- How to clear text in a file?
- 9 Answers 9
- Not the shortest answer but.
- Clear everything except first 10,000 bytes
- Sed Command to Delete a Line
- Sed on Linux
- Deleting line using sed
- Delete single line
- Delete a range of line
- Delete multiple lines
- Delete all lines except specified range
- Delete empty lines
- Delete lines based on pattern
- Delete lines starting with a specific character
- Delete lines ending with specific character
- Deleting lines that match the pattern and the next line
- Deleting line from the pattern match to the end
- Final thought
- About the author
- Sidratul Muntaha
- How to Remove Lines from a File Using Sed Command
- How to Delete a Line from a File
- How to Delete First and Last Line from a File
- How to Delete Range of Lines from a File
- How to Remove Blank Lines from a File
- How to Delete Lines Starting with Words in a File
- How to Make Changes Directly into a File
How to clear text in a file?
How to clear text that existed in a text file without opening it? I mean for example I have a file as hello.txt with some text data in it, and how can I clear the total text in that file without opening it? By this, I mean not using any editor like nano, Gedit, etc.
What do you mean by ‘opening’ a file? In all the answers given so far the file will still be opened for writing by the shell. In the end the shell is just a program like any other.
Hus787 I have not typed from getting there if you think so else I welcome your interest in my question.
I agree with Jeff’s comment. I too have opinion* that the file stream has to be opened to write to it, whether you use any text editors, or redirection. (*appreciate anybody suggedting links to help with the matter)
9 Answers 9
Just open your terminal with CTRL + ALT + T and type as
that’s it, your data in that file will be cleared with out opening it even .
@souravc John is correct, the file will be open. Shell opens a file for redirection > with flags O_WRITE|O_TRUNC . In fact, this is stated in the bash manual explicitly under Redirecting Output section: «If the file does not exist it is created; if it does exist it is truncated to zero size.»
The easiest way is to truncate a file is to redirect the output of the shell no-op command ( : ) to the file you want to erase.
Its probably not the easiest (relative to just > ) but the fastest for sure..i wonder why it has not been mentioned in any of the answers of this highly viewed question..here, take +1..
I have to do this all the time with log files. The easiest way I have found is with the following command:
This deletes allo of the content of the file, and leaves you with an empty file without having to open it in an editor, select text, any of that stuff. More specifically what it does is to replace the contents of the file with the contents of «/dev/null», or nothing. It’s pretty slick, actually.
The only caveat is that the user you are currently logged in as must have write permission to said file.
I am also going to use redirection like rajagenupula’s answer. But there is a little more flexibility. Open a terminal and type,
And press Ctrl + C . It will wipe out the previous file. If you want upto this much it is fine.
If you wish you can do something more after wiping the file. In this way not only you can wipe a file without opening but also you can write a few lines with proper formatting in the file. Say you wish to write «Ubuntu is the best OS» after wiping the file, just do
cat > hello.txt Ubuntu is the best OS Then press Ctrl + C . Now the previous file is wiped out. At the same time words are there in two lines as I put them.
hey thank you for answering. so little but work to be done right after that also & but still interesting .+1
Not the shortest answer but.
This answer is based on another from Super User. Although not the shortest bash command, truncate is the most readable for average newbies:
$ echo Hello > Hello.txt $ echo World! >> Hello.txt $ cat Hello.txt Hello World! $ truncate -s 0 Hello.txt $ ll Hello.txt -rw-rw-r-- 1 rick rick 0 Mar 20 17:32 Hello.txt Parameters used with truncate command here:
Clear everything except first 10,000 bytes
An advantage of truncate is you can specify how much to keep, not just zero:
$ truncate -s 10000 Hello.txt . will truncate everything after the first 10,000 bytes. This could be useful if a program went crazy and dumped many Megabytes of data into a small log file:
- Run the truncate command for a reasonable larger normal size of 10K
- Open the file with your text editor and press End
- Highlight and PgUp to delete the remaining bytes that don’t belong (usually recognizable by ASCII garbage characters).
Another approach — cp the /dev/null to the file
xieerqi:$ cat testFile.txt Filesystem 1K-blocks Used Available Use% Mounted on /dev/sda1 115247656 83100492 26269816 76% / none 4 0 4 0% /sys/fs/cgroup udev 2914492 4 2914488 1% /dev tmpfs 585216 1152 584064 1% /run none 5120 0 5120 0% /run/lock none 2926072 98096 2827976 4% /run/shm none 102400 76 102324 1% /run/user xieerqi:$ cp /dev/null testFile.txt xieerqi:$ cat testFile.txt xieerqi:$ Why does this work and how does this work ? The testFile.txt will be opened with O_WRONLY|O_TRUNC flags, which means if the file exists — it will be truncated, which means contents discarded and size set to zero. This is the same flag with which > operator in shell opens the file on the right of that operator.
Next, cp will attempt to read from /dev/null and after reading 0 bytes will simply close both files, thus leaving testFile.txt truncated and contents effectively deleted.
Knowing that, we could in theory use anything that allows us to open a file with O_TRUNC . For instance this:
Small difference here is that dd won’t perform any read() at all. Big plus of this dd version is that it is POSIXly portable. The dd specifications state:
If the seek= expr conversion is not also specified, the output file shall be truncated before the copy begins if an explicit of= file operand is specified, unless conv= notrunc is specified.
By contrast cp /dev/null testFile.txt isn’t necessarily portable, since POSIX specifications for cp cover what happens only if source_file is non-regular and when -r / -R flags are specified (big thanks to Stephen Kitt for pointing this out), but not what happens when -r or -R are omitted, which is the case here. However it appears at least GNU cp defaults to using rule 3 in the same spec, which is truncating the existing file without changing its type.
Sed Command to Delete a Line
![]()
Sed is a built-in Linux tool for text manipulation. The term sed stands for stream editor. Despite the name, sed isn’t a text editor by itself. Rather, it takes text as input, performs various text modifications according to instructions, and prints the output.
This guide will demonstrate how to use sed to delete a line from a text.
Sed on Linux
The full name of sed gives us a hint at its working method. Sed takes the input text as a stream. The text can come from anywhere – a text file or standard output (STDOUT). After taking the input, sed operates on it line by line.
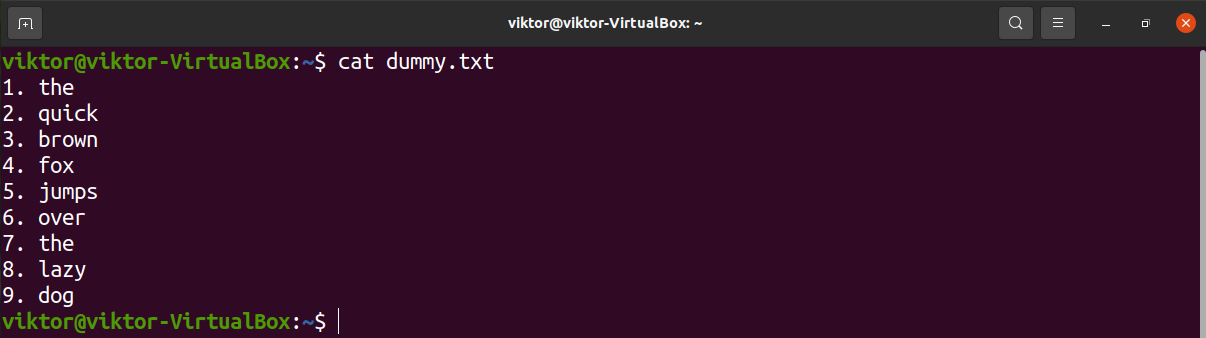
For demonstration, here’s a simple text file I’ve generated.
Deleting line using sed
To delete a line, we’ll use the sed “d” command. Note that you have to declare which line to delete. Otherwise, sed will delete all the lines.
Delete single line
The following sed command will delete the first line of the text.
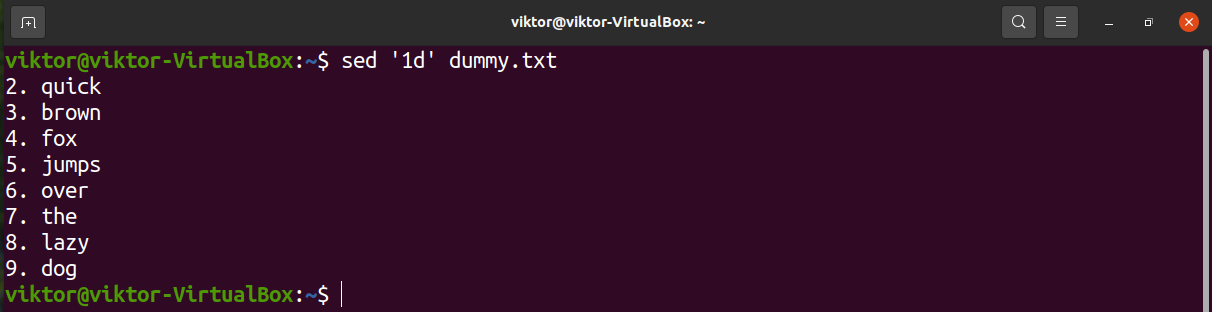
Basically, to delete a line, you need the line number of the target line. Let’s remove line 5.
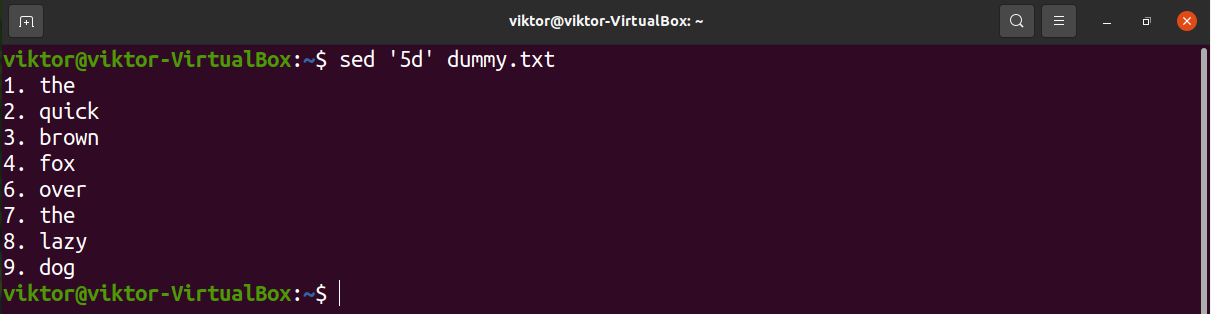
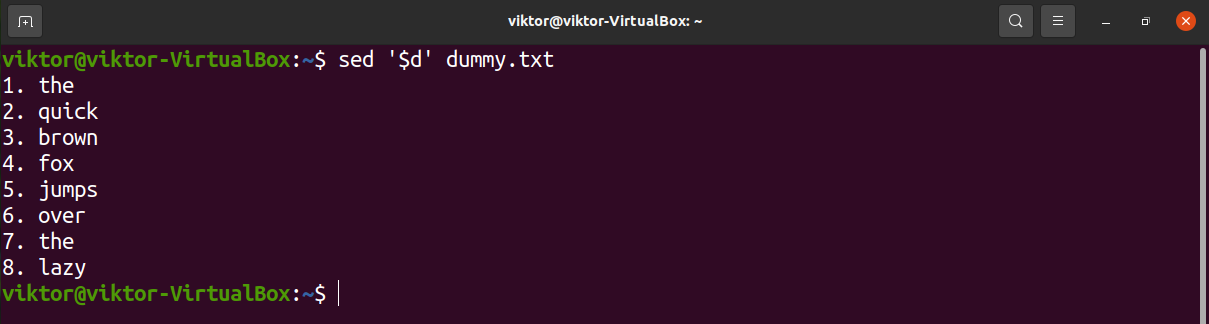
To delete the last line of the text file, instead of manually calculating the line number, use “$” instead.
Delete a range of line
Sed can delete a range of lines. Here, the minimum line value is 1, and the maximum line value is 5. To declare range, we’re using comma (,).

Delete multiple lines
What if the lines you desire to remove are not in a fixed range? Have a look at the following sed command. Note that we’re using a semicolon (;) as the delimiter. Essentially, each delimited option is a separate sed command.

Delete all lines except specified range
In the next example, sed will only keep the lines described by the range. Here, “!” is the negation operator, telling sed to keep the specific lines.

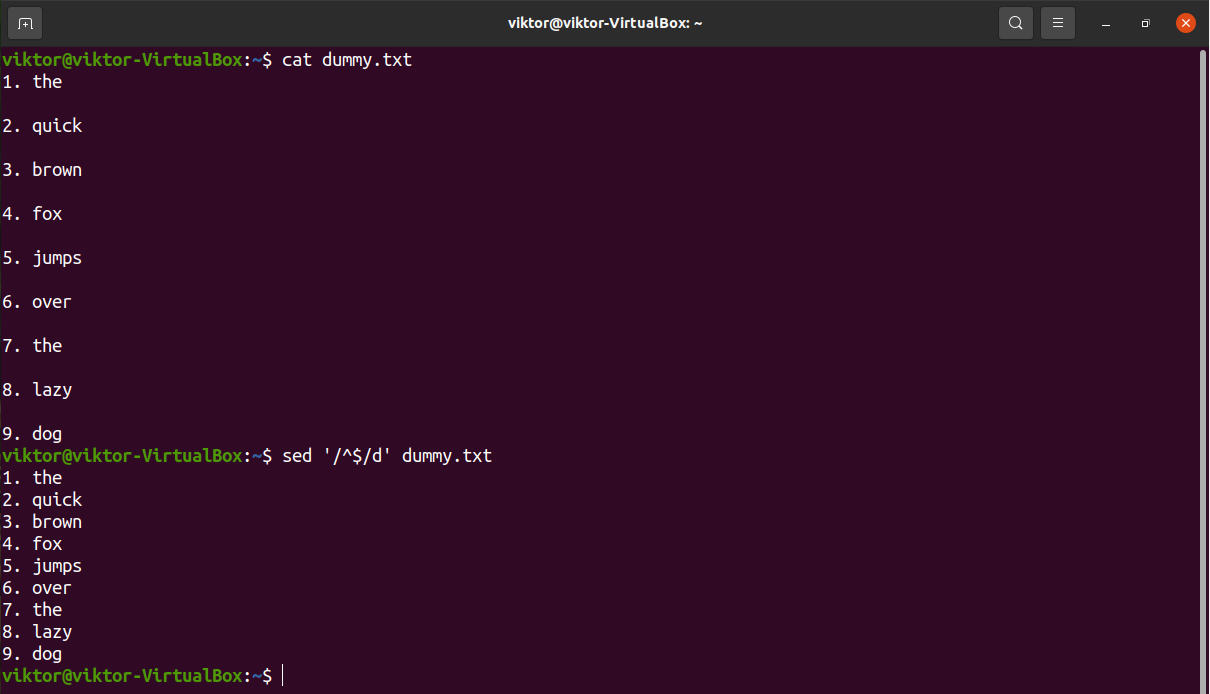
Delete empty lines
If there are multiple empty or blank lines in the text, the following sed command will remove all of them.
Delete lines based on pattern
Sed can search for a particular pattern and perform the specified actions on the line. We can use this feature to delete specific lines that match a pattern.
Let’s have a look at the following demonstration. Sed will remove any line that contains the string “the”.
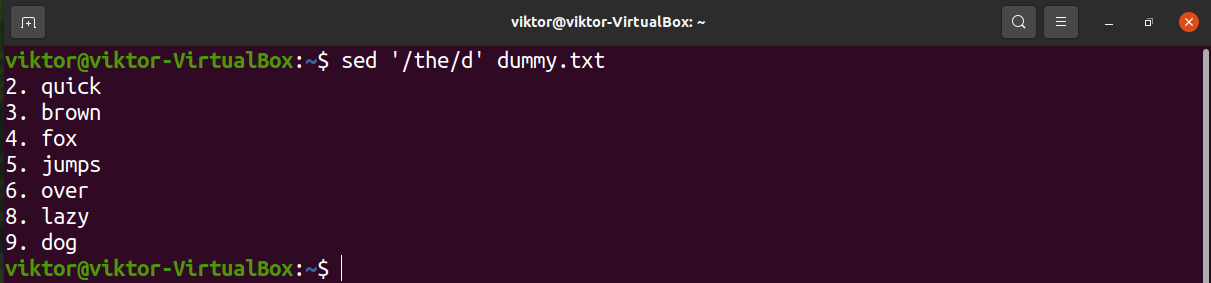
We can also describe multiple strings to search for. Each string is delimited using the symbol “\|”.

Delete lines starting with a specific character
To denote the starting of a line, we’ll use the caret (^) symbol.
The following sed command will remove all the lines starting with a digit. Here, the character group “[:digit:]” describes all digits (0-9).

We can also describe multiple characters for a valid match. The following example will match all the lines that start with “t” and “b”.
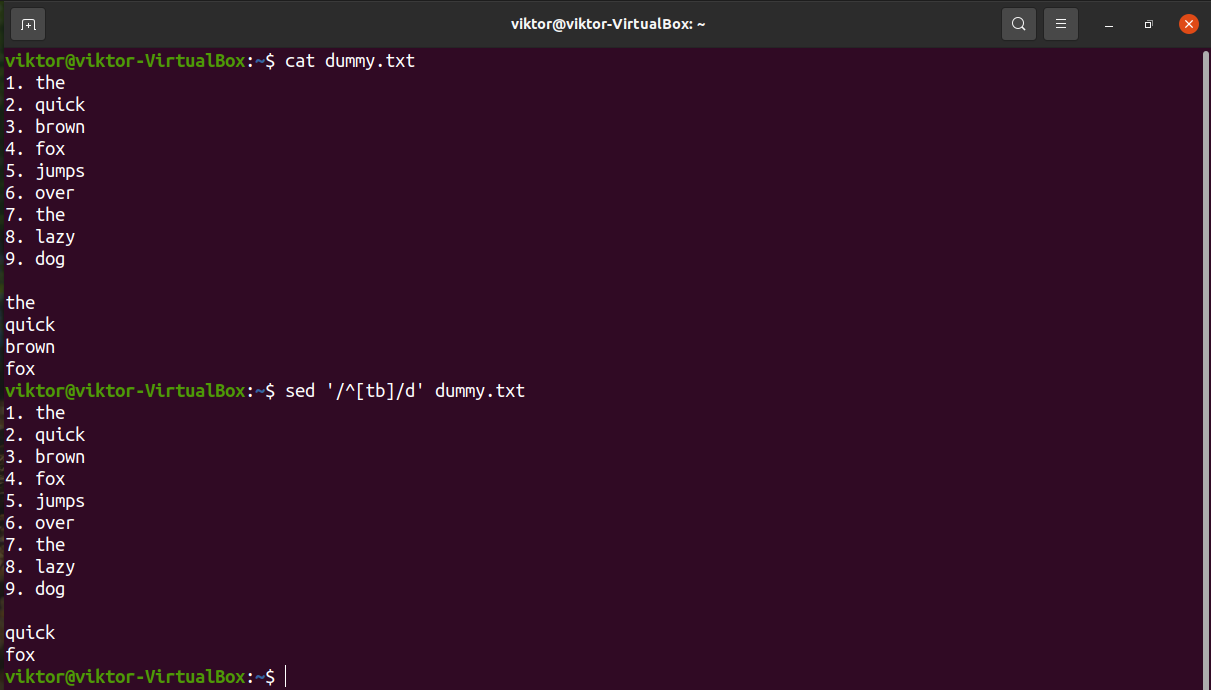
In the next example, check out how to remove all the lines that start with an uppercase character. Here, we’re using the uppercase character group “[:upper:]”.
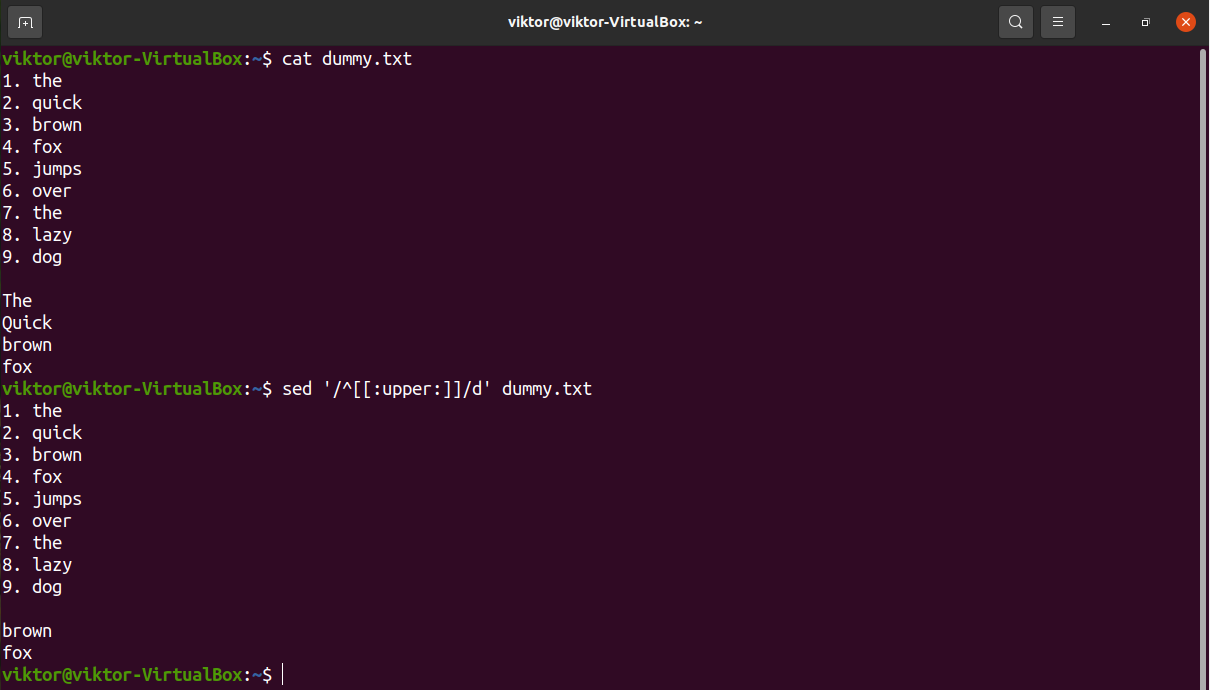
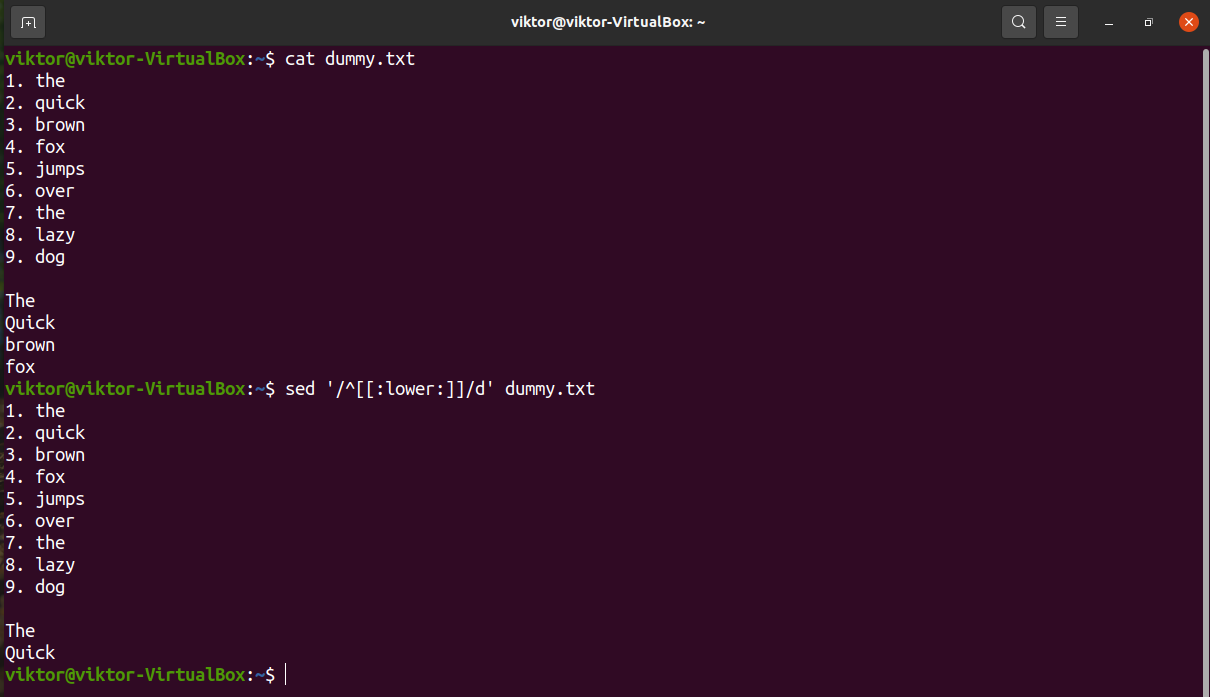
If the target lines have lowercase characters at the start, use the lowercase character group “[:lower:]”.
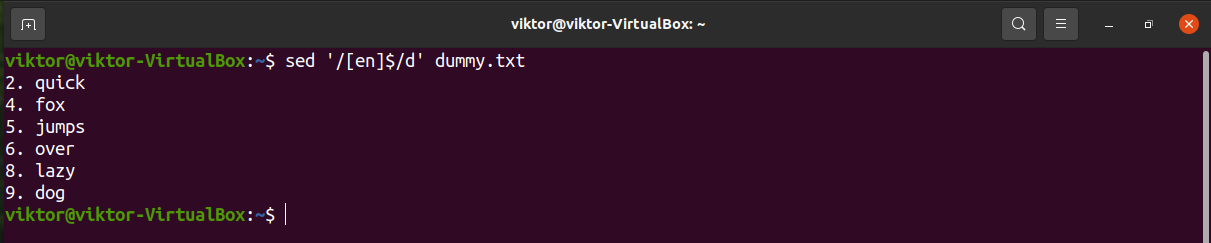
Delete lines ending with specific character
To denote the end of a line, we can use the symbol “$”. It describes the match with the last occurrence of the pattern.
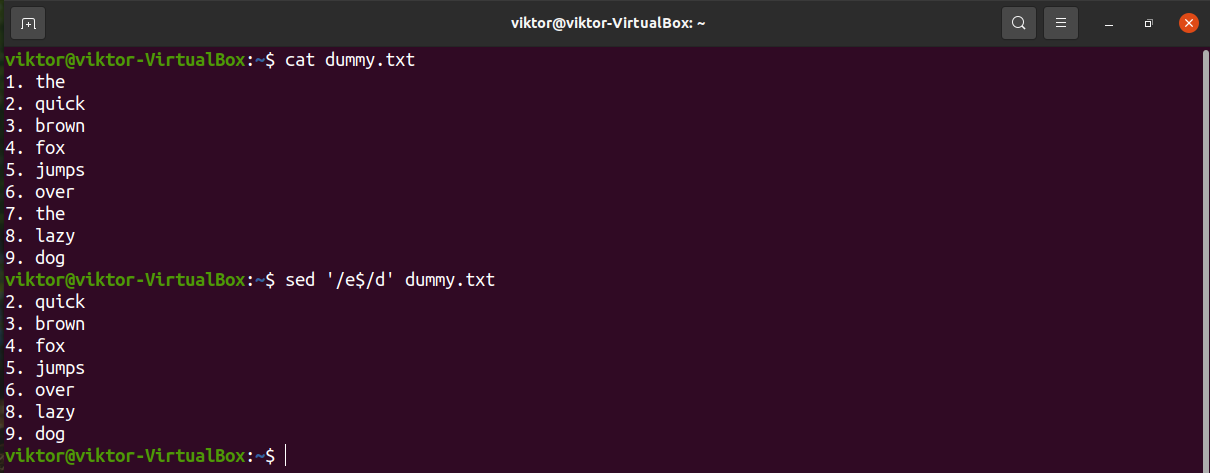
In the next example, sed will delete lines ending with “e”.
Let’s try with a multiple-character search.
Deleting lines that match the pattern and the next line
We’ve already demonstrated how to delete a line if a pattern matches. We can further extend and delete the subsequent line as well.
Check out the following sed command.

Sed will match the line that contains “the” and delete the subsequent line as well.
Deleting line from the pattern match to the end
We can further extend the previous example to order sed to delete all the lines, starting from the first match of the pattern.

Here, sed will delete the line that matches the pattern “the” first and all lines afterward.
Final thought
Sed is a simple tool. However, it can do wonders, thanks to the support for regular expression. Sed also integrates seamlessly in various scripts.
This was just a short guide demonstrating one of the sed functions – deleting lines. There are tons of other things you can do with sed. For example, check out this mega guide on 50 sed examples. It’s a fantastic guide covering all the basics and many advanced sed implementations.
About the author
Sidratul Muntaha
Student of CSE. I love Linux and playing with tech and gadgets. I use both Ubuntu and Linux Mint.
How to Remove Lines from a File Using Sed Command
streaming editor (sed) is an important tool when you work with parsing and transforming text in your nix-based systems. It is used for finding, filtering, text substitution, and text manipulations such as insertion, deletion, replace, and search in the text files.
In most Linux distributions, the sed command comes pre-installed and you can verify it using the following commands, which will show the binary location of the command and version.
Here in this article, I am going to show you how to remove lines from a file using the sed command with the help of a sample file that contains 7 lines. I am going to use this file for demonstration purposes.
$ cat testfile.txt First line second line Third line Fourth line Fifth line Sixth line SIXTH LINE
How to Delete a Line from a File
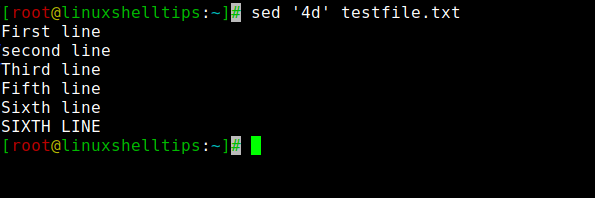
To delete the line from a file you can use the below command. You have to substitute ‘N’ with the line number and ‘d’ is to delete the line.
If you have to delete the fourth line from the file then you have to substitute N=4 .
$ sed '4d' testfile.txt
How to Delete First and Last Line from a File
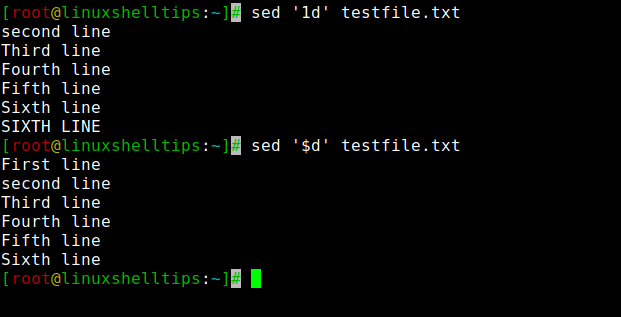
You can delete the first line from a file using the same syntax as described in the previous example. You have to put N=1 which will remove the first line.
$ sed '1d' testfile.txt
To delete the last line from a file using the below command with ($) sign that denotes the last line of a file.
$ sed '$d' testfile.txt
How to Delete Range of Lines from a File
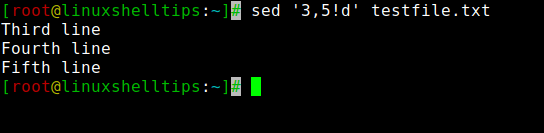
You can delete a range of lines from a file. Let’s say you want to delete lines from 3 to 5, you can use the below syntax.
To actually delete, use the following command to do it.

You can use ! symbol to negate the delete operation. This will delete all lines except the given range(3-5).
How to Remove Blank Lines from a File
To delete all blank lines from a file run the following command. An important point to note is using this command, empty lines with spaces will not be deleted. I have added empty lines and empty lines with spaces in my test file.
$ cat testfile.txt First line second line Third line Fourth line Fifth line Sixth line SIXTH LINE
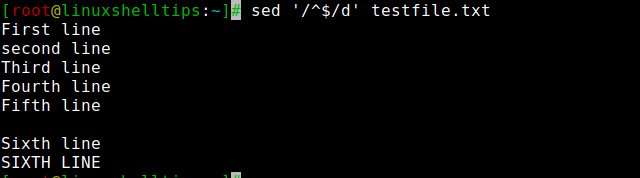
From the above image, you can see empty lines are deleted but lines that have spaces are not deleted. To delete all lines including spaces you can run the following command.
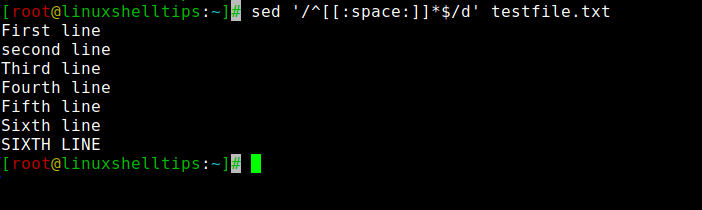
How to Delete Lines Starting with Words in a File
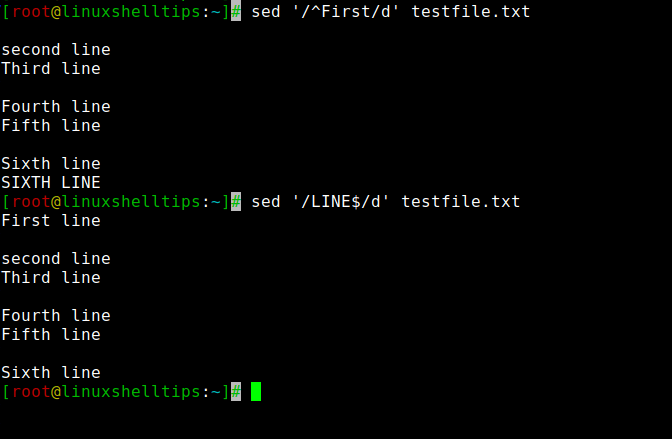
To delete a line that starts with a certain word run the following command with ^ symbol represents the start of the word followed by the actual word.
To delete a line that ends with a certain word run the following command. The word to be deleted followed by the $ symbol will delete lines.
How to Make Changes Directly into a File
To make the changes directly in the file using sed you have to pass -i flag which will make the changes directly in the file.
We have come to the end of the article. The sed command will play a major part when you are working on manipulating any files. When combined with other Linux utilities like awk, grep you can do more things with sed.