- How do I determine the total size of a directory (folder) from the command line?
- Get total size of a list of files in UNIX
- 6 Answers 6
- Размер файла в Linux
- Размер файла в Linux
- 1. Nautilus
- 2. Команда ls
- 3. Утилита stat
- 4. Утилита du
- 5. Утилита ncdu
- 6. Утилита find
- Выводы
- Calculate size of files in shell
- 15 Answers 15
How do I determine the total size of a directory (folder) from the command line?
The -h flag on sort will consider «Human Readable» size values.
If want to avoid recursively listing all files and directories, you can supply the —max-depth parameter to limit how many items are displayed. Most commonly, —max-depth=1
du -h --max-depth=1 /path/to/directory I use du -sh or DOOSH as a way to remember it (NOTE: the command is the same, just the organization of commandline flags for memory purposes)
There is a useful option to du called the —apparent-size. It can be used to find the actual size of a file or directory (as opposed to its footprint on the disk) eg, a text file with just 4 characters will occupy about 6 bytes, but will still show up as taking up ~4K in a regular du -sh output. However, if you pass the —apparent-size option, the output will be 6. man du says: —apparent-size print apparent sizes, rather than disk usage; although the apparent size is usually smaller, it may be larger due to holes in (‘sparse’) files, internal fragmentation, indirect blocks
This works for OS X too! Thanks, I was really looking for a way to clear up files, both on my local machine, and my server, but automated methods seemed not to work. So, I ran du -hs * and went into the largest directory and found out which files were so large. This is such a good method, and the best part is you don’t have to install anything! Definitely deserved my upvote
@BandaMuhammadAlHelal I think there are two reasons: rounding ( du has somewhat peculiar rounding, showing no decimals if the value has more than one digit in the chosen unit), and the classical 1024 vs. 1000 prefix issue. du has an option -B (or —block-size ) to change the units in which it displays values, or you could use -b instead of -h to get the «raw» value in bytes.
Get total size of a list of files in UNIX
I want to run a find command that will find a certain list of files and then iterate through that list of files to run some operations. I also want to find the total size of all the files in that list. I’d like to make the list of files FIRST, then do the other operations. Is there an easy way I can report just the total size of all the files in the list? In essence I am trying to find a one-liner for the ‘total_size’ variable in the code snippet below:
#!/bin/bash loc_to_look='/foo/bar/location' file_list=$(find $loc_to_look -type f -name "*.dat" -size +100M) total_size=. echo 'total size of all files is: '$total_size for file in $file_list; do # do a bunch of operations done @fedorqui If her version of find supports -printf . Some form of -exec stat -f ‘%z’ <> \; (depending on your system’s implementation of stat ) would work as well.
Storing a list of file names in a flat string is not recommended anyway, since you can’t cope with file names containing whitespace easily.
6 Answers 6
You should simply be able to pass $file_list to du :
du -ch $file_list | tail -1 | cut -f 1 du will print an entry for each file, followed by the total (with -c ), so we use tail -1 to trim to only the last line and cut -f 1 to trim that line to only the first column.
This is a nice answer, but please remember that du prints actual disk usage rounded up to a multiple of (usually) 4 KB instead of logical file size. for i in <0..9>; do echo -n $i > $i.txt; done; du -ch *.txt => 40K total instead of 10 total .
You’re right, although in this case the ±4KB difference becomes negligible as we’re only dealing with files over 100MB. 😉
Also, check your version of du . If you are using GNU tools, you might be able to add —apparent-size to the du options to get the same size listing that ls displays.
What if the files name in the $files_list contain space? I’ve tried escaping space with \ but no luck.
Methods explained here have hidden bug. When file list is long, then it exceeds limit of shell comand size. Better use this one using du:
find -print0 | du --files0-from=- --total -s|tail -1 find produces null ended file list, du takes it from stdin and counts. this is independent of shell command size limit. Of course, you can add to du some switches to get logical file size, because by default du told you how physical much space files will take.
But I think it is not question for programmers, but for unix admins 🙂 then for stackoverflow this is out of topic.
We can remove -print0 and —files0-from=- and replace them with a call to xargs , e.g. find . | xargs du .
with xargs it calls du command many times, then it will be much slower, and will higher utilizes resources. otherwise, it will not prevent properly run, when any file name will contain any new line character. then find with xargs should have ‘null end’ option, for xargs it will be —null or -0 (numerical zero) switch.
Is there any way to do this without -print0 ? I have files.txt all over my file system that I generate with newline instead of null termination. Usually I use xargs -d’\n’ but I can’t get du to sum the sizes which is frustrating.
This code adds up all the bytes from the trusty ls for all files (it excludes all directories. apparently they’re 8kb per folder/directory)
cd /; find -type f -exec ls -s \; | awk ' END ' Note: Execute as root. Result in megabytes.
The problem with du is that it adds up the size of the directory nodes as well. It is an issue when you want to sum up only the file sizes. (Btw., I feel strange that du has no option for ignoring the directories.)
In order to add the size of files under the current directory (recursively), I use the following command:
ls -laUR | grep -e "^\-" | tr -s " " | cut -d " " -f5 | awk ' END ' How it works: it lists all the files recursively ( «R» ), including the hidden files ( «a» ) showing their file size ( «l» ) and without ordering them ( «U» ). (This can be a thing when you have many files in the directories.) Then, we keep only the lines that start with «-» (these are the regular files, so we ignore directories and other stuffs). Then we merge the subsequent spaces into one so that the lines of the tabular aligned output of ls becomes a single-space-separated list of fields in each line. Then we cut the 5th field of each line, which stores the file size. The awk script sums these values up into the sum variable and prints the results.
Размер файла в Linux
В этой небольшой статье мы поговорим о том, как узнать размер файла в Linux с помощью различных утилит. Проще всего узнать этот параметр в графическом интерфейсе, но многим часто приходится работать в терминале и надо знать как эта задача решается там.
Вы узнаете как посмотреть размер файла через файловый менеджер, утилиту ls, а также du. Об этих утилитах у нас есть отдельные статьи, но эта будет нацелена именно на просмотр размера конкретного файла.
Размер файла в Linux
1. Nautilus
Чтобы посмотреть размер файла в файловом менеджере сначала найдите нужный файл и кликните по нему правой кнопкой мыши. В открывшемся меню выберите Свойства:
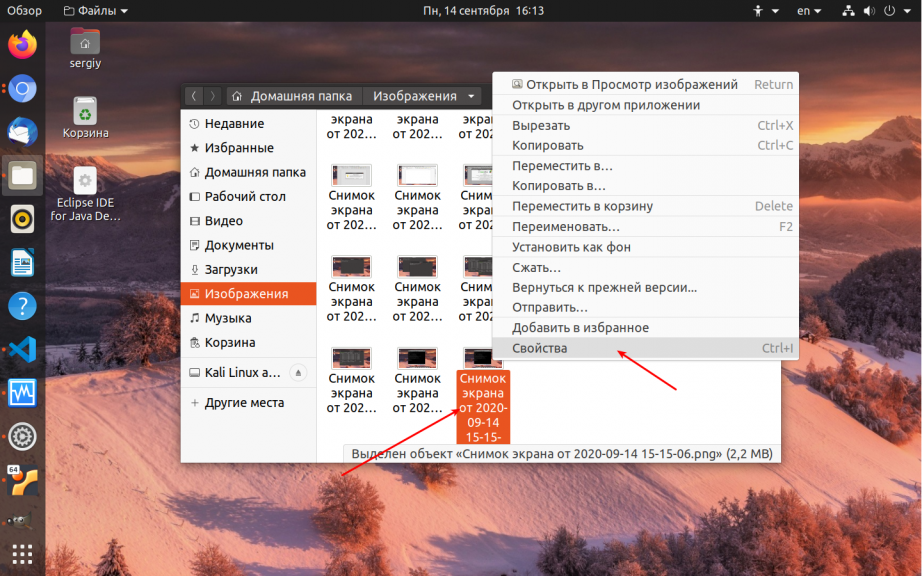
Программа откроет окно, в котором будут указаны свойства файла, среди них будет и размер:
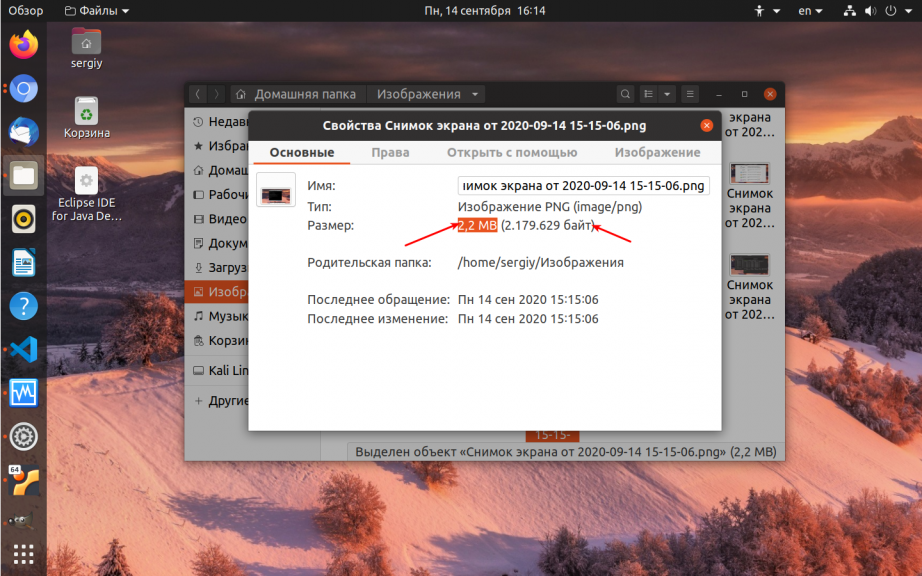
2. Команда ls
Для того чтобы утилита ls отображала размер файлов в удобном для чтения формате необходимо использовать параметр -h. Например:
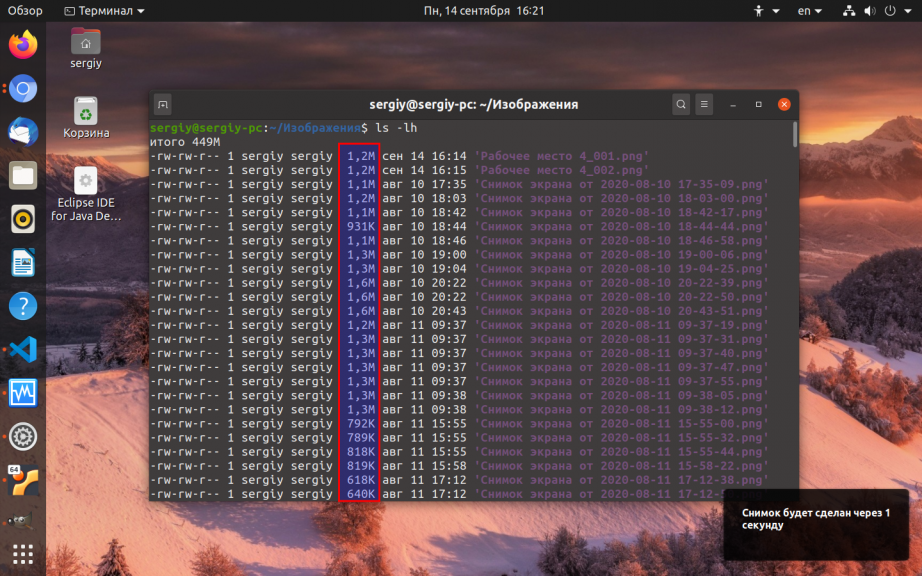
Здесь размер отображается в пятой колонке. Чтобы увидеть размер определённого файла надо передать его имя утилите:
ls -lh ‘Снимок экрана от 2020-08-10 20-22-50.png’
Можно ещё вручную указать единицы измерения для показа размера. Для этого используйте опцию —block-size. Например, мегабайты:
Вместо ls можно использовать команду ll, её вывод полностью аналогичен команде ls -l:
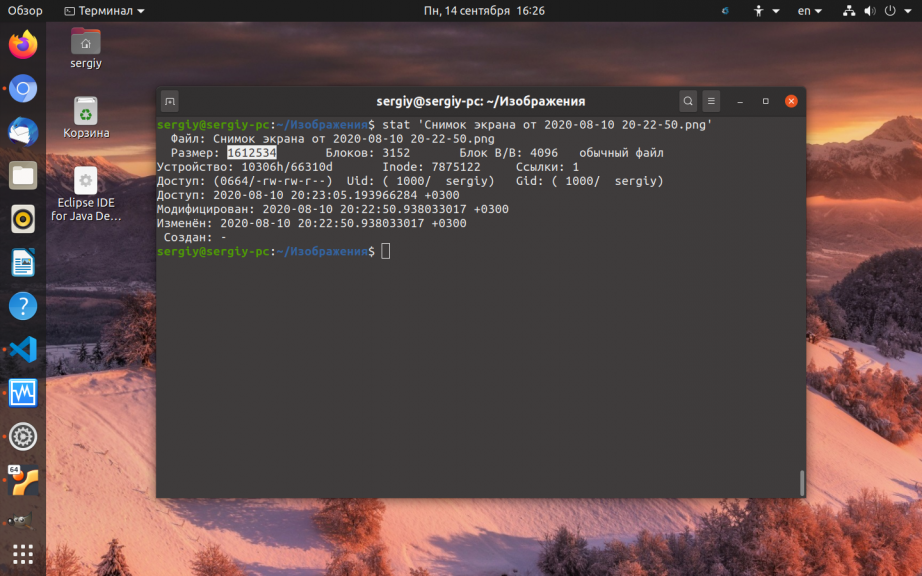
3. Утилита stat
Программа stat кроме метаданных позволяет выводить размер файла в байтах. Например:
stat ‘Снимок экрана от 2020-08-10 20-22-50.png’
Если нужно показать только размер, используйте опцию -с с указанием формата %s:
stat -c %s ‘Снимок экрана от 2020-08-10 20-22-50.png’
4. Утилита du
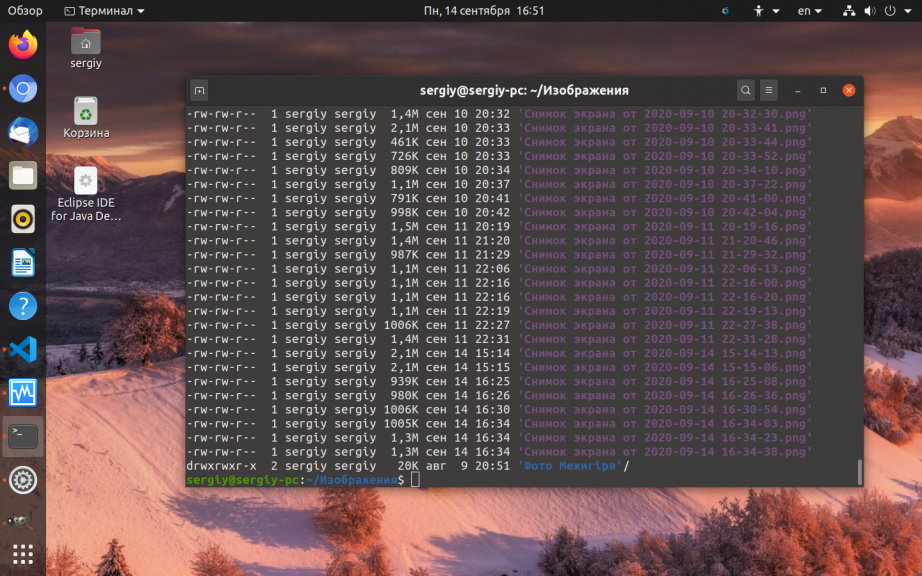
Программа du специально предназначена для просмотра размера файлов в папке. Вы можете просмотреть размер конкретного файла, например:
du -h ‘Снимок экрана от 2020-08-10 20-22-50.png’
Опция -h включает вывод размера в удобном для чтения формате. Если вы хотите посмотреть размеры для всех файлов в папке, просто передайте путь к папке:
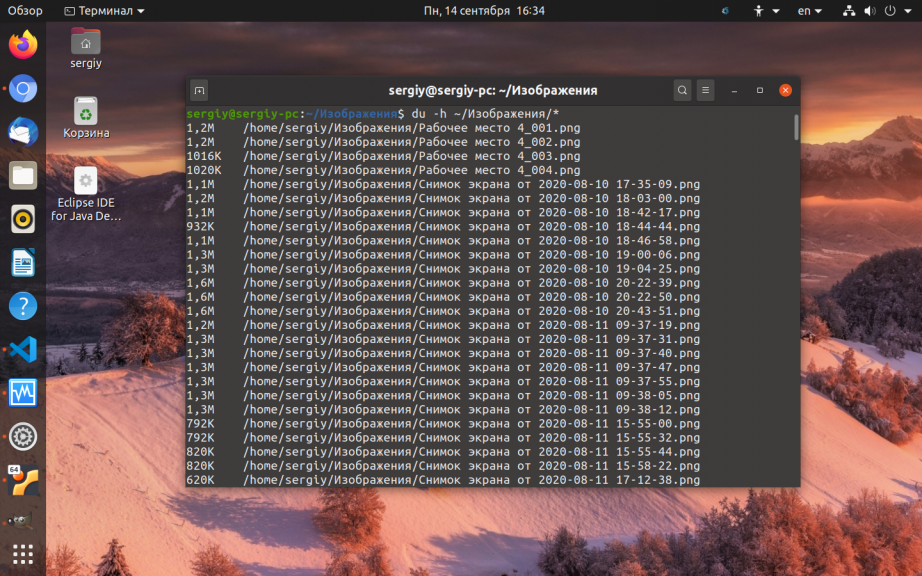
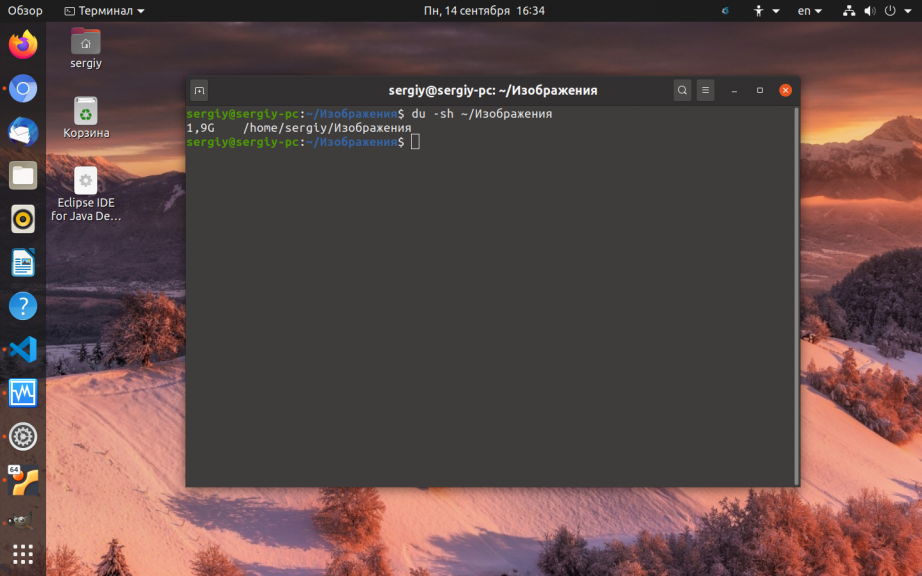
А чтобы узнать размер папки в Linux используйте опцию -s. Она суммирует размеры всех объектов:
5. Утилита ncdu
Программа ncdu позволяет анализировать дисковое пространство занимаемое файлами и каталогами. Но она не поставляется вместе с системой. Для её установки выполните:
Затем просто укажите в параметрах каталог, размер которого вы хотите посмотреть:
Все файлы будут отсортированы по размеру, а в самом низу будет отображен общий размер этой папки:
6. Утилита find
С помощью этой утилиты вы не можете узнать размер файла, зато можете найти файлы с определённым размером. С помощью параметра size можно указать границы размера файлов, которые надо найти. Например, больше чем 2000 килобайт, но меньше чем 2500 килобайт:
find ~/Изображения/ -size +2000k -size -2500k
Размер можно ещё указывать в мегабайтах для этого используйте приставку M, или в байтах, тогда никакой приставки не нужно.
Выводы
В этой небольшой статье мы разобрались как узнать размер файлов linux, а также как посмотреть размер каталога и всех файлов в нём с помощью различных утилит. А какие способы просмотра размера используете вы? Напишите в комментариях!
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.
Calculate size of files in shell
I’m trying to calculate the total size in bytes of all files (in a directory tree) matching a filename pattern just using the shell. This is what I have so far:
find -name *.undo -exec stat -c%s <> \; | awk ‘ END ‘
Is there an easier way to do this? I feel like there should be a simple du or find switch that does this for me but I can’t find one. To be clear I want to total files matching a pattern anywhere under a directory tree which means
15 Answers 15
find . -name "*.undo" -ls | awk ' END ' On my system the size of the file is the seventh field in the find -ls output. If your find … -ls output is different, adjust.
In this version, using the existing directory information (file size) and the built-in ls feature of find should be efficient, avoiding process creations or file i/o.
I would add «-type f» to the find command to prevent from incorrect total if there are directories matching «*.undo» glob.
Note that if you need several patterns to match, you will have to use escaped parenthesis for the whole expression to match otherwise the -ls will apply only to the last pattern. For instance, if you want to match all jpeg and png files (trusting filenames), you would use find . \( -iname «*.jpg» -o -iname «*.jpeg» -o -iname «*.png» \) -ls | awk ‘