Find duplicate files
Is it possible to find duplicate files on my disk which are bit to bit identical but have different file-names?
As already mentioned, just finding duplicates and reporting them is not that hard and can be done with for instance fdupes or fslint. What is hard is to take action and clean up files based on that information. So say that the program reports that /home/yourname/vacation/london/img123.jpg and /home/yourname/camera_pictures/vacation/img123.jpg are identical. Which of those should you choose to keep and which one should you delete? To answer that question you need to consider all the other files in those two directories.
(continuing) Does . /camera_pictures/vacation contain all pictures from London and . /vacation/london was just a subset you showed to your neighbour? Or are all files in the london directory also present in the vacation directory? What I have really wanted for many years is a two pane file manager which could take file duplicate information as input to open the respective directories and show/mark which files are identical/different/unique. That would be a power tool.
13 Answers 13
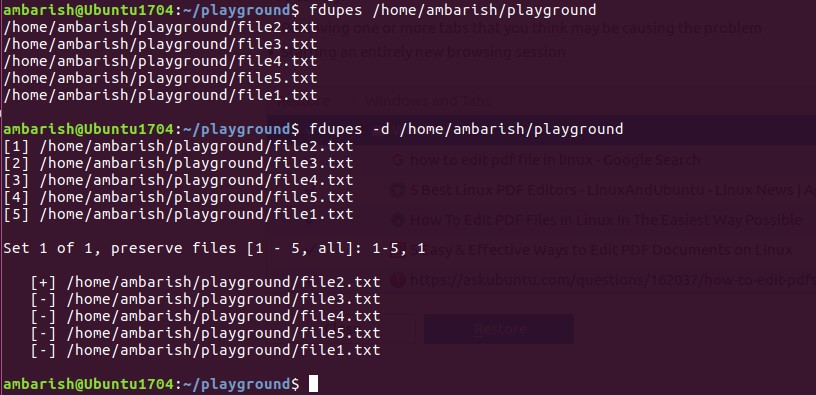
fdupes can do this. From man fdupes :
Searches the given path for duplicate files. Such files are found by comparing file sizes and MD5 signatures, followed by a byte-by-byte comparison.
In Debian or Ubuntu, you can install it with apt-get install fdupes . In Fedora/Red Hat/CentOS, you can install it with yum install fdupes . On Arch Linux you can use pacman -S fdupes , and on Gentoo, emerge fdupes .
To run a check descending from your filesystem root, which will likely take a significant amount of time and memory, use something like fdupes -r / .
As asked in the comments, you can get the largest duplicates by doing the following:
This will break if your filenames contain newlines.
@student: use something along the line of (make sure fdupes just outputs the filenames with no extra informatinos, or cut or sed to just keep that) : fdupes . | xargs ls -alhd | egrep ‘M |G ‘ to keep files in Human readable format and only those with size in Megabytes or Gigabytes. Change the command to suit the real outputs.
@OlivierDulac You should never parse ls. Usually it’s worse than your use case, but even in your use case, you risk false positives.
@ChrisDown: it’s true it’s a bad habit, and can give false positives. But in that case (interactive use, and for display only, no «rm» or anything of the sort directly relying on it) it’s fine and quick ^^ . I love those pages you link to, btw (been reading them since a few months, and full of many usefull infos)
fslint is a toolset to find various problems with filesystems, including duplicate files and problematic filenames etc.
Individual command line tools are available in addition to the GUI and to access them, one can change to, or add to $PATH the /usr/share/fslint/fslint directory on a standard install. Each of these commands in that directory have a —help option which further details its parameters.
findup - find DUPlicate files On debian-based systems, youcan install it with:
sudo apt-get install fslint You can also do this manually if you don’t want to or cannot install third party tools. The way most such programs work is by calculating file checksums. Files with the same md5sum almost certainly contain exactly the same data. So, you could do something like this:
find / -type f -exec md5sum <> \; > md5sums awk '' md5sums | sort | uniq -d > dupes while read -r d; do echo "---"; grep -- "$d" md5sums | cut -d ' ' -f 2-; done < dupes Sample output (the file names in this example are the same, but it will also work when they are different):
$ while read -r d; do echo "---"; grep -- "$d" md5sums | cut -d ' ' -f 2-; done < dupes --- /usr/src/linux-headers-3.2.0-3-common/include/linux/if_bonding.h /usr/src/linux-headers-3.2.0-4-common/include/linux/if_bonding.h --- /usr/src/linux-headers-3.2.0-3-common/include/linux/route.h /usr/src/linux-headers-3.2.0-4-common/include/linux/route.h --- /usr/src/linux-headers-3.2.0-3-common/include/drm/Kbuild /usr/src/linux-headers-3.2.0-4-common/include/drm/Kbuild --- This will be much slower than the dedicated tools already mentioned, but it will work.
It would be much, much faster to find any files with the same size as another file using st_size , eliminating any that only have one file of this size, and then calculating md5sums only between files with the same st_size .
@ChrisDown yeah, just wanted to keep it simple. What you suggest will greatly speed things up of course. That's why I have the disclaimer about it being slow at the end of my answer.
It can be run on macOS, but you should replace md5sum <> with md5 -q <> and gawk '
I thought to add a recent enhanced fork of fdupes, jdupes, which promises to be faster and more feature rich than fdupes (e.g. size filter):
jdupes . -rS -X size-:50m > myjdups.txt This will recursively find duplicated files bigger than 50MB in the current directory and output the resulted list in myjdups.txt.
Note, the output is not sorted by size and since it appears not to be build in, I have adapted @Chris_Down answer above to achieve this:
jdupes -r . -X size-:50m | < while IFS= read -r file; do [[ $file ]] && du "$file" done >| sort -n > myjdups_sorted.txt Note: the latest version of jdupes supports matching files with only a partial hash instead of waiting to hash the whole thing. Very useful. (You have to clone the git archive to get it.) Here are the option I'm using right now: jdupes -r -T -T --exclude=size-:50m --nohidden
Longer version: have a look at the wikipedia fdupes entry, it sports quite nice list of ready made solutions. Of course you can write your own, it's not that difficult - hashing programs like diff , sha*sum , find , sort and uniq should do the job. You can even put it on one line, and it will still be understandable.
If you believe a hash function (here MD5) is collision-free on your domain:
find $target -type f -exec md5sum '<>' + | sort | uniq --all-repeated --check-chars=32 \ | cut --characters=35- Want identical file names grouped? Write a simple script not_uniq.sh to format output:
#!/bin/bash last_checksum=0 while read line; do checksum=$ filename=$ if [ $checksum == $last_checksum ]; then if [ $ != '0' ]; then echo $last_filename unset last_filename fi echo $filename else if [ $ == '0' ]; then echo "====== mt24">)" data-controller="se-share-sheet" data-se-share-sheet-title="Share a link to this answer" data-se-share-sheet-subtitle="" data-se-share-sheet-post-type="answer" data-se-share-sheet-social="facebook twitter " data-se-share-sheet-location="2" data-se-share-sheet-license-url="https%3a%2f%2fcreativecommons.org%2flicenses%2fby-sa%2f3.0%2f" data-se-share-sheet-license-name="CC BY-SA 3.0" data-s-popover-placement="bottom-start">Share)" title="">Improve this answer)">edited Feb 21, 2017 at 18:15 Wayne Werner11.4k8 gold badges29 silver badges42 bronze badgesanswered Apr 13, 2013 at 15:39 reithreith3842 silver badges10 bronze badges