- How to download a website page on Linux terminal?
- Wget
- Check if wget already available
- cURL
- Check if cURL already available
- How to download an HTML file as plain text? [duplicate]
- 2 Answers 2
- How to Open HTML File From a Terminal?
- Method 1: Open HTML File in Browser
- Using open Command
- Syntax:
- Using a Browser
- Method 2: Open HTML File Using lynx
- Syntax:
- Bonus Tip: How to Edit the Content of the HTML File?
- Syntax:
- Conclusion
- How can I run a html file from terminal? [closed]
- 9 Answers 9
How to download a website page on Linux terminal?
The Linux command line provides greta features for web crawling in addition to its inherent capabilities to handle web servers and web browsing. In this article we will check for few tools which are wither available or can be installed and used in the Linux environment for offline web browsing. This is achieved by basically downloading the webpage or many webpages.
Wget
Wget is probably the most famous one among all the downloading options. It allows downloading from http, https, as well as FTP servers. It can download the entire website and also allows proxy browsing.
Below are the steps to get it installed and start using it.
Check if wget already available
ubuntu@ubuntu:~$ which wget ; echo $?
Running the above code gives us the following result:
If the exit code($?) is 1 then we runt he below command to install wget.
ubuntu@ubuntu:~$ sudo apt-get install wget
Now we run the wget command for a specific webpage or a website to be downloaded.
#Downlaod a webpage wget https://en.wikipedia.org/wiki/Linux_distribution # Download entire website wget abc.com
Running the above code gives us the following result. We show the result only for the web page and not the whole website. Thee downloaded file gets saved in the current directory.
ubuntu@ubuntu:~$ wget https://en.wikipedia.org/wiki/Linux_distribution --2019-12-29 23:31:41-- https://en.wikipedia.org/wiki/Linux_distribution Resolving en.wikipedia.org (en.wikipedia.org). 103.102.166.224, 2001:df2:e500:ed1a::1 Connecting to en.wikipedia.org (en.wikipedia.org)|103.102.166.224|:443. connected. HTTP request sent, awaiting response. 200 OK Length: 216878 (212K) [text/html] Saving to: ‘Linux_distribution’ Linux_distribution 100%[===================>] 211.79K 1.00MB/s in 0.2s 2019-12-29 23:31:42 (1.00 MB/s) - ‘Linux_distribution’ saved [216878/216878]
cURL
cURL is a client side application. It supports downloading files from http, https,FTP,FTPS, Telnet, IMAP etc. It has additional support for different types of downloads as compared to wget.
Below are the steps to get it installed and start using it.
Check if cURL already available
ubuntu@ubuntu:~$ which cURL ; echo $?
Running the above code gives us the following result:
The value of 1 indicates cURL is not available in the system. So we will install it using the below command.
ubuntu@ubuntu:~$ sudo apt-get install curl
Running the above code gives us the following result indicating the installation of cURL.
[sudo] password for ubuntu: Reading package lists. Done …. Get:1 http://us.archive.ubuntu.com/ubuntu xenial-updates/main amd64 curl amd64 7.47.0-1ubuntu2.14 [139 kB] Fetched 139 kB in 21s (6,518 B/s) ……. Setting up curl (7.47.0-1ubuntu2.14) .
Next we user cURL to download a webpage.
curl -O https://en.wikipedia.org/wiki/Linux_distribution
Running the above code gives us the following result. You can locate the downloaded in the current working directory.
% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 211k 100 211k 0 0 312k 0 --:--:-- --:--:-- --:--:-- 311k
How to download an HTML file as plain text? [duplicate]
If one downloads a webpage with curl or wget it comes down as html. But if I wish to download it as plain text (i.e. no HTML parsing whatsoever), exactly or almost exactly as it would be plainly read in a web browser (with any image/video/audio omitted of course), what would be a way to do that?
Since the question is different, no. It might have data that would have prevented me to ask the current question.
A question doesn’t have to be identical in every respect to be a duplicate. You’re expected to read and understand and extrapolate, then apply what you’ve learned to your specific situation. The linked question is similar enough to yours to be a dupe.
2 Answers 2
you can’t download that, it doesn’t exist on the server. The server sends the HTML, the browser’s job is to display it. And part of that (can be) is showing the text.
In fact, many web pages are rather empty, and load the relevant content as you read along.
So, what you’ll need is a working browser, which displays your text, then you need to get that text.
You’d usually do that by actually remote-controlling a browser from a scripting language: you start the browser in a special «daemon» mode, you connect to it, and using a specially crafted browser control interface (WebDriver) you tell it to go to a URL, wait a second to let the browser render what you’d see on screen, normally, and then tell it to save as a plain text file.
How to Open HTML File From a Terminal?
Html file is a combination of symbols and text which displays the content of the web page. These files have .html extensions. In Linux, various methods exist to open Html files using the terminal or a graphical user interface. In this post, you will learn how to open Html files using the terminal in Linux. The content of the post is:
Method 1: Open HTML File in Browser
In Linux, you can open any Html file in your browser. There are two ways available for opening any Html file through the terminal. Let’s discuss these two functions one by one.
Using open Command
The “open” is a built-in utility to open any files or directories in Linux. The syntax to open any file using the “open” command is given below:
Syntax:
Write the “open” keyword and then type your Html file name.
Let’s move and check how it works. We have an index.html file in our home directory, which can be seen below:

Let’s open it in the browser using the “open command”.
To open any Html file using the “open” command is obtained as follows:

After executing the above command, it will automatically open the Html in your browser:
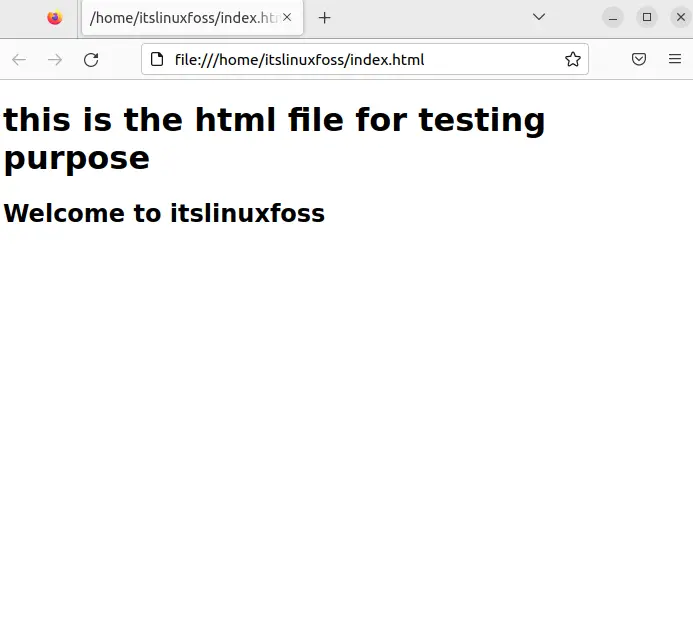
The index.html file is opened in the Firefox browser.
Using a Browser
You can open any Html file using a browser as well, and for that, you need to follow the below-mentioned syntax:
Type any browser name and then type your Html file name.
To open any Html file using the browser name, execute the following command in the terminal:
Once the above command is executed, the file will be opened in the browser. In our scenario, we have opened it in the chromium browser as shown in the below image:
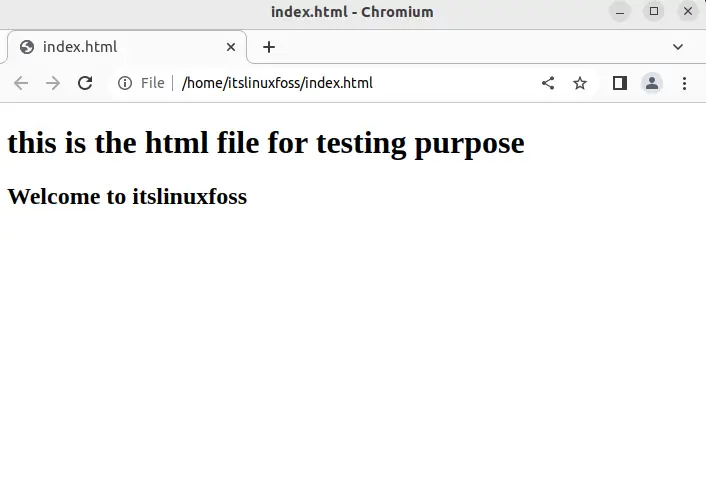
The index.html file has been opened in the chromium browser.
Note: You can also use the bash script to open Html files in the browser. Just type in the bash script file and save it:
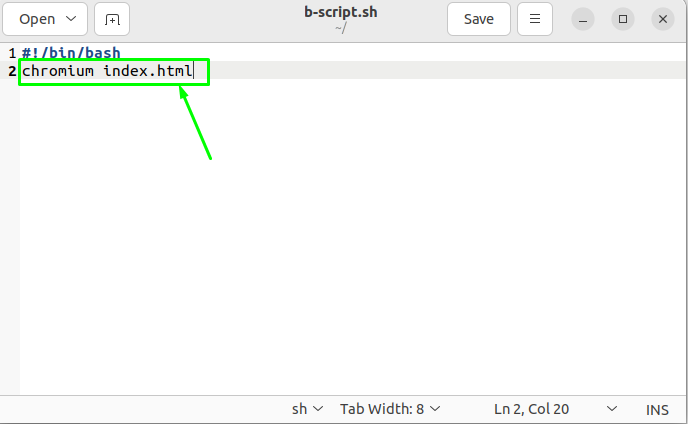
Once you save it, run the bash script file in the terminal:
The execution of the above command will give you the same output.
Let’s move towards method 2 to open Html files.
Method 2: Open HTML File Using lynx
Another method that can be used to open an Html file is using the “lynx”. “lynx” is a terminal-based web browser that prints the output of the file as plain text in the terminal. In simple words, it’s a non-graphical web browser that shows the web pages on the terminal. It is not pre-installed in Linux distributions; user can install it manually by executing the below command:
For Ubuntu/Debian:
For Fedora/CentOS/RHEL:
The syntax for using the “lynx” is shown below:
Syntax:
Type the “lynx” keyword, “options” for different modes and then file name.
To open an HTML file using “lynx”, use the “dump” option. “dump” option represents the standard output (stdout). Run the following command to see the results:

The content of the Html has been displayed as plain text.
Note: lynx will only print the Html content of the file. However, if you put any javascript content in an Html file, the javascript content will not be printed.
Using lynx, users can also open the Html file in its editor. To do so, use the lynx without option:

Once you type the command, press Enter:

An Html file is opened in the lynx text editor.
These are the possible methods to open an Html file using the terminal.
Bonus Tip: How to Edit the Content of the HTML File?
There are different commands available to open and edit the files in the text editor, such as pico, nano, vi, and much more. In our case, we are using the “nano” editor to open the Html file. The syntax for the nano editor command is shown below:
Syntax:
Write the “nano” keyword and then type the file name.
To open any Html file using the “nano” command is obtained as follows:
Once you execute the above command, it will open the Html file in the nano text editor from where you can edit the content of that HTML file.
Conclusion
To open any HTML file using the terminal, there are three methods. The first method is to open an HTML file in the browser using the “open” command or use any browser name along with the file name. The second method is to open an HTML file in text editors such as nano, while the third is to open an HTML file using lynx. This post has demonstrated all the possible ways to open an HTML file through a terminal in Linux.
How can I run a html file from terminal? [closed]
Closed. This question does not meet Stack Overflow guidelines. It is not currently accepting answers.
This question does not appear to be about a specific programming problem, a software algorithm, or software tools primarily used by programmers. If you believe the question would be on-topic on another Stack Exchange site, you can leave a comment to explain where the question may be able to be answered.
KIRIM SMS GRATIS
Nomer HP:
Isi Pesan:
as you can see when the file is loaded it automatically clicks the submit button, and redirects it to http://xxxxxx how can I run this html file from terminal? I’m using this on openwrt with webserver installed on it.
Start researching headless browsers. Picking one for you and walking you through installing one up is out-of-scope for this site.
Also, you probably don’t want to do this. You should describe your actual problem for us, because writing an entire HTML document with embedded JavaScript for automatically submitting the form, just to programatically issue POST requests from the command line, is the worst solution to that problem. There’s probably a one-line CURL command that can do this for you.
9 Answers 9
For those like me, who have reached this thread because they want to serve an html file from linux terminal or want to view it using a terminal command, use these steps:-
Navigate to the directory containing the html file
If you have chrome installed,
google-chrome <filename>.html Navigate to the directory containing the html file
And Simply type the following on the Terminal:-
pushd <filename>.html; python3 -m http.server 9999; popd; Then click the I.P. address 0.0.0.0:9999 OR localhost:9999 (Whatever is the result after executing the above commands). Or type on the terminal :-
Using the second method, anyone else connected to the same network can also view your file by using the URL: 0.0.0.0:9999
Other users in the network can access said webpage if they navigate to