x in *.txt; do tail -n +11 "$x.tmp" mv "$x.tmp" "$x" done Or if you don’t want to modify the files in place, but instead give them a different name:
for x in *.txt; do tail -n +11 "$.data" done @IgnacioVazquez-Abrams I know. The pretty-printed table sometimes uses tab characters, that’s easier to spot than aligned columns. Of course, if Paul gave a sample input, I could give a better matcher.
You can use Vim in Ex mode:
By percentage
Using bash , to clean up a file using a percentage number instead of an absolute number of lines:
sed -i -e 1,$( printf "$((`cat php_errors.log | wc -l` * 75 /100 ))" )d php_errors.log Watch out because that command can be destructive since it deletes content in-place, without creating a copy.
It deletes the first 75% of lines from the mentioned file.
# deletes first line echo "a\nb" | sed '1d' # read list.txt and write list.csv without first line cat list.txt | sed '1d' > list.csv # finds first character (pipe|) grep '^|' # deletes pipe sed 's/|//g' # deletes space sed 's/ //g' i created a small script which will delete everything from the /var/log/messages except last 4 lines.
# cat remove-range-of-lines.sh
#!/usr/bin/bash #print total line number line_count=`awk 'END' /var/log/messages` #exclude last 4 lines remove_line=`expr $line_count - 4` #remove everything except last 4 lines sed -i '1,'$remove_line'd' /var/log/messages
using this script we can always keep latest entry in the /var/log/messages based on our requirement
if you want to keep last 10000 entries in the /var/log/messages below is the modified script.
#!/usr/bin/bash #print total line number line_count=`awk 'END' /var/log/messages` #exclude last 10000 lines remove_line=`expr $line_count - 10000` #remove everything except last 10000 lines sed -i '1,'$remove_line'd' /var/log/messages
Sed Command to Delete a Line
![]()
Sed is a built-in Linux tool for text manipulation. The term sed stands for stream editor. Despite the name, sed isn’t a text editor by itself. Rather, it takes text as input, performs various text modifications according to instructions, and prints the output.
This guide will demonstrate how to use sed to delete a line from a text.
Sed on Linux
The full name of sed gives us a hint at its working method. Sed takes the input text as a stream. The text can come from anywhere – a text file or standard output (STDOUT). After taking the input, sed operates on it line by line.
For demonstration, here’s a simple text file I’ve generated.
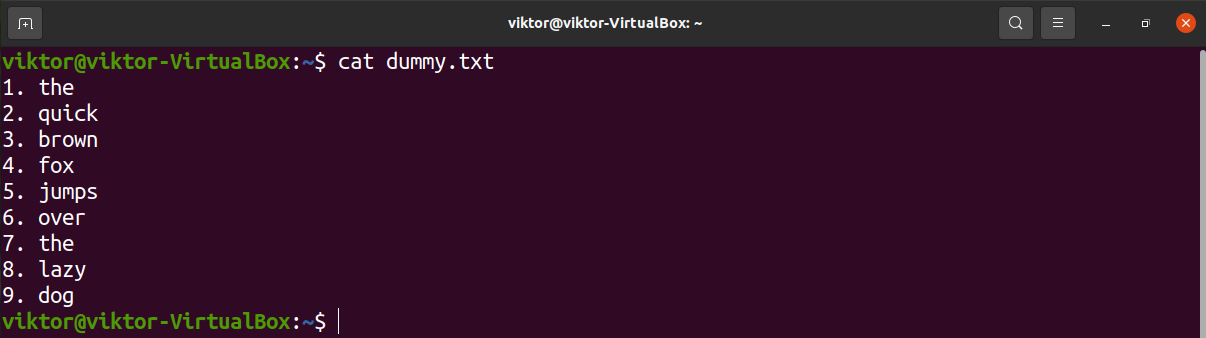
Deleting line using sed
To delete a line, we’ll use the sed “d” command. Note that you have to declare which line to delete. Otherwise, sed will delete all the lines.
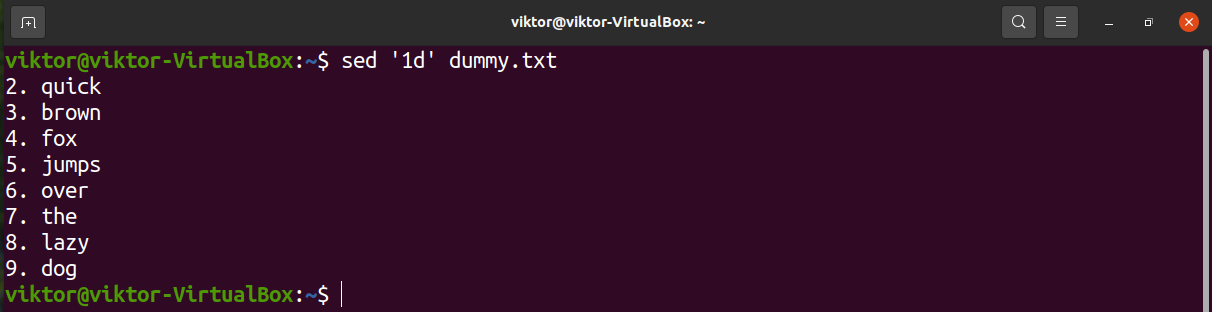
Delete single line
The following sed command will delete the first line of the text.
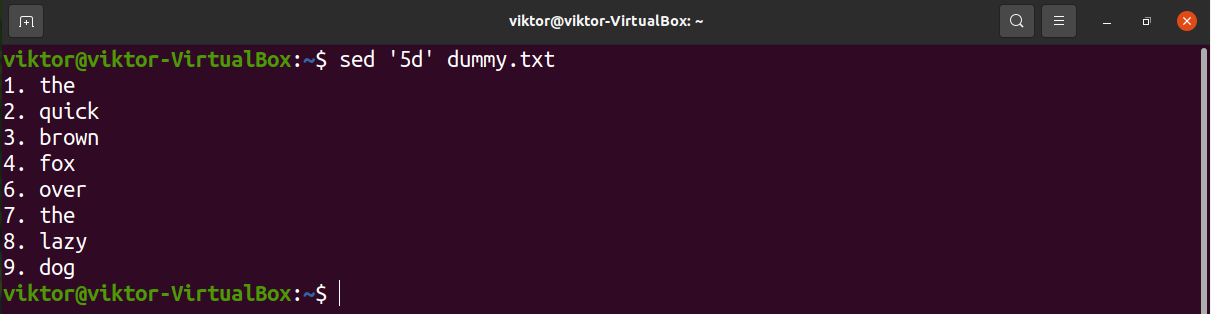
Basically, to delete a line, you need the line number of the target line. Let’s remove line 5.
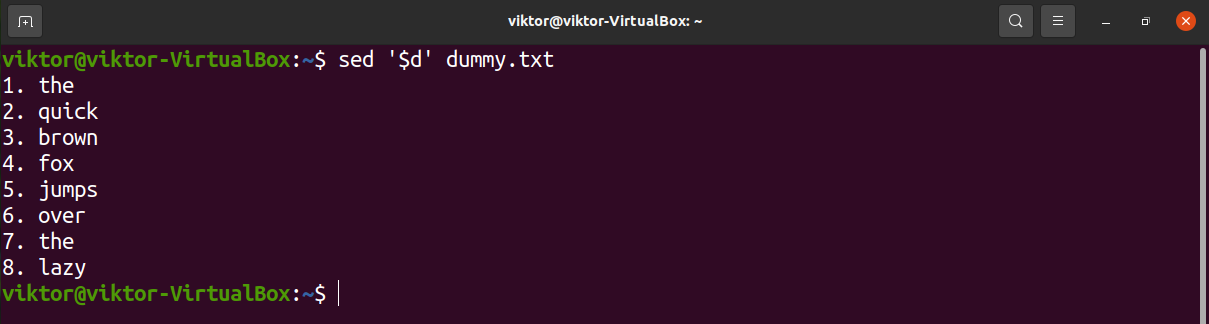
To delete the last line of the text file, instead of manually calculating the line number, use “$” instead.
Delete a range of line
Sed can delete a range of lines. Here, the minimum line value is 1, and the maximum line value is 5. To declare range, we’re using comma (,).

Delete multiple lines
What if the lines you desire to remove are not in a fixed range? Have a look at the following sed command. Note that we’re using a semicolon (;) as the delimiter. Essentially, each delimited option is a separate sed command.

Delete all lines except specified range
In the next example, sed will only keep the lines described by the range. Here, “!” is the negation operator, telling sed to keep the specific lines.

Delete empty lines
If there are multiple empty or blank lines in the text, the following sed command will remove all of them.
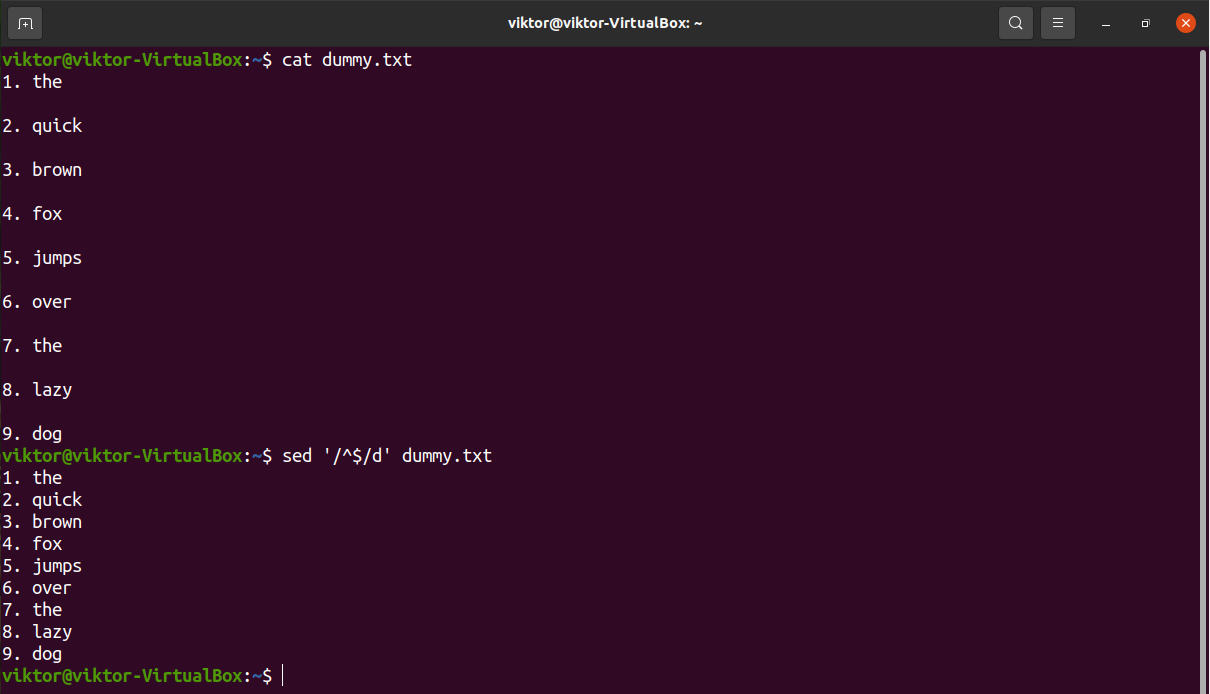
Delete lines based on pattern
Sed can search for a particular pattern and perform the specified actions on the line. We can use this feature to delete specific lines that match a pattern.
Let’s have a look at the following demonstration. Sed will remove any line that contains the string “the”.
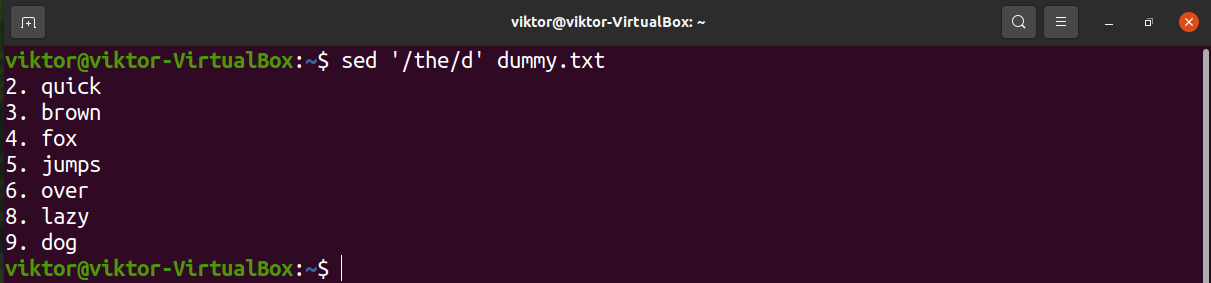
We can also describe multiple strings to search for. Each string is delimited using the symbol “\|”.

Delete lines starting with a specific character
To denote the starting of a line, we’ll use the caret (^) symbol.
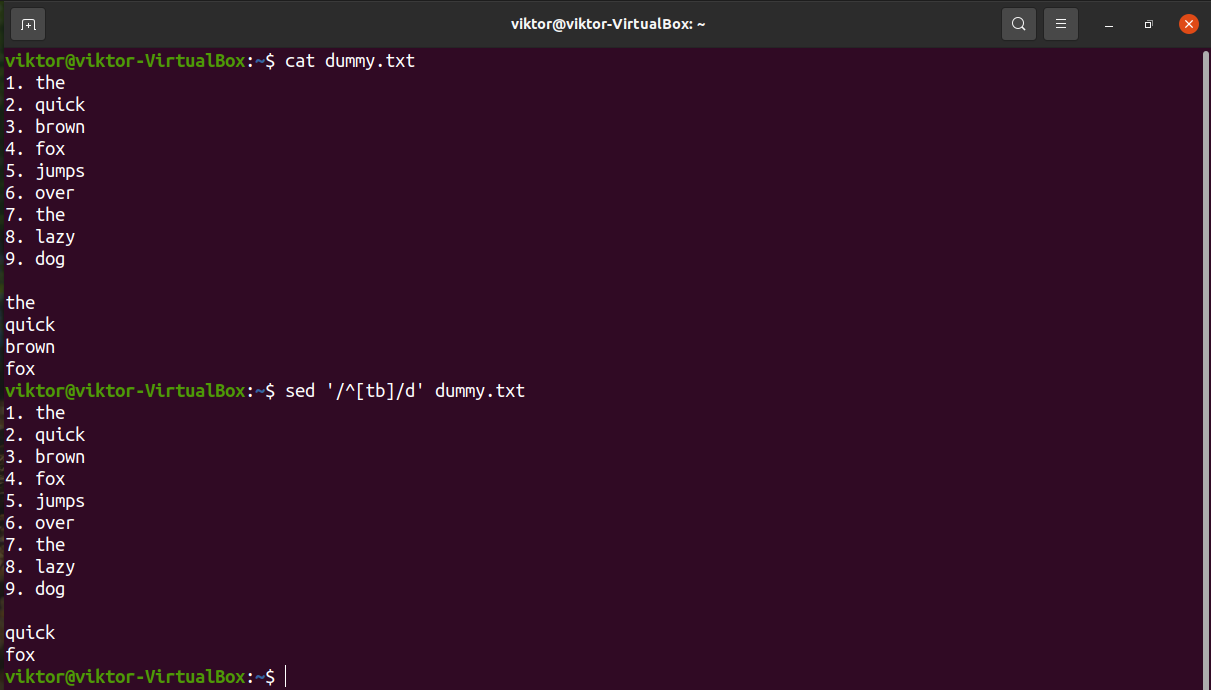
The following sed command will remove all the lines starting with a digit. Here, the character group “[:digit:]” describes all digits (0-9).

We can also describe multiple characters for a valid match. The following example will match all the lines that start with “t” and “b”.
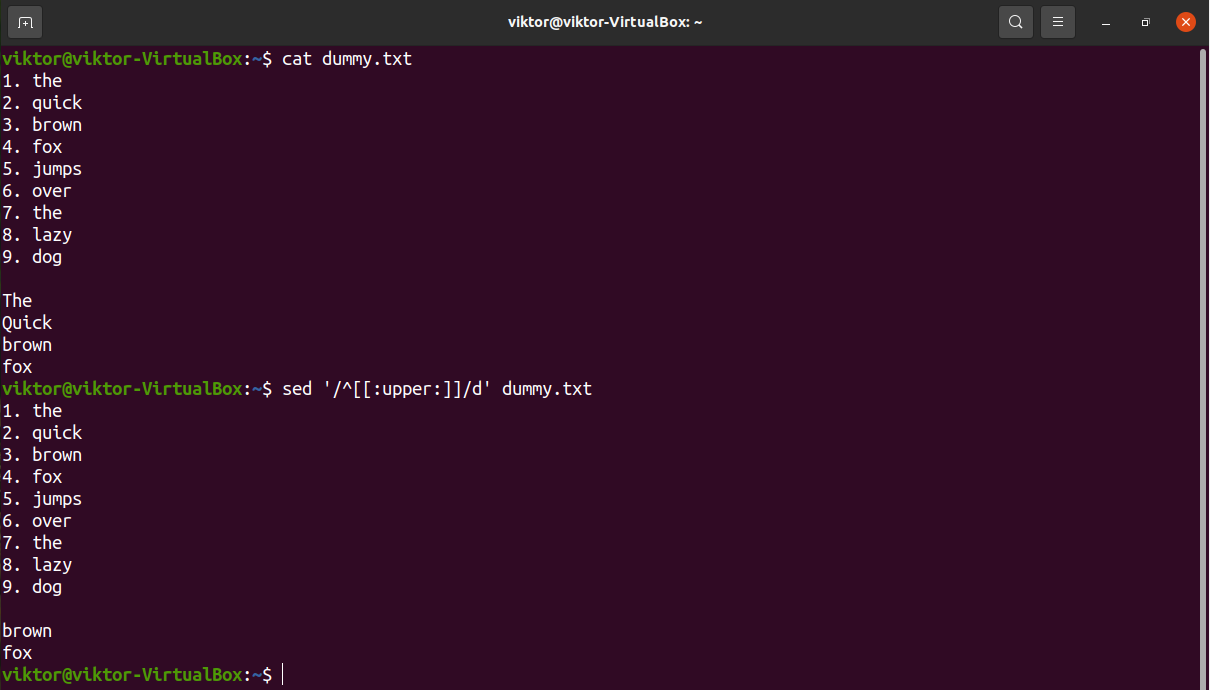
In the next example, check out how to remove all the lines that start with an uppercase character. Here, we’re using the uppercase character group “[:upper:]”.
If the target lines have lowercase characters at the start, use the lowercase character group “[:lower:]”.
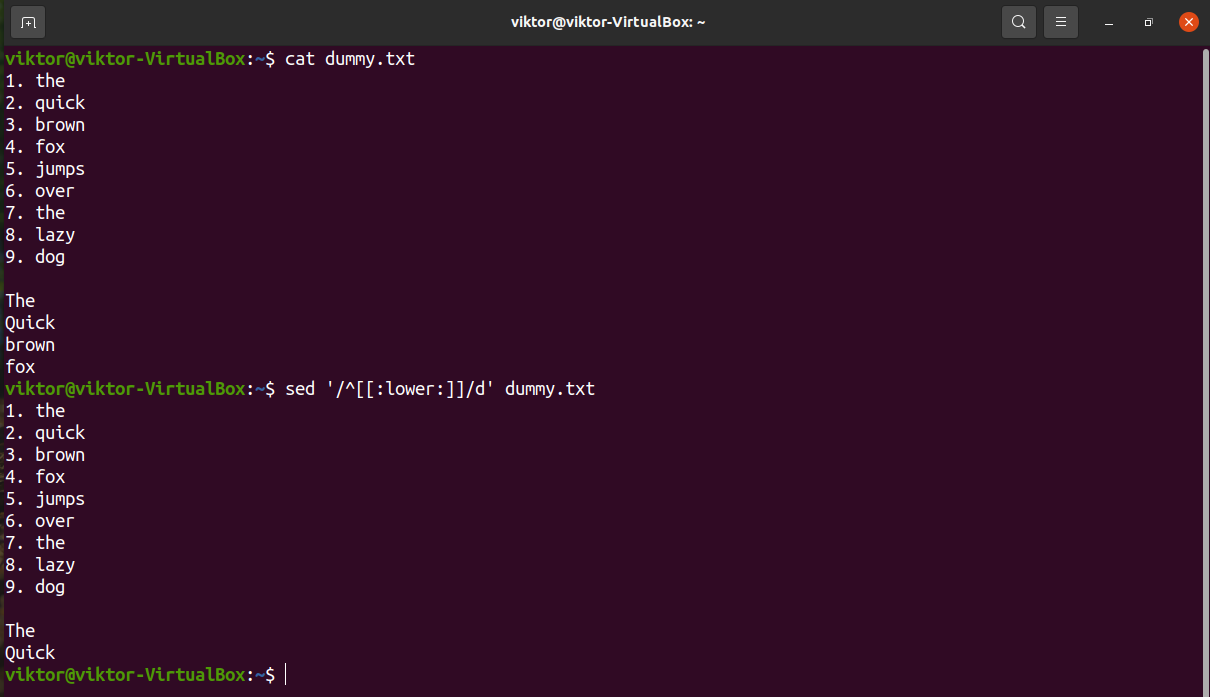
Delete lines ending with specific character
To denote the end of a line, we can use the symbol “$”. It describes the match with the last occurrence of the pattern.
In the next example, sed will delete lines ending with “e”.
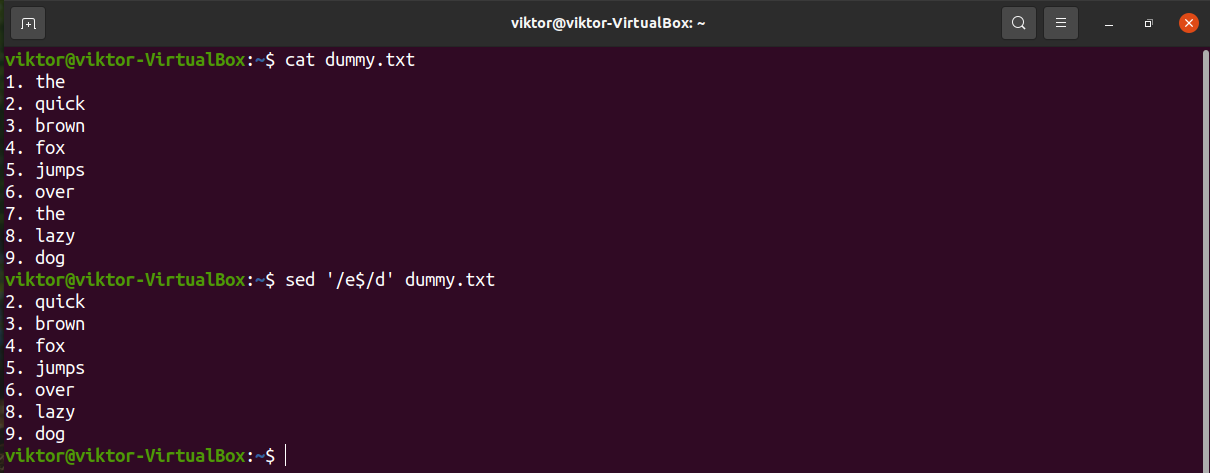
Let’s try with a multiple-character search.
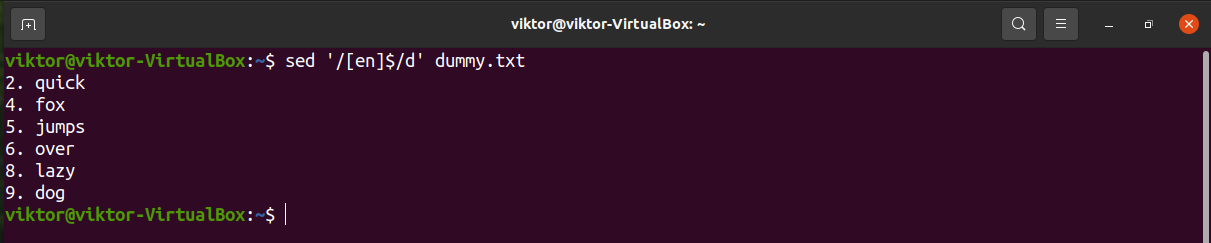
Deleting lines that match the pattern and the next line
We’ve already demonstrated how to delete a line if a pattern matches. We can further extend and delete the subsequent line as well.
Check out the following sed command.

Sed will match the line that contains “the” and delete the subsequent line as well.
Deleting line from the pattern match to the end
We can further extend the previous example to order sed to delete all the lines, starting from the first match of the pattern.

Here, sed will delete the line that matches the pattern “the” first and all lines afterward.
Final thought
Sed is a simple tool. However, it can do wonders, thanks to the support for regular expression. Sed also integrates seamlessly in various scripts.
This was just a short guide demonstrating one of the sed functions – deleting lines. There are tons of other things you can do with sed. For example, check out this mega guide on 50 sed examples. It’s a fantastic guide covering all the basics and many advanced sed implementations.
About the author
Sidratul Muntaha
Student of CSE. I love Linux and playing with tech and gadgets. I use both Ubuntu and Linux Mint.
Delete First line of a file
How can I delete the first line of a file and keep the changes? I tried this but it erases the whole content of the file.
11 Answers 11
An alternative very lightweight option is just to ‘tail’ everything but the first line (this can be an easy way to remove file headers generally):
# -n +2 : start at line 2 of the file. tail -n +2 file.txt > file.stdout Following @Evan Teitelman, you can:
tail -n +2 file.txt | sponge file.txt To avoid a temporary file. Another option might be:
echo "$(tail -n +2 file.txt)" > file.txt And so forth. Testing last one:
[user@work ~]$ cat file.txt line 1 line 2 line 3 line 4 line 5 [user@work ~]$ echo "$(tail -n +2 file.txt)" > file.txt [user@work ~]$ cat file.txt line 2 line 3 line 4 line 5 [user@work ~]$ Oops we lost a newline (per @1_CR comment below), try instead:
printf "%s\n\n" "$(tail -n +2 file.txt)" > file.txt [user@work ~]$ cat file.txt line 1 line 2 line 3 line 4 line 5 [user@work ~]$ printf '%s\n\n' "$(tail -n +2 file.txt)" > file.txt [user@work ~]$ cat file.txt line 2 line 3 line 4 line 5 [user@work ~]$ printf '%s\n\n' "$(sed '1d' file.txt)" > file.txt echo -e "$(sed '1d' file.txt)\n" > file.txt I’ve just tried it on my Fedora system and the output is above. You are correct — thanks for pointing that out.
The reason file.txt is empty after that command is the order in which the shell does things. The first thing that happens with that line is the redirection. The file «file.txt» is opened and truncated to 0 bytes. After that the sed command runs, but at the point the file is already empty.
There are a few options, most involve writing to a temporary file.
sed '1d' file.txt > tmpfile; mv tmpfile file.txt # POSIX sed -i '1d' file.txt # GNU sed only, creates a temporary file perl -ip -e '$_ = undef if $. == 1' file.txt # also creates a temporary file Remove First n Lines of a Large Text File
Awesome answer, fantastic use of tail . I found many times something new to learn from your answers. thanks.
Oh man tail -n +43 is a game changer! I’ve been using an awkward invocation of sed to the same effect.
What if you have no space left on device? sed -i 1,50000000d 17GigFile creates a temp file sedXYZ that consumes many more gigabytes. Is there an approach without temp files?
@juanmf You might try to do this with a gui tool (I’ve done it using Mousepad, but the file of interest was «only» ~700MB. Takes awhile for the file to load, though.
This seems to be the easiest:
sed '1,42d' test.sql > test2.sql Remove lines 1-42 from test.sql and save as test2.sql
tail -n +43 dump.sql > dump_new.sql
You can use Vim in Ex mode:
Does it create a temp file? Is it possible to do this when space left on device is less than file size?
@juanmf All these solutions require a temporary file. It is only possible to remove data from the end of a file without using a temporary file.
@PerlDuck could you please elaborate on why (or link ressource) «It is only possible to remove data from the end of a file without using a temporary file» ?
Because of sed discrepancies across Linux and Mac, I resolved to use tail -n +43 dump.sql > new.sql format.
Won’t work becuase > dump.sql is interpreted by the shell before tail . dump.sql reads the file, i.e. the file is flushed before tail opens it, hence the file is completely empty after that command.
@PerlDuck I must have probably used another file name at the time of writing this. This should work. Thanks for pointing it out!
Just to add this. If you’re on a mac you need to add the backup extension. Answer from this post.
Sorry, I can’t give you actual code right now. However, try looking at something along the lines of
What this should do (once properly formatted) is count the number of lines in the file (wc -l), subtract 44 from it (-44) and then print out everything starting with the 45th line in the file.
Hope this helps and good luck.