How to find (and delete) duplicate files
I have a largish music collection and there are some duplicates in there. Is there any way to find duplicate files. At a minimum by doing a hash and seeing if two files have the same hash. Bonus points for also finding files with the same name apart from the extension — I think I have some songs with both mp3 and ogg format versions. I’m happy using the command line if that is the easiest way.
11 Answers 11
fdupes
I use fdupes for this. It is a commandline program which can be installed from the repositories with sudo apt install fdupes . You can call it like fdupes -r /dir/ect/ory and it will print out a list of dupes. fdupes has also a README on GitHub and a Wikipedia article, which lists some more programs.
It also has a «-d» option that lets you choose which copy you want to keep, and deletes the other ones (or you can keep all of them if you want).
Can you explain in more detail how to delete all duplicates (leaving only a single copy each file) in a recursive directory tree? I want to do this automatically, that is, without having to specify each time which file to keep. It should just select one of the duplicates.
fdupes -r . -d -N should save the first instance and delete the dupes. I just successfully cleared a single folder using fdupes . -d -N non recursively
List of programs/scripts/bash-solutions , that can find duplicates and run under nix :
- dupedit: Compares many files at once without checksumming. Avoids comparing files against themselves when multiple paths point to the same file.
- dupmerge: runs on various platforms (Win32/64 with Cygwin, *nix, Linux etc.)
- dupseek: Perl with algorithm optimized to reduce reads.
- fdf: Perl/c based and runs across most platforms (Win32, *nix and probably others). Uses MD5, SHA1 and other checksum algorithms
- freedups: shell script, that searches through the directories you specify. When it finds two identical files, it hard links them together. Now the two or more files still exist in their respective directories, but only one copy of the data is stored on disk; both directory entries point to the same data blocks.
- fslint: has command line interface and GUI.
- liten: Pure Python deduplication command line tool, and library, using md5 checksums and a novel byte comparison algorithm. (Linux, Mac OS X, *nix, Windows)
- liten2: A rewrite of the original Liten, still a command line tool but with a faster interactive mode using SHA-1 checksums (Linux, Mac OS X, *nix)
- rdfind: One of the few which rank duplicates based on the order of input parameters (directories to scan) in order not to delete in «original/well known» sources (if multiple directories are given). Uses MD5 or SHA1.
- rmlint: Fast finder with command line interface and many options to find other lint too (uses MD5), since 18.04 LTS has a rmlint-gui package with GUI (may be launched by rmlint —gui or from desktop launcher named Shredder Duplicate Finder)
- ua: Unix/Linux command line tool, designed to work with find (and the like).
- findrepe: free Java-based command-line tool designed for an efficient search of duplicate files, it can search within zips and jars.(GNU/Linux, Mac OS X, *nix, Windows)
- fdupe: a small script written in Perl. Doing its job fast and efficiently.1
- ssdeep: identify almost identical files using Context Triggered Piecewise Hashing
for Ubuntu, another way is to open Files, search (control-f) for a given extension (eg .mp3), and then sort on file name; this will allow to delete duplicates by hand, and at the same time show the locations of the duplicates.
FSlint has a GUI and some other features. The explanation of the duplicate checking algorithm from their FAQ:
1. exclude files with unique lengths 2. handle files that are hardlinked to each other 3. exclude files with unique md5(first_4k(file)) 4. exclude files with unique md5(whole file) 5. exclude files with unique sha1(whole file) (in case of md5 collisions). Thanks. Note that the command name is «fslint-gui», and the command line tools are not in $PATH by default — they are in /usr/share/fslint/fslint. I was confused when I didn’t get help on which package it was in by just running fslint (via /usr/lib/command-not-found).
@nealmcb If using sudo apt-get install fslint , the installation currently does put fslint-gui into the path and so I can run it from anywhere by just typing fslint-gui . You can find where fslint-gui lives by typing which fslint-gui (it looks like a Python script).
If your deduplication task is music related, first run the picard application to correctly identify and tag your music (so that you find duplicate .mp3/.ogg files even if their names are incorrect). Note that picard is also available as an Ubuntu package.
That done, based on the musicip_puid tag you can easily find all your duplicate songs.
I just updated the metadata for my library with Picard. I then used fdupes -r -d -N to find and delete duplicates. But it’s still not identifying many duplicates. How exactly did you do this with the musicip_puid ?
It’s been years since then, and I’m afraid I haven’t followed picard; my music library has been safely archived, a few select songs are included in my phone’s media, and all other needs are covered by streaming services. I can only say I remember that the puid did help me locate similar sounding songs. I’m sorry I currently can’t help any more.
Another script that does this job is rmdupe. From the author’s page:
rmdupe uses standard linux commands to search within specified folders for duplicate files, regardless of filename or extension. Before duplicate candidates are removed they are compared byte-for-byte. rmdupe can also check duplicates against one or more reference folders, can trash files instead of removing them, allows for a custom removal command, and can limit its search to files of specified size. rmdupe includes a simulation mode which reports what will be done for a given command without actually removing any files.
I use komparator — sudo apt-get install komparator (Ubuntu 10.04+ ) — as GUI-tool for finding duplicates in manual mode.
For Music related duplicate identification and deletion, Picard (open source) by http://musicbrainz.org/ and Jaikoz (privative) are the best solutions. Jaikoz I believe automatically tags your music based on the data of the song file. You don’t even need the name of the song for it to identify the song and assign all metadata to it. Although the free version can tag only a limited number of songs in one run, but you can run it as many times as you want.
dupeGuru has a dedicated mode for music. It is a cross-platform GUI program and, as of today (February 2021), it is in active development, although it is unclear which releases work on which systems. Check its documentation.
Now that fslint is no longer supported, I’ve switched to fclones. As requested, it matches by hash, and can output a list, or replace files with hard or soft links.
I’ve been using it like this to replace duplicate files with hard links:
fclones group | fclones link jdupes
I found jdupes very easy and extremely fast.
jdupes is a program for identifying and taking actions upon duplicate files such as deleting, hard linking, symlinking, and block-level deduplication (also known as «dedupe» or «reflink»). It is faster than most other duplicate scanners. It prioritizes data safety over performance while also giving expert users access to advanced (and sometimes dangerous) features.
# Search a single directory: jdupes path/to/directory # Search multiple directories: jdupes directory1 directory2 # Search all directories recursively: jdupes --recurse path/to/directory # Search directory recursively and let user choose files to preserve: jdupes --delete --recurse path/to/directory # Search multiple directories and follow subdirectores under directory2, not directory1: jdupes directory1 --recurse: directory2 # Search multiple directories and keep the directory order in result: jdupes -O directory1 directory2 directory3 # EXclude files over 1M, sumarize info, recursive jdupes -X size+=:1000k --summarize --recurse ~ How to Find Duplicate Files in Linux and Remove Them

If you have this habit of downloading everything from the web like me, you will end up having multiple duplicate files. Most often, I can find the same songs or a bunch of images in different directories or end up backing up some files at two different places. It’s a pain locating these duplicate files manually and deleting them to recover the disk space.
If you want to save yourself from this pain, there are various Linux applications that will help you in locating these duplicate files and removing them. In this article, we will cover how you can find and remove these files in Ubuntu.
Note: You should know what you are doing. If you are using a new tool, it’s always better to try it in a virtual directory structure to figure out what it does before taking it to root or home folder. Also, it’s always better to backup your Linux system!
FSlint: GUI tool to find and remove duplicate files
FSlint helps you search and remove duplicate files, empty directories or files with incorrect names. It has a command-line as well as GUI mode with a set of tools to perform a variety of tasks.
To install FSlint, type the below command in Terminal.
Open FSlint from the Dash search.
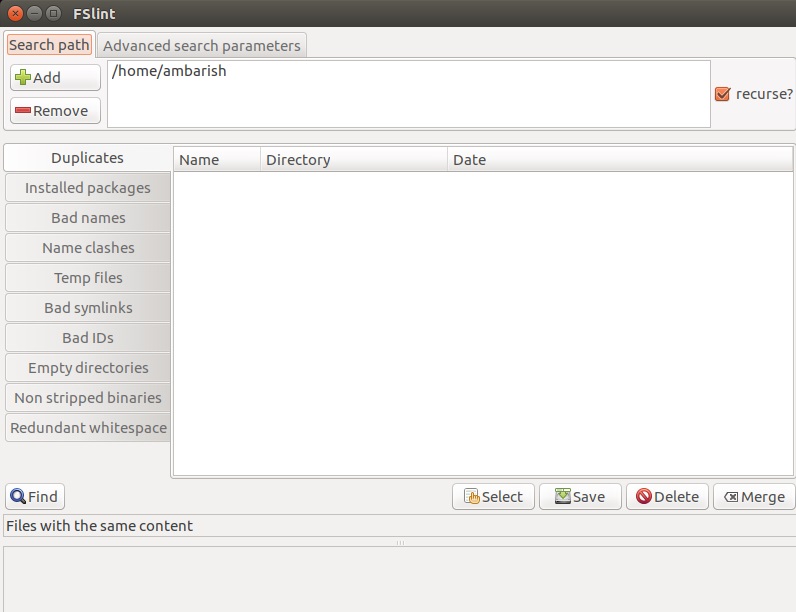
FSlint includes a number of options to choose from. There are options to find duplicate files, installed packages, bad names, name clashes, temp files, empty directories etc. Choose the Search Path and the task which you want to perform from the left panel and click on Find to locate the files. Once done, you can select the files you want to remove and Delete it.
You can click on any file directory from the search result to open it if you are not sure and want to double check it before deleting it.
You can select Advanced search parameters where you can define rules to exclude certain file types or exclude directories which you don’t want to search.
FDUPES: CLI tool to find and remove duplicate files
FDUPES is a command line utility to find and remove duplicate files in Linux. It can list out the duplicate files in a particular folder or recursively within a folder. It asks which file to preserve before deletion and the noprompt option lets you delete all the duplicate files keeping the first one without asking you.
Installation on Debian / Ubuntu
Installation on Fedora
Once installed, you can search duplicate files using the below command:
For recursively searching within a folder, use -r option
This will only list the duplicate files and do not delete them by itself. You can manually delete the duplicate files or use -d option to delete them.
This won’t delete anything on its own but will display all the duplicate files and gives you an option to either delete files one by one or select a range to delete it. If you want to delete all files without asking and preserving the first one, you can use the noprompt -N option.
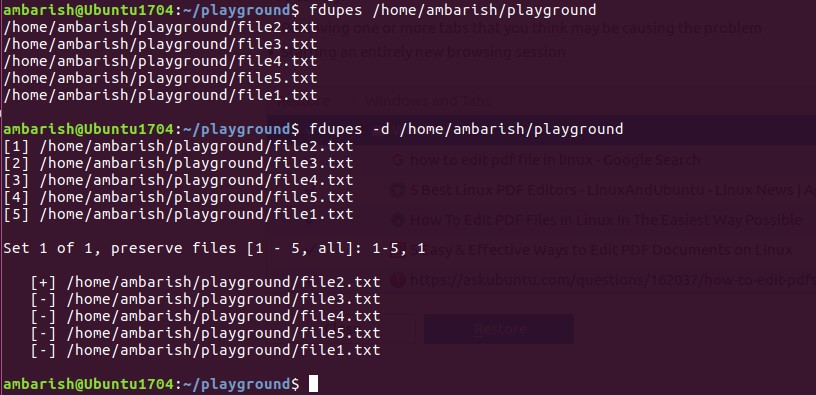
In the above screenshot, you can see the -d command showing all the duplicate files within the folder and asking you to select the file which you want to preserve.
Final Words
There are many other ways and tools to find and delete duplicate files in Linux. Personally, I prefer the FDUPES command line tool; it’s simple and takes no resources.
How do you deal with the finding and removing duplicate files in your Linux system? Do tell us in the comment section.