- Delete specific line number(s) from a text file using sed?
- 8 Answers 8
- Sed Command to Delete a Line
- Sed on Linux
- Deleting line using sed
- Delete single line
- Delete a range of line
- Delete multiple lines
- Delete all lines except specified range
- Delete empty lines
- Delete lines based on pattern
- Delete lines starting with a specific character
- Delete lines ending with specific character
- Deleting lines that match the pattern and the next line
- Deleting line from the pattern match to the end
- Final thought
- About the author
- Sidratul Muntaha
- Linux — Delete all lines from a given line number
- 3 Answers 3
- How do I remove certain lines (using line numbers) in a file?
- 4 Answers 4
Delete specific line number(s) from a text file using sed?
Maybe see also stackoverflow.com/questions/13272717/… and just applyeit in reverse (print if key not in associative array).
8 Answers 8
If you want to delete lines from 5 through 10 and line 12th:
This will print the results to the screen. If you want to save the results to the same file:
This will store the unmodified file as file.bak , and delete the given lines.
Note: Line numbers start at 1. The first line of the file is 1, not 0.
Not all unixes have gnu sed with «-i». Don’t make the mistake of falling back to «sed cmd file > file», which will wipe out your file.
@KanagaveluSugumar sed -e ‘5d’ file . The syntax is
; where can be either a single line like 5 or a range of lines like 5,10 , and the command d deletes the given line or lines. The addresses can also be regular expressions, or the dollar sign $ indicating the last line of the file.You can delete a particular single line with its line number by
This will delete the line on 33 line number and save the updated file.
Same here, I wrote a loop and strangely some files lost the correct line but some files lost one other line too, have no clue what went wrong. (GNU/Linux bash4.2) awk command below worked fine in loop
Be really careful to use sort -r if you are deleting from a list of lines, otherwise your first sed will change the line numbers of everything else.
To comments about wrong lines being deleted within a loop : be sure to start with the largest line number, otherwise each deleted line will offset the line numbering…
On my system, when processing large files, sed appears an order of magnitude slower than a simple combination of head and tail : here’s an example of the faster way (without in-place mode): delete-line() < local filename="$1"; local lineNum="$2"; head -n $((lineNum-1)) "$filename"; tail +$((lineNum+1)) "$filename"; >
Note that this doesn’t delete anything in the file. It just prints the file without these lines to stdout. So you also need to redirect the output to a temp file, and then move the temp file to replace the original.
$ cat foo 1 2 3 4 5 $ sed -e '2d;4d' foo 1 3 5 $ I like this answer because it also shows that sed counts lines starting from 1 (it could have been 0).
This is very often a symptom of an antipattern. The tool which produced the line numbers may well be replaced with one which deletes the lines right away. For example;
grep -nh error logfile | cut -d: -f1 | deletelines logfile (where deletelines is the utility you are imagining you need) is the same as
Having said that, if you are in a situation where you genuinely need to perform this task, you can generate a simple sed script from the file of line numbers. Humorously (but perhaps slightly confusingly) you can do this with sed .
This accepts a file of line numbers, one per line, and produces, on standard output, the same line numbers with d appended after each. This is a valid sed script, which we can save to a file, or (on some platforms) pipe to another sed instance:
sed 's%$%d%' linenumbers | sed -f - logfile On some platforms, sed -f does not understand the option argument — to mean standard input, so you have to redirect the script to a temporary file, and clean it up when you are done, or maybe replace the lone dash with /dev/stdin or /proc/$pid/fd/1 if your OS (or shell) has that.
As always, you can add -i before the -f option to have sed edit the target file in place, instead of producing the result on standard output. On *BSDish platforms (including OSX) you need to supply an explicit argument to -i as well; a common idiom is to supply an empty argument; -i » .
Sed Command to Delete a Line
![]()
Sed is a built-in Linux tool for text manipulation. The term sed stands for stream editor. Despite the name, sed isn’t a text editor by itself. Rather, it takes text as input, performs various text modifications according to instructions, and prints the output.
This guide will demonstrate how to use sed to delete a line from a text.
Sed on Linux
The full name of sed gives us a hint at its working method. Sed takes the input text as a stream. The text can come from anywhere – a text file or standard output (STDOUT). After taking the input, sed operates on it line by line.
For demonstration, here’s a simple text file I’ve generated.
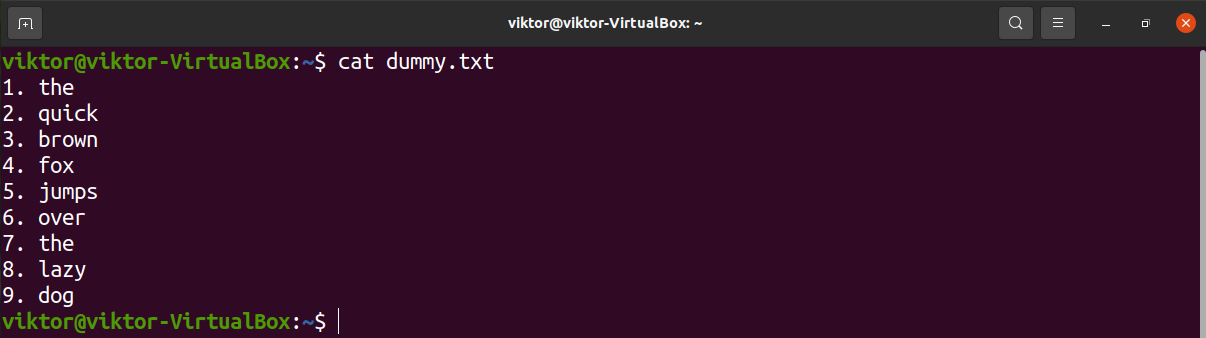
Deleting line using sed
To delete a line, we’ll use the sed “d” command. Note that you have to declare which line to delete. Otherwise, sed will delete all the lines.
Delete single line
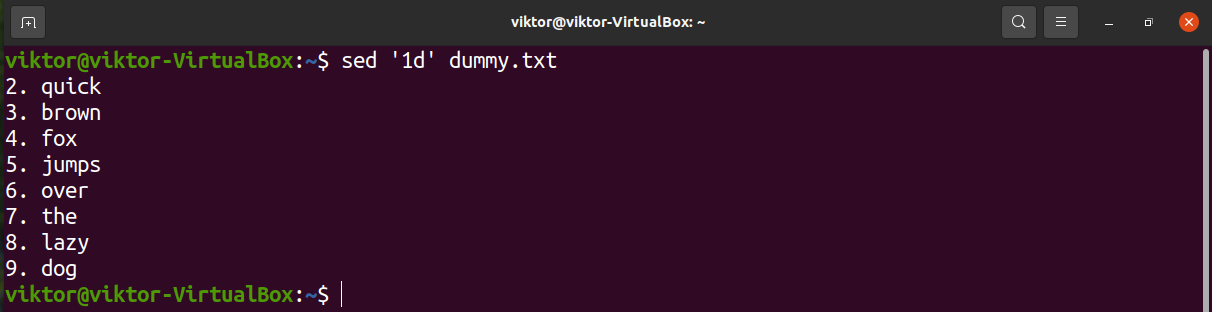
The following sed command will delete the first line of the text.
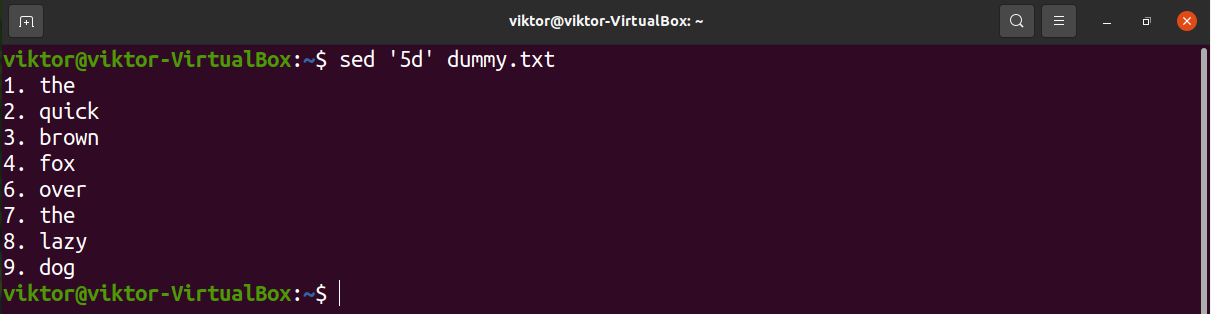
Basically, to delete a line, you need the line number of the target line. Let’s remove line 5.
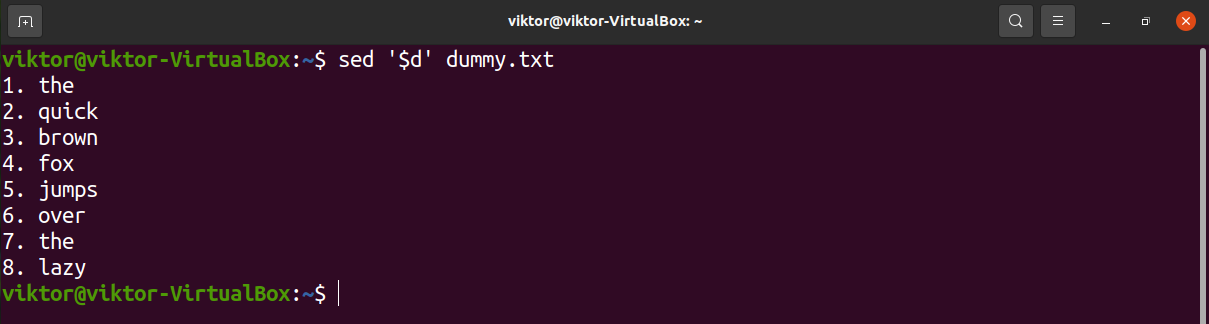
To delete the last line of the text file, instead of manually calculating the line number, use “$” instead.
Delete a range of line
Sed can delete a range of lines. Here, the minimum line value is 1, and the maximum line value is 5. To declare range, we’re using comma (,).

Delete multiple lines
What if the lines you desire to remove are not in a fixed range? Have a look at the following sed command. Note that we’re using a semicolon (;) as the delimiter. Essentially, each delimited option is a separate sed command.

Delete all lines except specified range
In the next example, sed will only keep the lines described by the range. Here, “!” is the negation operator, telling sed to keep the specific lines.

Delete empty lines
If there are multiple empty or blank lines in the text, the following sed command will remove all of them.
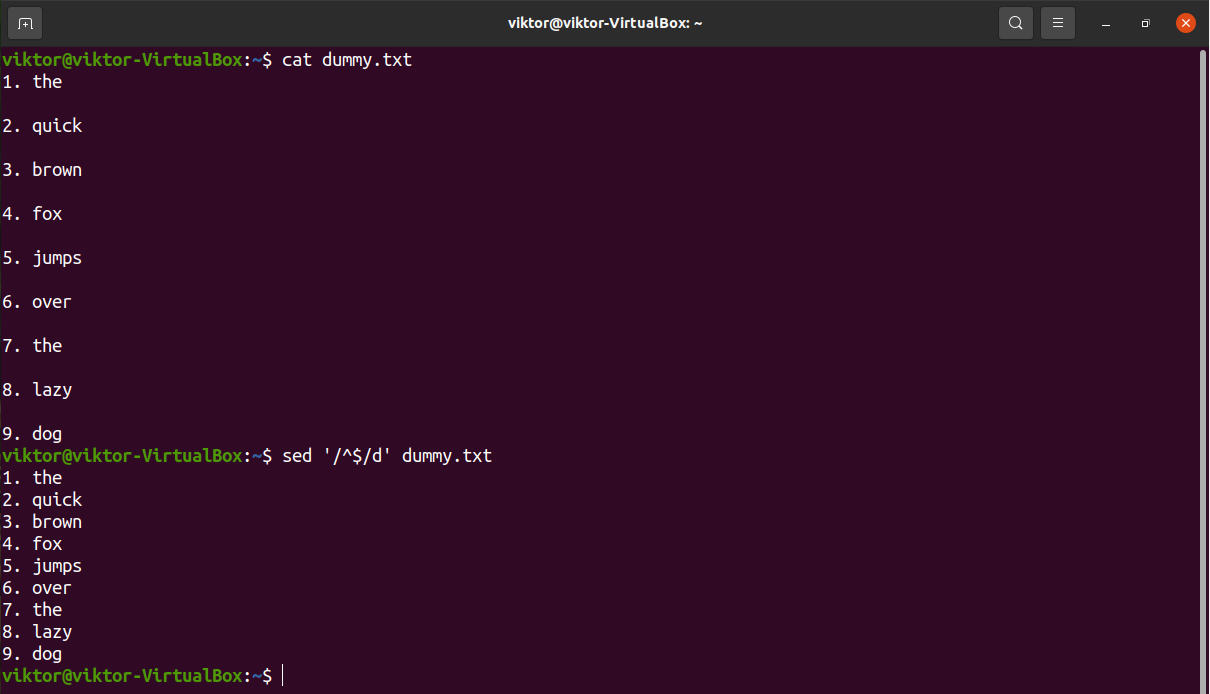
Delete lines based on pattern
Sed can search for a particular pattern and perform the specified actions on the line. We can use this feature to delete specific lines that match a pattern.
Let’s have a look at the following demonstration. Sed will remove any line that contains the string “the”.
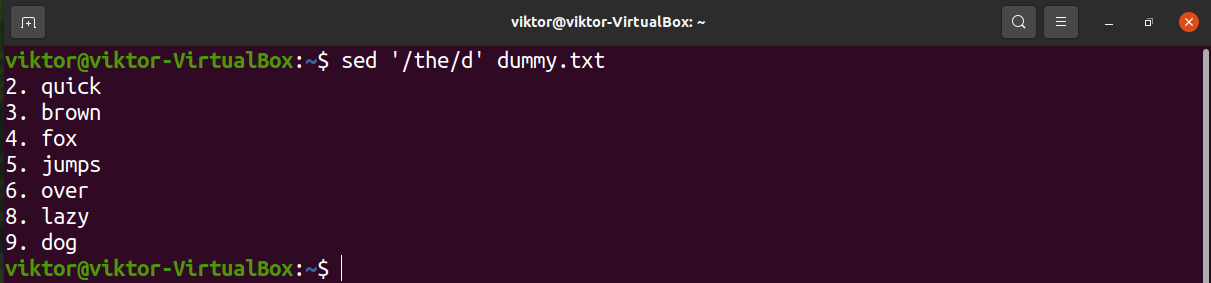
We can also describe multiple strings to search for. Each string is delimited using the symbol “\|”.

Delete lines starting with a specific character
To denote the starting of a line, we’ll use the caret (^) symbol.
The following sed command will remove all the lines starting with a digit. Here, the character group “[:digit:]” describes all digits (0-9).

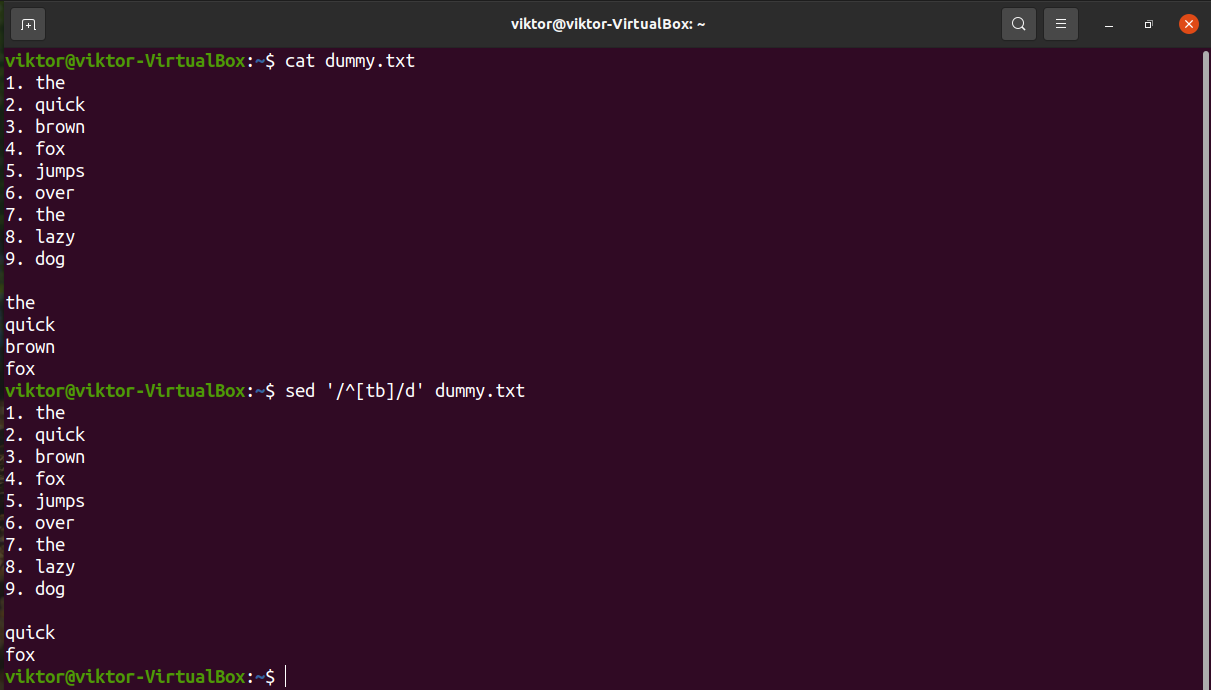
We can also describe multiple characters for a valid match. The following example will match all the lines that start with “t” and “b”.
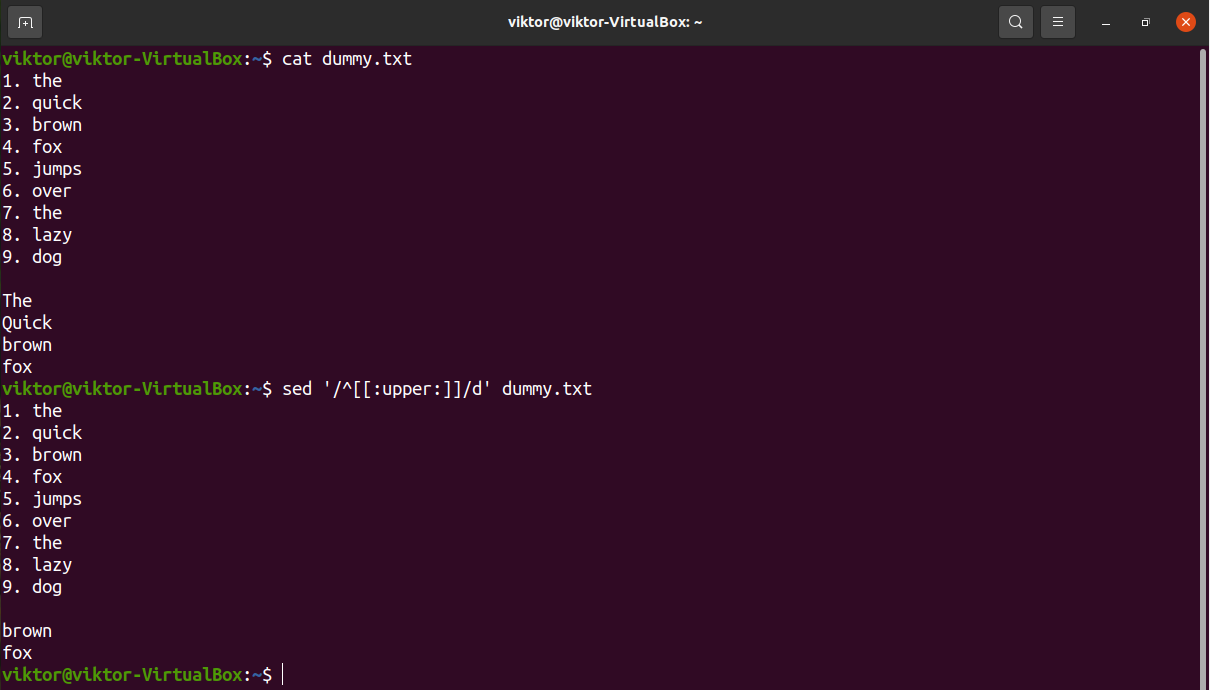
In the next example, check out how to remove all the lines that start with an uppercase character. Here, we’re using the uppercase character group “[:upper:]”.
If the target lines have lowercase characters at the start, use the lowercase character group “[:lower:]”.
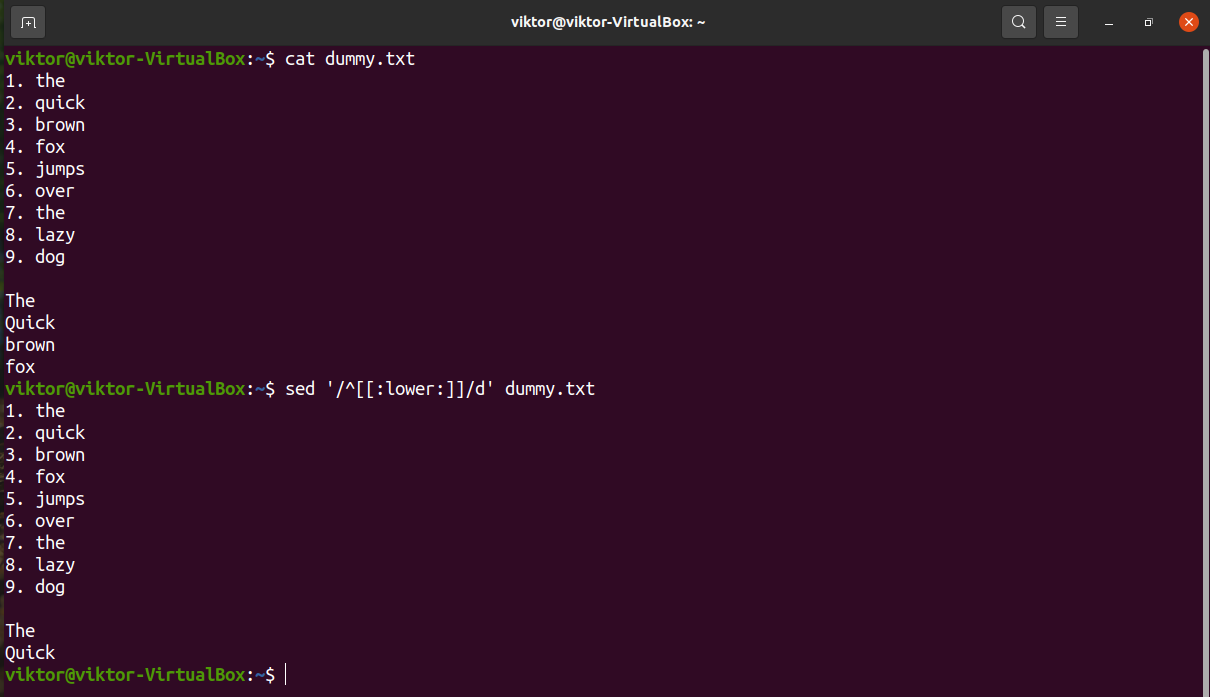
Delete lines ending with specific character
To denote the end of a line, we can use the symbol “$”. It describes the match with the last occurrence of the pattern.
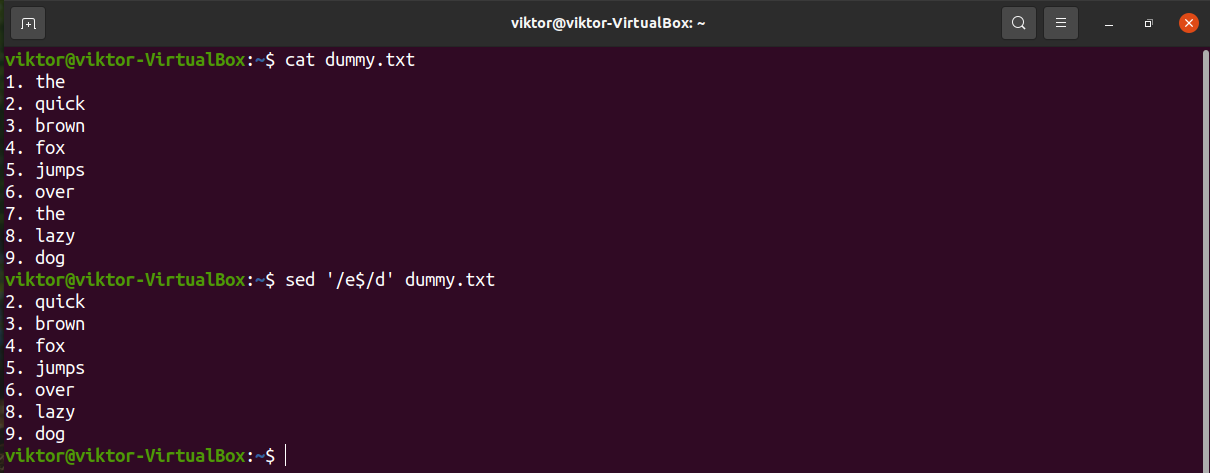
In the next example, sed will delete lines ending with “e”.
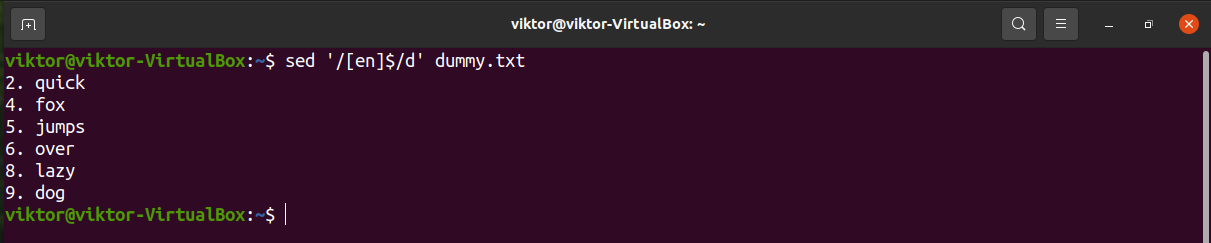
Let’s try with a multiple-character search.
Deleting lines that match the pattern and the next line
We’ve already demonstrated how to delete a line if a pattern matches. We can further extend and delete the subsequent line as well.
Check out the following sed command.

Sed will match the line that contains “the” and delete the subsequent line as well.
Deleting line from the pattern match to the end
We can further extend the previous example to order sed to delete all the lines, starting from the first match of the pattern.

Here, sed will delete the line that matches the pattern “the” first and all lines afterward.
Final thought
Sed is a simple tool. However, it can do wonders, thanks to the support for regular expression. Sed also integrates seamlessly in various scripts.
This was just a short guide demonstrating one of the sed functions – deleting lines. There are tons of other things you can do with sed. For example, check out this mega guide on 50 sed examples. It’s a fantastic guide covering all the basics and many advanced sed implementations.
About the author
Sidratul Muntaha
Student of CSE. I love Linux and playing with tech and gadgets. I use both Ubuntu and Linux Mint.
Linux — Delete all lines from a given line number
The idea is to delete all lines from a file after & including the second occurence of the pattern. I’m not stubborn with sed . Awk & perl could do too.
Any time you find yourself using multiple pipes between grep and sed you should be using awk instead.
3 Answers 3
Seems like you want to delete the rest of the file after a second showing of a pattern ( debited ), including that line.
Then can truncate it, ising tell for the length of what’s been read up to that line
perl -e'while (<>) < if ( ($cnt += /debited/) == 2 ) < truncate $ARGV, $len; exit >$len = tell; >' file Here the $ARGV variable has the «current» file (when reading from <>). Feel free to introduce a variable with the pattern instead of the literal ( debited ), based on your context.
This can be made to look far nicer in a little script but it seems that a command-line program («one-liner») is needed in the question.
You could just close ARGV . perl -pi.bak -e’if ( ($c += /debited/) == 2 ) < close ARGV >‘ file . As I recall, it works even with multiple files. Untested.
@TLP Yeah, a good idea — I’d think that it absolutely should truncate it — but it doesn’t? Maybe my testing’s faulty somehow.
@TLP oh . actually, can’t do that: once the line with the second debited has been read it’s too late to simply truncate where we are (even if it worked); it has to truncate to the length of up to that line, and can’t accomplish that using close ARGV . A good idea, regardless
The perldoc says that it can depend on your system. Oh right, yes, you have to print after the check, and use -n .
I always suggest ed for editing files over trying to use sed to do it; a program intended from the beginning to work with a file instead of a stream of lines just works better for most tasks.
The idea is to delete all lines from a file after & including the second occurence[sic] of the pattern
$ cat demo.txt a b c debited 12 d e debited 14 f g h $ printf "%s\n" '/debited/;//,$d' w | ed -s demo.txt $ cat demo.txt a b c debited 12 d e The ed command /pattern/;//,$d first sets the current line cursor to the first one that matches the basic regular expression pattern, then moves it to the next match of the pattern and deletes everything from there to the end of the file. Then w writes the changed file back to disk.
How do I remove certain lines (using line numbers) in a file?
There are specific lines that I want to remove from a file. Let’s say it’s line 20-37 and then line 45. How would I do that without specifying the content of those lines?
4 Answers 4
If you wanted to do this in-place:
sed --in-place '20,37d; 45d' file.txt I’ve often wondered about the possibly misleading term in-place, when referring to ‘sed’, so I looked it up in ‘man sed’: —in-place[=SUFFIX] This option specifies that files are to be edited in-place. GNU sed’ does this by creating a temporary file and sending output to this file rather than to the standard output.` . I don’t know about any other ‘sed’ but the logistics of updating «in place» with a stream editor don’t «compute» 🙂
If the file fits comfortably in memory, you could also use ed .
The commands are quite similar to the sed one above with one notable difference: you have to pass the list of line numbers/ranges to be deleted in descending order (from the highest line no/range to the lowest one). The reason is that when you delete/insert/split/join lines with ed , the text buffer is updated after each subcommand so if you delete some lines, the rest of the following lines will no longer be at the same position in the buffer when the next subcommand is executed. So you have to start backwards 1 .
In-place editing:
printf '%s\n' 45d 20,37d w q | ed -s in_file Replace w rite with ,p rint if you want to print the resulting output instead of writing to file. If you want to keep the original file intact and write to another file you can pass the new file name to the w rite subcommand:
1 Unless you are willing to calculate the new line numbers after each d elete, which is quite trivial for this particular case (after deleting lines 20-37, i.e. 18 lines, line 45 becomes line 27) so you could run:
However, if you have to delete multiple line numbers/ranges, working backwards is a no-brainer.